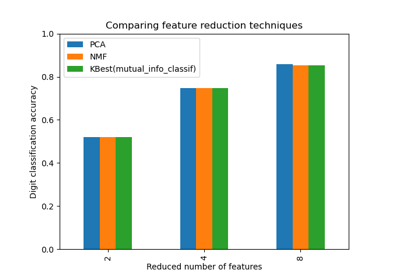
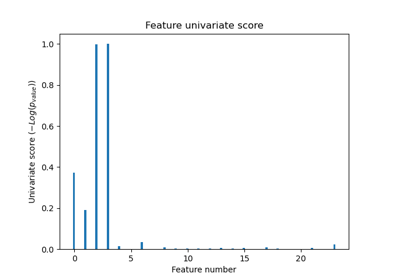
SelectKBest#
- class sklearn.feature_selection.SelectKBest(score_func=<function f_classif>, *, k=10)[source]#
根据 k 个最高分数选择特征。
在用户指南中阅读更多信息。
- 参数:
- score_func可调用对象,默认=f_classif
接受两个数组 X 和 y 的函数,返回一对数组(分数,p值)或一个包含分数的单一数组。默认值为 f_classif(参见下方“另请参见”)。默认函数仅适用于分类任务。
0.18 版本新增。
- k整型或“all”,默认=10
要选择的最高特征数量。“all”选项绕过选择,用于参数搜索。
- 属性:
另请参见
f_classif分类任务中标签/特征之间的 ANOVA F 值。
mutual_info_classif离散目标的互信息。
chi2分类任务中非负特征的卡方统计。
f_regression回归任务中标签/特征之间的 F 值。
mutual_info_regression连续目标的互信息。
SelectPercentile根据最高分数的百分位数选择特征。
SelectFpr根据假阳性率测试选择特征。
SelectFdr根据估计的错误发现率选择特征。
SelectFwe根据家族错误率选择特征。
GenericUnivariateSelect具有可配置模式的单变量特征选择器。
注释
得分相等的特征之间的平局将以未指定的方式打破。
此过滤器支持仅请求
X计算分数的无监督特征选择。示例
>>> from sklearn.datasets import load_digits >>> from sklearn.feature_selection import SelectKBest, chi2 >>> X, y = load_digits(return_X_y=True) >>> X.shape (1797, 64) >>> X_new = SelectKBest(chi2, k=20).fit_transform(X, y) >>> X_new.shape (1797, 20)
- fit(X, y=None)[source]#
对 (X, y) 运行评分函数并获取适当的特征。
- 参数:
- X形状为 (n_samples, n_features) 的类数组对象
训练输入样本。
- y形状为 (n_samples,) 的类数组对象或 None
目标值(分类中的类别标签,回归中的实数)。如果选择器是无监督的,则
y可以设置为None。
- 返回:
- self对象
返回实例本身。
- fit_transform(X, y=None, **fit_params)[source]#
拟合数据,然后对其进行转换。
使用可选参数
fit_params将转换器拟合到X和y,并返回X的转换版本。- 参数:
- X形状为 (n_samples, n_features) 的类数组对象
输入样本。
- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组对象,默认=None
目标值(无监督转换时为 None)。
- **fit_params字典
额外的拟合参数。
- 返回:
- X_new形状为 (n_samples, n_features_new) 的 ndarray 数组
转换后的数组。
- get_feature_names_out(input_features=None)[source]#
根据选定的特征遮罩特征名称。
- 参数:
- input_features字符串类数组对象或 None,默认=None
输入特征。
如果
input_features为None,则feature_names_in_用作输入特征名称。如果feature_names_in_未定义,则生成以下输入特征名称:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features是一个类数组对象,则如果feature_names_in_已定义,则input_features必须与feature_names_in_匹配。
- 返回:
- feature_names_out字符串对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deep布尔值,默认=True
如果为 True,将返回此估计器及其包含的作为估计器的子对象的参数。
- 返回:
- params字典
参数名称与其值之间的映射。
- get_support(indices=False)[source]#
获取所选特征的掩码或整数索引。
- 参数:
- indices布尔值,默认=False
如果为 True,返回值将是整数数组,而不是布尔掩码。
- 返回:
- support数组
从特征向量中选择保留特征的索引。如果
indices为 False,则这是一个形状为 [# 输入特征] 的布尔数组,其中一个元素为 True 当且仅当其对应的特征被选择保留。如果indices为 True,则这是一个形状为 [# 输出特征] 的整数数组,其值是输入特征向量的索引。
- inverse_transform(X)[source]#
反转转换操作。
- 参数:
- X形状为 [n_samples, n_selected_features] 的数组
输入样本。
- 返回:
- X_original形状为 [n_samples, n_original_features] 的数组
在
transform移除特征的位置插入零列的X。
- set_output(*, transform=None)[source]#
设置输出容器。
请参阅 set_output API 简介 了解如何使用此 API 的示例。
- 参数:
- transform{“default”, “pandas”, “polars”},默认=None
配置
transform和fit_transform的输出。"default": 转换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 转换配置未改变
1.4 版本新增: 添加了
"polars"选项。
- 返回:
- self估计器实例
估计器实例。