注意
跳转到末尾 下载完整示例代码。或通过 JupyterLite 或 Binder 在浏览器中运行此示例
使用 Pipeline 和 GridSearchCV 选择降维方法#
此示例构建了一个管道,该管道首先进行降维,然后使用支持向量分类器进行预测。它演示了如何在单个交叉验证运行中使用 GridSearchCV 和 Pipeline 对不同类别的估计器进行优化——在网格搜索过程中,将无监督的 PCA 和 NMF 降维方法与单变量特征选择进行了比较。
此外,Pipeline 可以通过 memory 参数进行实例化,以记忆管道中的转换器,避免重复拟合相同的转换器。
请注意,当转换器的拟合成本很高时,使用 memory 启用缓存会变得很有用。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
`Pipeline` 和 `GridSearchCV` 的图示#
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.decomposition import NMF, PCA
from sklearn.feature_selection import SelectKBest, mutual_info_classif
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import LinearSVC
X, y = load_digits(return_X_y=True)
pipe = Pipeline(
[
("scaling", MinMaxScaler()),
# the reduce_dim stage is populated by the param_grid
("reduce_dim", "passthrough"),
("classify", LinearSVC(dual=False, max_iter=10000)),
]
)
N_FEATURES_OPTIONS = [2, 4, 8]
C_OPTIONS = [1, 10, 100, 1000]
param_grid = [
{
"reduce_dim": [PCA(iterated_power=7), NMF(max_iter=1_000)],
"reduce_dim__n_components": N_FEATURES_OPTIONS,
"classify__C": C_OPTIONS,
},
{
"reduce_dim": [SelectKBest(mutual_info_classif)],
"reduce_dim__k": N_FEATURES_OPTIONS,
"classify__C": C_OPTIONS,
},
]
reducer_labels = ["PCA", "NMF", "KBest(mutual_info_classif)"]
grid = GridSearchCV(pipe, n_jobs=1, param_grid=param_grid)
grid.fit(X, y)
GridSearchCV(estimator=Pipeline(steps=[('scaling', MinMaxScaler()),
('reduce_dim', 'passthrough'),
('classify',
LinearSVC(dual=False,
max_iter=10000))]),
n_jobs=1,
param_grid=[{'classify__C': [1, 10, 100, 1000],
'reduce_dim': [PCA(iterated_power=7),
NMF(max_iter=1000)],
'reduce_dim__n_components': [2, 4, 8]},
{'classify__C': [1, 10, 100, 1000],
'reduce_dim': [SelectKBest(score_func=<function mutual_info_classif at 0x7fad23c2c0d0>)],
'reduce_dim__k': [2, 4, 8]}])在 Jupyter 环境中,请重新运行此单元格以显示 HTML 表示或信任此 Notebook。在 GitHub 上,HTML 表示无法渲染,请尝试使用 nbviewer.org 加载此页面。
参数
| estimator | Pipeline(step...iter=10000))]) | |
| param_grid | [{'classify__C': [1, 10, ...], 'reduce_dim': [PCA(iterated_power=7), NMF(max_iter=1000)], 'reduce_dim__n_components': [2, 4, ...]}, {'classify__C': [1, 10, ...], 'reduce_dim': [SelectKBest(s...7fad23c2c0d0>)], 'reduce_dim__k': [2, 4, ...]}] | |
| scoring | None | |
| n_jobs | 1 | |
| refit | True | |
| cv | None | |
| verbose | 0 | |
| pre_dispatch | '2*n_jobs' | |
| error_score | nan | |
| return_train_score | False |
参数
| feature_range | (0, ...) | |
| copy | True | |
| clip | False |
参数
| n_components | 8 | |
| copy | True | |
| whiten | False | |
| svd_solver | 'auto' | |
| tol | 0.0 | |
| iterated_power | 7 | |
| n_oversamples | 10 | |
| power_iteration_normalizer | 'auto' | |
| random_state | None |
参数
| penalty | 'l2' | |
| loss | 'squared_hinge' | |
| dual | False | |
| tol | 0.0001 | |
| C | 1 | |
| multi_class | 'ovr' | |
| fit_intercept | True | |
| intercept_scaling | 1 | |
| class_weight | None | |
| verbose | 0 | |
| random_state | None | |
| max_iter | 10000 |
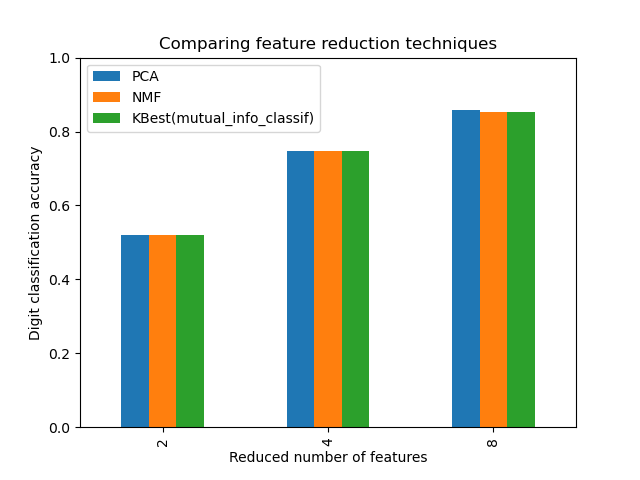
import pandas as pd
mean_scores = np.array(grid.cv_results_["mean_test_score"])
# scores are in the order of param_grid iteration, which is alphabetical
mean_scores = mean_scores.reshape(len(C_OPTIONS), -1, len(N_FEATURES_OPTIONS))
# select score for best C
mean_scores = mean_scores.max(axis=0)
# create a dataframe to ease plotting
mean_scores = pd.DataFrame(
mean_scores.T, index=N_FEATURES_OPTIONS, columns=reducer_labels
)
ax = mean_scores.plot.bar()
ax.set_title("Comparing feature reduction techniques")
ax.set_xlabel("Reduced number of features")
ax.set_ylabel("Digit classification accuracy")
ax.set_ylim((0, 1))
ax.legend(loc="upper left")
plt.show()
在 Pipeline 中缓存转换器#
有时,存储特定转换器的状态是值得的,因为它可以再次使用。在 GridSearchCV 中使用管道会触发这种情况。因此,我们使用 memory 参数来启用缓存。
警告
请注意,此示例仅为说明,因为在此特定情况下,拟合 PCA 不一定比加载缓存慢。因此,当转换器的拟合成本很高时,请使用 memory 构造函数参数。
from shutil import rmtree
from joblib import Memory
# Create a temporary folder to store the transformers of the pipeline
location = "cachedir"
memory = Memory(location=location, verbose=10)
cached_pipe = Pipeline(
[("reduce_dim", PCA()), ("classify", LinearSVC(dual=False, max_iter=10000))],
memory=memory,
)
# This time, a cached pipeline will be used within the grid search
# Delete the temporary cache before exiting
memory.clear(warn=False)
rmtree(location)
PCA 的拟合仅在评估 LinearSVC 分类器 C 参数的第一个配置时计算。 C 的其他配置将触发加载缓存的 PCA 估计器数据,从而节省处理时间。因此,当转换器的拟合成本很高时,使用 memory 缓存管道非常有益。
脚本总运行时间: (0 分钟 40.953 秒)
相关示例