注意
跳到末尾 下载完整示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例
标签传播圈:学习复杂结构#
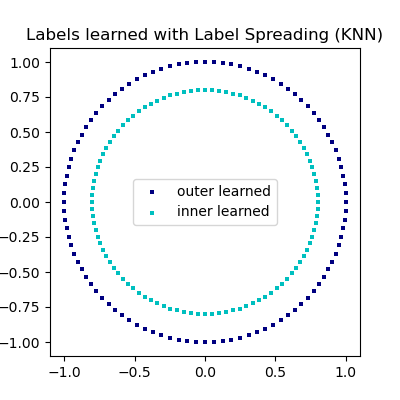
标签传播学习复杂内部结构以演示“流形学习”的示例。外圈应标记为“红色”,内圈应标记为“蓝色”。由于两个标签组都位于各自独特的形状内部,我们可以看到标签在圈中正确传播。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
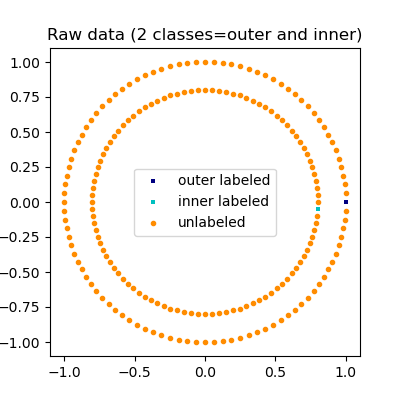
我们生成一个包含两个同心圆的数据集。此外,数据集中的每个样本都关联了一个标签:0(属于外圈)、1(属于内圈)和 -1(未知)。在这里,除了两个标签外,所有标签都被标记为未知。
import numpy as np
from sklearn.datasets import make_circles
n_samples = 200
X, y = make_circles(n_samples=n_samples, shuffle=False)
outer, inner = 0, 1
labels = np.full(n_samples, -1.0)
labels[0] = outer
labels[-1] = inner
绘制原始数据
import matplotlib.pyplot as plt
plt.figure(figsize=(4, 4))
plt.scatter(
X[labels == outer, 0],
X[labels == outer, 1],
color="navy",
marker="s",
lw=0,
label="outer labeled",
s=10,
)
plt.scatter(
X[labels == inner, 0],
X[labels == inner, 1],
color="c",
marker="s",
lw=0,
label="inner labeled",
s=10,
)
plt.scatter(
X[labels == -1, 0],
X[labels == -1, 1],
color="darkorange",
marker=".",
label="unlabeled",
)
plt.legend(scatterpoints=1, shadow=False, loc="center")
_ = plt.title("Raw data (2 classes=outer and inner)")
LabelSpreading 的目标是将标签关联到最初未知的样本。
from sklearn.semi_supervised import LabelSpreading
label_spread = LabelSpreading(kernel="knn", alpha=0.8)
label_spread.fit(X, labels)
现在,我们可以检查当标签未知时,哪些标签已与每个样本关联。
output_labels = label_spread.transduction_
output_label_array = np.asarray(output_labels)
outer_numbers = (output_label_array == outer).nonzero()[0]
inner_numbers = (output_label_array == inner).nonzero()[0]
plt.figure(figsize=(4, 4))
plt.scatter(
X[outer_numbers, 0],
X[outer_numbers, 1],
color="navy",
marker="s",
lw=0,
s=10,
label="outer learned",
)
plt.scatter(
X[inner_numbers, 0],
X[inner_numbers, 1],
color="c",
marker="s",
lw=0,
s=10,
label="inner learned",
)
plt.legend(scatterpoints=1, shadow=False, loc="center")
plt.title("Labels learned with Label Spreading (KNN)")
plt.show()
脚本总运行时间: (0 分钟 0.145 秒)
相关示例