章节导航
__sklearn_is_fitted__
FrozenEstimator
set_output
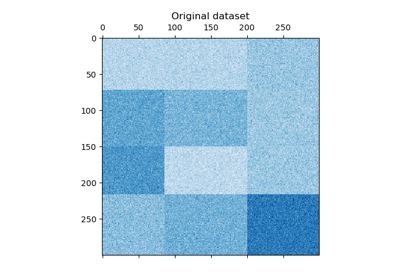
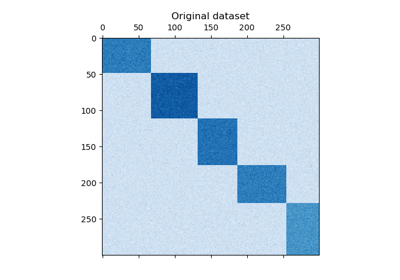
关于双聚类技术的示例。
谱双聚类算法演示
谱协同聚类算法演示
使用谱协同聚类算法对文档进行双聚类