注意
跳到最后下载完整示例代码。或通过JupyterLite或Binder在浏览器中运行此示例
置换重要性与随机森林特征重要性(MDI)#
在本示例中,我们将使用 permutation_importance 在泰坦尼克号数据集上,比较 RandomForestClassifier 的基于杂质的特征重要性与置换重要性。我们将展示基于杂质的特征重要性可能会夸大数值特征的重要性。
此外,随机森林基于杂质的特征重要性存在一个问题,即它是在训练数据集的统计数据上计算的:即使对于那些对目标变量不具预测能力的特征,只要模型有能力利用它们进行过拟合,其重要性也可能很高。
本示例展示了如何使用置换重要性作为一种替代方法,以减轻这些限制。
参考资料
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据加载和特征工程#
我们使用pandas加载泰坦尼克号数据集的副本。以下展示了如何对数值特征和分类特征分别应用预处理。
我们进一步包含两个与目标变量(survived)没有任何关联的随机变量。
random_num是一个高基数数值变量(唯一值数量与记录数量相同)。random_cat是一个低基数分类变量(3个可能的值)。
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
rng = np.random.RandomState(seed=42)
X["random_cat"] = rng.randint(3, size=X.shape[0])
X["random_num"] = rng.randn(X.shape[0])
categorical_columns = ["pclass", "sex", "embarked", "random_cat"]
numerical_columns = ["age", "sibsp", "parch", "fare", "random_num"]
X = X[categorical_columns + numerical_columns]
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
我们定义了一个基于随机森林的预测模型。因此,我们将执行以下预处理步骤:
使用
OrdinalEncoder对分类特征进行编码;使用
SimpleImputer使用均值策略填充数值特征的缺失值。
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OrdinalEncoder
categorical_encoder = OrdinalEncoder(
handle_unknown="use_encoded_value", unknown_value=-1, encoded_missing_value=-1
)
numerical_pipe = SimpleImputer(strategy="mean")
preprocessing = ColumnTransformer(
[
("cat", categorical_encoder, categorical_columns),
("num", numerical_pipe, numerical_columns),
],
verbose_feature_names_out=False,
)
rf = Pipeline(
[
("preprocess", preprocessing),
("classifier", RandomForestClassifier(random_state=42)),
]
)
rf.fit(X_train, y_train)
模型准确性#
在检查特征重要性之前,检查模型的预测性能是否足够高非常重要。毕竟,检查一个非预测模型的特征重要性几乎没有意义。
print(f"RF train accuracy: {rf.score(X_train, y_train):.3f}")
print(f"RF test accuracy: {rf.score(X_test, y_test):.3f}")
RF train accuracy: 1.000
RF test accuracy: 0.814
在这里,可以观察到训练准确率非常高(森林模型有足够的能力完全记住训练集),但由于随机森林内置的袋外(bagging)机制,它仍然能很好地泛化到测试集。
通过限制树的容量(例如,设置 min_samples_leaf=5 或 min_samples_leaf=10),可以在训练集上牺牲一些准确率,以换取测试集上略微更好的准确率,从而限制过拟合,同时不过度引入欠拟合。
然而,我们现在保留我们的高容量随机森林模型,以便我们可以说明关于具有许多唯一值的变量的特征重要性的一些陷阱。
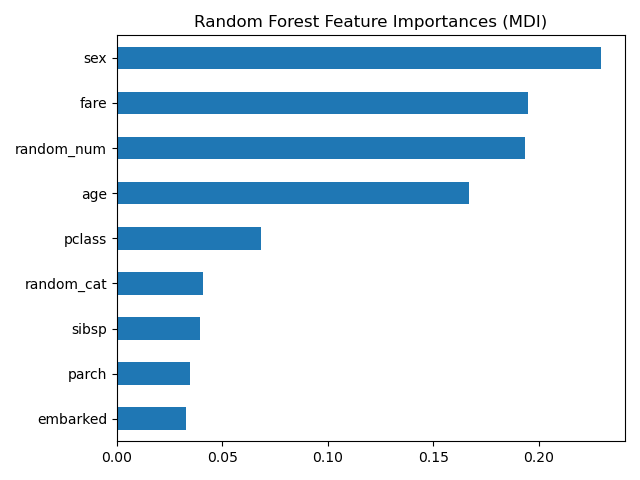
来自平均不纯度下降(MDI)的树特征重要性#
基于杂质的特征重要性将数值特征排在最重要的位置。结果,非预测性的 random_num 变量被列为最重要的特征之一!
这个问题源于基于杂质的特征重要性的两个局限性:
基于杂质的重要性偏向于高基数特征;
基于杂质的重要性是在训练集统计数据上计算的,因此不能反映特征在测试集上做出泛化预测的能力(当模型具有足够容量时)。
偏向高基数特征的偏差解释了为什么 random_num 相比 random_cat 具有非常大的重要性,而我们期望两个随机特征的重要性都为零。
我们使用训练集统计数据这一事实解释了为什么 random_num 和 random_cat 这两个特征都具有非零重要性。
import pandas as pd
feature_names = rf[:-1].get_feature_names_out()
mdi_importances = pd.Series(
rf[-1].feature_importances_, index=feature_names
).sort_values(ascending=True)
ax = mdi_importances.plot.barh()
ax.set_title("Random Forest Feature Importances (MDI)")
ax.figure.tight_layout()
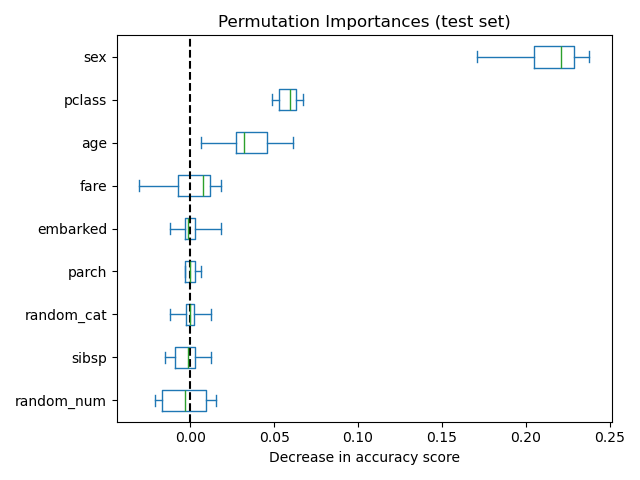
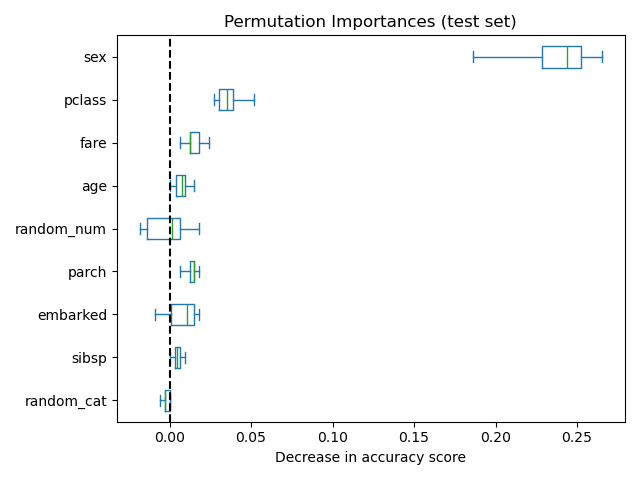
作为替代,rf 的置换重要性是在保留的测试集上计算的。这表明低基数分类特征,sex 和 pclass 是最重要的特征。确实,对这些特征的值进行置换会导致模型在测试集上的准确率得分下降最多。
此外,请注意,两个随机特征的重要性都非常低(接近0),正如预期。
from sklearn.inspection import permutation_importance
result = permutation_importance(
rf, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
sorted_importances_idx = result.importances_mean.argsort()
importances = pd.DataFrame(
result.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
ax = importances.plot.box(vert=False, whis=10)
ax.set_title("Permutation Importances (test set)")
ax.axvline(x=0, color="k", linestyle="--")
ax.set_xlabel("Decrease in accuracy score")
ax.figure.tight_layout()
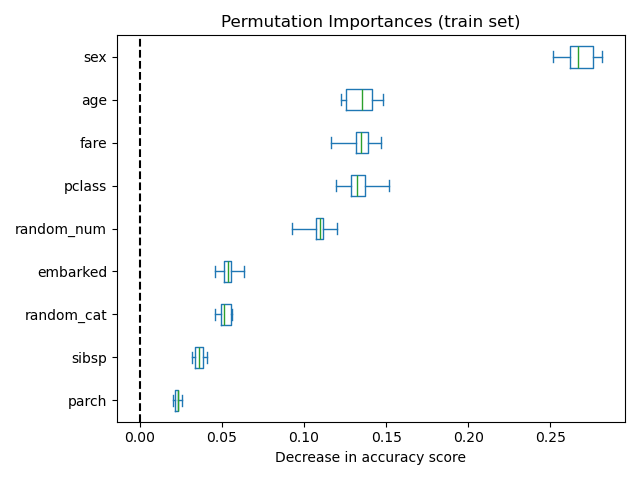
也可以在训练集上计算置换重要性。这表明 random_num 和 random_cat 获得了比在测试集上计算时显著更高的重要性排名。这两个图之间的差异证实了RF模型有足够的能力使用这些随机数值和分类特征进行过拟合。
result = permutation_importance(
rf, X_train, y_train, n_repeats=10, random_state=42, n_jobs=2
)
sorted_importances_idx = result.importances_mean.argsort()
importances = pd.DataFrame(
result.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
ax = importances.plot.box(vert=False, whis=10)
ax.set_title("Permutation Importances (train set)")
ax.axvline(x=0, color="k", linestyle="--")
ax.set_xlabel("Decrease in accuracy score")
ax.figure.tight_layout()
我们可以通过将树的容量限制在 min_samples_leaf 为 20 个数据点来再次尝试实验,以限制过拟合。
rf.set_params(classifier__min_samples_leaf=20).fit(X_train, y_train)
观察训练集和测试集上的准确率分数,我们发现这两个指标现在非常相似。因此,我们的模型不再过拟合。然后我们可以使用这个新模型检查置换重要性。
print(f"RF train accuracy: {rf.score(X_train, y_train):.3f}")
print(f"RF test accuracy: {rf.score(X_test, y_test):.3f}")
RF train accuracy: 0.810
RF test accuracy: 0.832
train_result = permutation_importance(
rf, X_train, y_train, n_repeats=10, random_state=42, n_jobs=2
)
test_results = permutation_importance(
rf, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
sorted_importances_idx = train_result.importances_mean.argsort()
train_importances = pd.DataFrame(
train_result.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
test_importances = pd.DataFrame(
test_results.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
for name, importances in zip(["train", "test"], [train_importances, test_importances]):
ax = importances.plot.box(vert=False, whis=10)
ax.set_title(f"Permutation Importances ({name} set)")
ax.set_xlabel("Decrease in accuracy score")
ax.axvline(x=0, color="k", linestyle="--")
ax.figure.tight_layout()
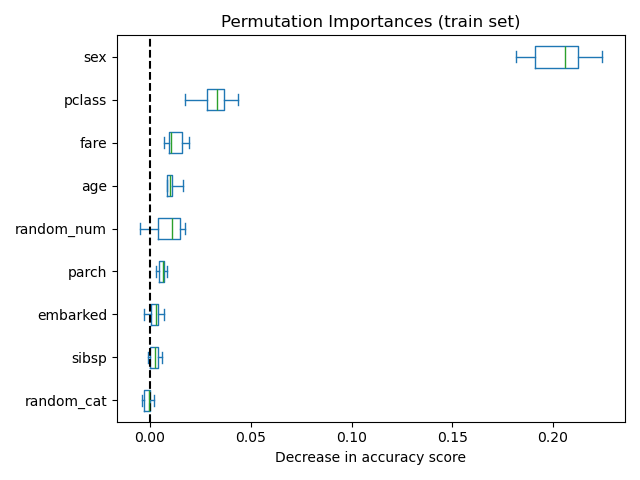
现在,我们可以观察到,在两个集合上,random_num 和 random_cat 特征的重要性低于过拟合随机森林。然而,关于其他特征重要性的结论仍然有效。
脚本总运行时间: (0 分 4.207 秒)
相关示例