注意
转到末尾 下载完整示例代码,或通过JupyterLite或Binder在浏览器中运行此示例
概率校准曲线#
在执行分类时,人们通常不仅希望预测类别标签,还希望预测相关的概率。这个概率提供了某种预测的置信度。本示例演示了如何使用校准曲线(也称为可靠性图)来可视化预测概率的校准程度。此外,还将演示未校准分类器的校准。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据集#
我们将使用一个包含100,000个样本和20个特征的合成二分类数据集。在这20个特征中,只有2个是信息丰富的,10个是冗余的(信息丰富特征的随机组合),其余8个是不提供信息的(随机数)。在这100,000个样本中,1,000个将用于模型拟合,其余用于测试。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(
n_samples=100_000, n_features=20, n_informative=2, n_redundant=10, random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.99, random_state=42
)
校准曲线#
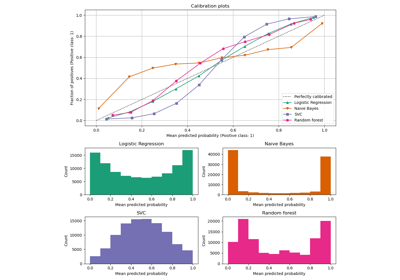
高斯朴素贝叶斯#
首先,我们将比较
LogisticRegression(用作基准,因为经过适当正则化的逻辑回归通常由于使用对数损失而默认校准良好)未校准的
GaussianNBGaussianNB使用保序和S型校准(参见用户指南)
下面绘制了所有4种情况的校准曲线,X轴表示每个bin的平均预测概率,Y轴表示每个bin中正类别的比例。
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
from sklearn.calibration import CalibratedClassifierCV, CalibrationDisplay
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
lr = LogisticRegression(C=1.0)
gnb = GaussianNB()
gnb_isotonic = CalibratedClassifierCV(gnb, cv=2, method="isotonic")
gnb_sigmoid = CalibratedClassifierCV(gnb, cv=2, method="sigmoid")
clf_list = [
(lr, "Logistic"),
(gnb, "Naive Bayes"),
(gnb_isotonic, "Naive Bayes + Isotonic"),
(gnb_sigmoid, "Naive Bayes + Sigmoid"),
]
fig = plt.figure(figsize=(10, 10))
gs = GridSpec(4, 2)
colors = plt.get_cmap("Dark2")
ax_calibration_curve = fig.add_subplot(gs[:2, :2])
calibration_displays = {}
for i, (clf, name) in enumerate(clf_list):
clf.fit(X_train, y_train)
display = CalibrationDisplay.from_estimator(
clf,
X_test,
y_test,
n_bins=10,
name=name,
ax=ax_calibration_curve,
color=colors(i),
)
calibration_displays[name] = display
ax_calibration_curve.grid()
ax_calibration_curve.set_title("Calibration plots (Naive Bayes)")
# Add histogram
grid_positions = [(2, 0), (2, 1), (3, 0), (3, 1)]
for i, (_, name) in enumerate(clf_list):
row, col = grid_positions[i]
ax = fig.add_subplot(gs[row, col])
ax.hist(
calibration_displays[name].y_prob,
range=(0, 1),
bins=10,
label=name,
color=colors(i),
)
ax.set(title=name, xlabel="Mean predicted probability", ylabel="Count")
plt.tight_layout()
plt.show()
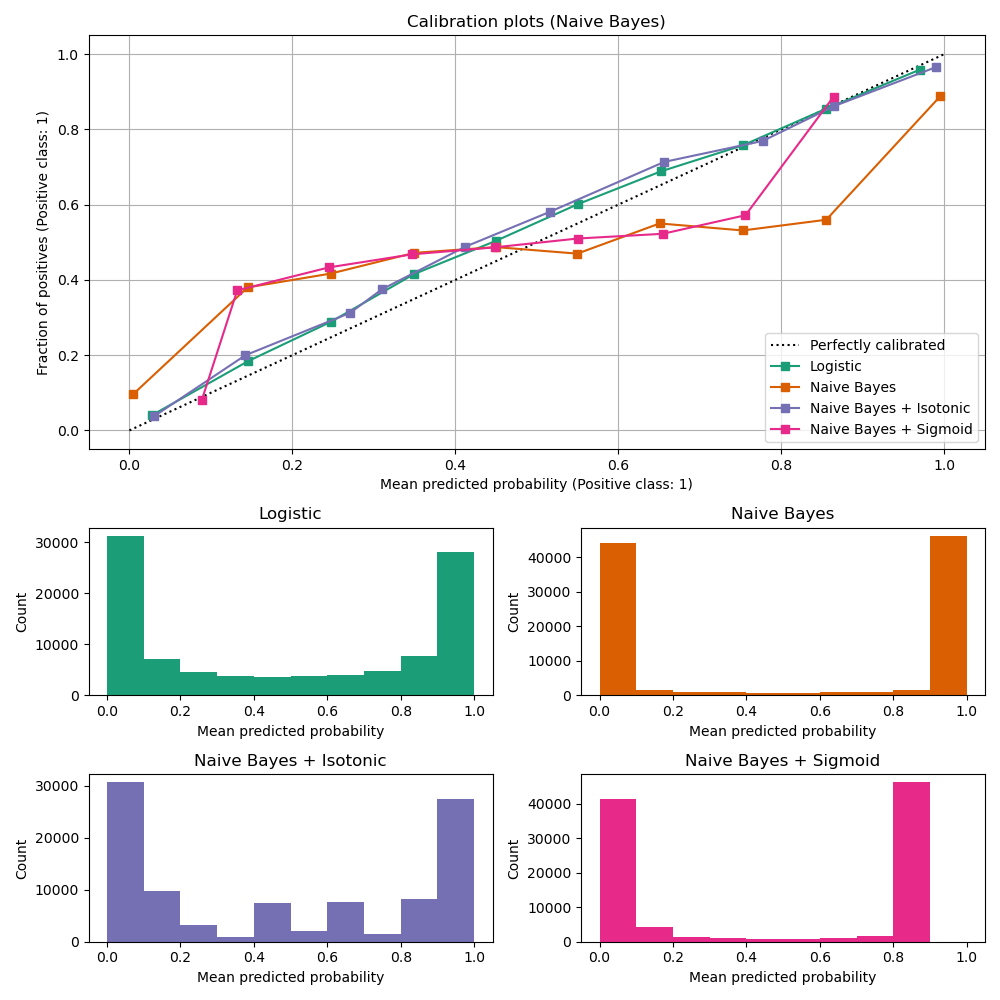
未校准的GaussianNB校准效果不佳,原因在于冗余特征违反了特征独立性假设,导致分类器过于自信,这通过典型的转置S型曲线来体现。通过保序回归对GaussianNB的概率进行校准可以解决这个问题,从接近对角线的校准曲线中可以看出。S型回归也能略微改善校准,尽管不如非参数保序回归强。这可以归因于我们有大量的校准数据,因此可以充分利用非参数模型的更大灵活性。
下面我们将对几个分类指标进行定量分析:布里尔分数损失、对数损失、精确率、召回率、F1分数 和 ROC AUC。
from collections import defaultdict
import pandas as pd
from sklearn.metrics import (
brier_score_loss,
f1_score,
log_loss,
precision_score,
recall_score,
roc_auc_score,
)
scores = defaultdict(list)
for i, (clf, name) in enumerate(clf_list):
clf.fit(X_train, y_train)
y_prob = clf.predict_proba(X_test)
y_pred = clf.predict(X_test)
scores["Classifier"].append(name)
for metric in [brier_score_loss, log_loss, roc_auc_score]:
score_name = metric.__name__.replace("_", " ").replace("score", "").capitalize()
scores[score_name].append(metric(y_test, y_prob[:, 1]))
for metric in [precision_score, recall_score, f1_score]:
score_name = metric.__name__.replace("_", " ").replace("score", "").capitalize()
scores[score_name].append(metric(y_test, y_pred))
score_df = pd.DataFrame(scores).set_index("Classifier")
score_df.round(decimals=3)
score_df
请注意,尽管校准改善了布里尔分数损失(由校准项和精修项组成的指标)和对数损失,但它并没有显著改变预测准确性指标(精确率、召回率和F1分数)。这是因为校准不应该显著改变决策阈值(图中x = 0.5处)的预测概率。然而,校准应该使预测概率更准确,从而在不确定性下进行分配决策时更有用。此外,ROC AUC根本不应改变,因为校准是单调变换。事实上,所有排序指标都不受校准影响。
线性支持向量分类器#
接下来,我们将比较
LogisticRegression(基准)未校准的
LinearSVC。由于SVC默认不输出概率,我们通过应用最小-最大缩放将决策函数的输出粗略地缩放到[0, 1]之间。
import numpy as np
from sklearn.svm import LinearSVC
class NaivelyCalibratedLinearSVC(LinearSVC):
"""LinearSVC with `predict_proba` method that naively scales
`decision_function` output for binary classification."""
def fit(self, X, y):
super().fit(X, y)
df = self.decision_function(X)
self.df_min_ = df.min()
self.df_max_ = df.max()
def predict_proba(self, X):
"""Min-max scale output of `decision_function` to [0, 1]."""
df = self.decision_function(X)
calibrated_df = (df - self.df_min_) / (self.df_max_ - self.df_min_)
proba_pos_class = np.clip(calibrated_df, 0, 1)
proba_neg_class = 1 - proba_pos_class
proba = np.c_[proba_neg_class, proba_pos_class]
return proba
lr = LogisticRegression(C=1.0)
svc = NaivelyCalibratedLinearSVC(max_iter=10_000)
svc_isotonic = CalibratedClassifierCV(svc, cv=2, method="isotonic")
svc_sigmoid = CalibratedClassifierCV(svc, cv=2, method="sigmoid")
clf_list = [
(lr, "Logistic"),
(svc, "SVC"),
(svc_isotonic, "SVC + Isotonic"),
(svc_sigmoid, "SVC + Sigmoid"),
]
fig = plt.figure(figsize=(10, 10))
gs = GridSpec(4, 2)
ax_calibration_curve = fig.add_subplot(gs[:2, :2])
calibration_displays = {}
for i, (clf, name) in enumerate(clf_list):
clf.fit(X_train, y_train)
display = CalibrationDisplay.from_estimator(
clf,
X_test,
y_test,
n_bins=10,
name=name,
ax=ax_calibration_curve,
color=colors(i),
)
calibration_displays[name] = display
ax_calibration_curve.grid()
ax_calibration_curve.set_title("Calibration plots (SVC)")
# Add histogram
grid_positions = [(2, 0), (2, 1), (3, 0), (3, 1)]
for i, (_, name) in enumerate(clf_list):
row, col = grid_positions[i]
ax = fig.add_subplot(gs[row, col])
ax.hist(
calibration_displays[name].y_prob,
range=(0, 1),
bins=10,
label=name,
color=colors(i),
)
ax.set(title=name, xlabel="Mean predicted probability", ylabel="Count")
plt.tight_layout()
plt.show()
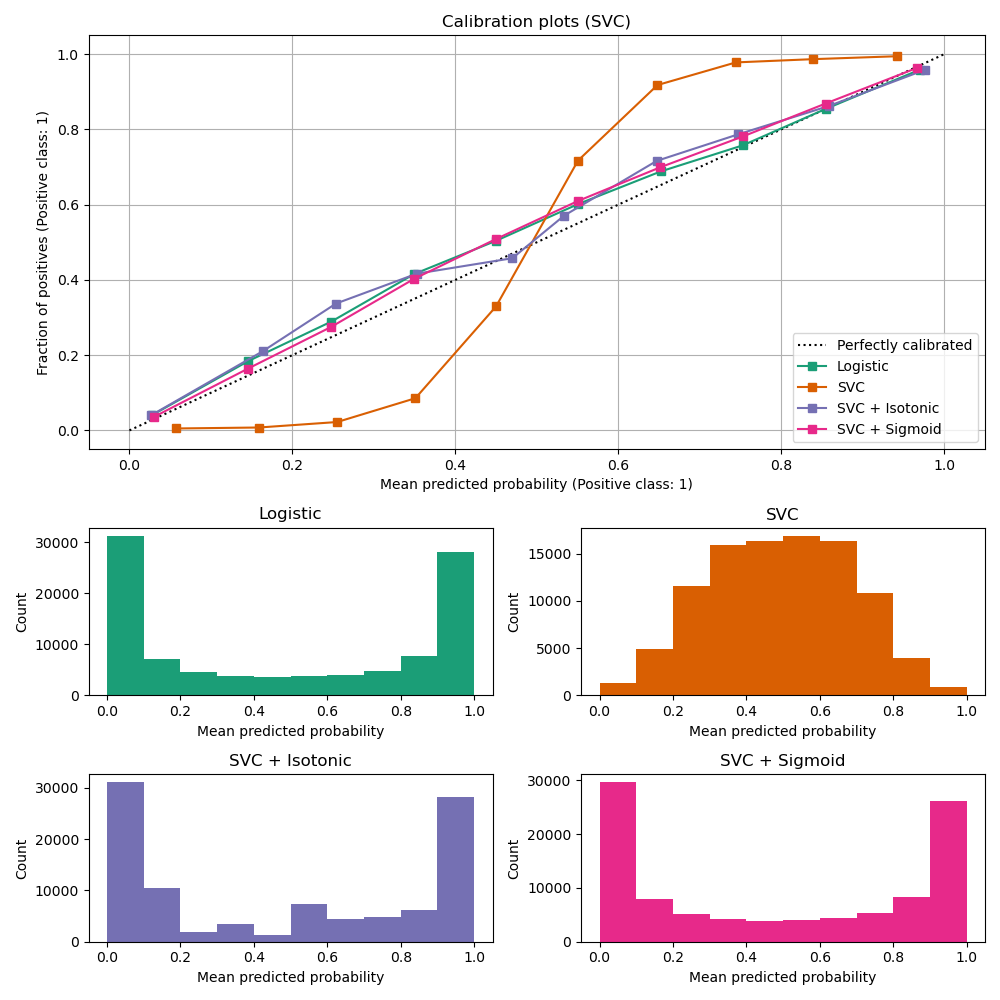
LinearSVC表现出与GaussianNB相反的行为;其校准曲线呈S型,这是置信度不足的分类器的典型特征。对于LinearSVC,这归因于合页损失的边距特性,该特性侧重于靠近决策边界的样本(支持向量)。远离决策边界的样本不会影响合页损失。因此,LinearSVC不试图在高置信度区域中分离样本是合理的。这导致校准曲线在0和1附近变得更平坦,Niculescu-Mizil & Caruana [1]在各种数据集上通过实验证明了这一点。
两种校准方式(S型和保序)都能解决这个问题,并产生相似的结果。
与之前一样,我们展示了布里尔分数损失、对数损失、精确率、召回率、F1分数 和 ROC AUC。
scores = defaultdict(list)
for i, (clf, name) in enumerate(clf_list):
clf.fit(X_train, y_train)
y_prob = clf.predict_proba(X_test)
y_pred = clf.predict(X_test)
scores["Classifier"].append(name)
for metric in [brier_score_loss, log_loss, roc_auc_score]:
score_name = metric.__name__.replace("_", " ").replace("score", "").capitalize()
scores[score_name].append(metric(y_test, y_prob[:, 1]))
for metric in [precision_score, recall_score, f1_score]:
score_name = metric.__name__.replace("_", " ").replace("score", "").capitalize()
scores[score_name].append(metric(y_test, y_pred))
score_df = pd.DataFrame(scores).set_index("Classifier")
score_df.round(decimals=3)
score_df
如同上面的GaussianNB,校准改善了布里尔分数损失和对数损失,但对预测准确性指标(精确率、召回率和F1分数)改变不大。
总结#
参数化的S型校准可以处理基础分类器校准曲线呈S型的情况(例如,对于LinearSVC),但不能处理转置S型的情况(例如,GaussianNB)。非参数保序校准可以处理这两种情况,但可能需要更多数据才能产生良好结果。
参考文献#
脚本总运行时间: (0分钟 2.297秒)
相关示例