注
点击 此处 下载完整的示例代码,或通过 JupyterLite 或 Binder 在浏览器中运行此示例
模型正则化对训练和测试误差的影响#
在此示例中,我们评估了名为 ElasticNet 的线性模型中正则化参数的影响。为了进行此评估,我们使用 ValidationCurveDisplay 生成验证曲线。该曲线显示了模型在不同正则化参数值下的训练和测试分数。
一旦我们确定了最优的正则化参数,我们就会比较模型的真实系数和估计系数,以确定模型是否能够从噪声输入数据中恢复这些系数。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
生成样本数据#
我们生成一个回归数据集,其中包含相对于样本数量的许多特征。然而,只有 10% 的特征是信息性的。在这种情况下,暴露 L1 惩罚的线性模型通常用于恢复稀疏的系数集。
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
n_samples_train, n_samples_test, n_features = 150, 300, 500
X, y, true_coef = make_regression(
n_samples=n_samples_train + n_samples_test,
n_features=n_features,
n_informative=50,
shuffle=False,
noise=1.0,
coef=True,
random_state=42,
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=n_samples_train, test_size=n_samples_test, shuffle=False
)
模型定义#
在这里,我们不使用只暴露 L1 惩罚的模型。相反,我们使用一个 ElasticNet 模型,它同时暴露 L1 和 L2 惩罚。
我们固定 l1_ratio 参数,使得模型找到的解仍然是稀疏的。因此,这类模型试图找到一个稀疏解,但同时也在试图将所有系数收缩到零。
此外,我们强制模型系数为正,因为我们知道 make_regression 生成的响应带有正信号。因此,我们利用这一先验知识来获得更好的模型。
from sklearn.linear_model import ElasticNet
enet = ElasticNet(l1_ratio=0.9, positive=True, max_iter=10_000)
评估正则化参数的影响#
为了评估正则化参数的影响,我们使用验证曲线。该曲线显示了模型在不同正则化参数值下的训练和测试分数。
正则化参数 alpha 应用于模型系数:当它趋于零时,不施加正则化,模型试图以最小的误差拟合训练数据。然而,当特征存在噪声时,这会导致过拟合。当 alpha 增加时,模型系数受到约束,因此模型无法紧密拟合训练数据,从而避免过拟合。但是,如果应用过多的正则化,模型将欠拟合数据,无法正确捕获信号。
验证曲线有助于在两个极端之间找到一个很好的权衡:模型未正则化,因此足够灵活以适应信号,但又不过于灵活以致过拟合。 ValidationCurveDisplay 允许我们显示不同 alpha 值范围内的训练和验证分数。
import numpy as np
from sklearn.model_selection import ValidationCurveDisplay
alphas = np.logspace(-5, 1, 60)
disp = ValidationCurveDisplay.from_estimator(
enet,
X_train,
y_train,
param_name="alpha",
param_range=alphas,
scoring="r2",
n_jobs=2,
score_type="both",
)
disp.ax_.set(
title=r"Validation Curve for ElasticNet (R$^2$ Score)",
xlabel=r"alpha (regularization strength)",
ylabel="R$^2$ Score",
)
test_scores_mean = disp.test_scores.mean(axis=1)
idx_avg_max_test_score = np.argmax(test_scores_mean)
disp.ax_.vlines(
alphas[idx_avg_max_test_score],
disp.ax_.get_ylim()[0],
test_scores_mean[idx_avg_max_test_score],
color="k",
linewidth=2,
linestyle="--",
label=f"Optimum on test\n$\\alpha$ = {alphas[idx_avg_max_test_score]:.2e}",
)
_ = disp.ax_.legend(loc="lower right")
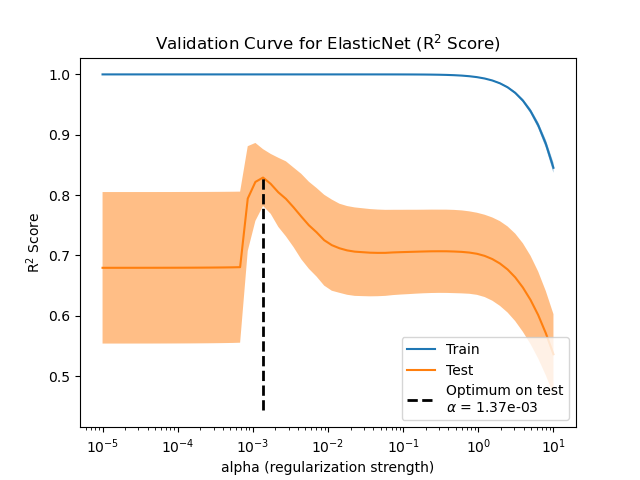
为了找到最优的正则化参数,我们可以选择使验证分数最大化的 alpha 值。
系数比较#
既然我们已经确定了最优的正则化参数,我们就可以比较真实系数和估计系数了。
首先,让我们将正则化参数设置为最优值,并在训练数据上拟合模型。此外,我们将显示该模型的测试分数。
enet.set_params(alpha=alphas[idx_avg_max_test_score]).fit(X_train, y_train)
print(
f"Test score: {enet.score(X_test, y_test):.3f}",
)
Test score: 0.884
现在,我们绘制真实系数和估计系数。
import matplotlib.pyplot as plt
fig, axs = plt.subplots(ncols=2, figsize=(12, 6), sharex=True, sharey=True)
for ax, coef, title in zip(axs, [true_coef, enet.coef_], ["True", "Model"]):
ax.stem(coef)
ax.set(
title=f"{title} Coefficients",
xlabel="Feature Index",
ylabel="Coefficient Value",
)
fig.suptitle(
"Comparison of the coefficients of the true generative model and \n"
"the estimated elastic net coefficients"
)
plt.show()
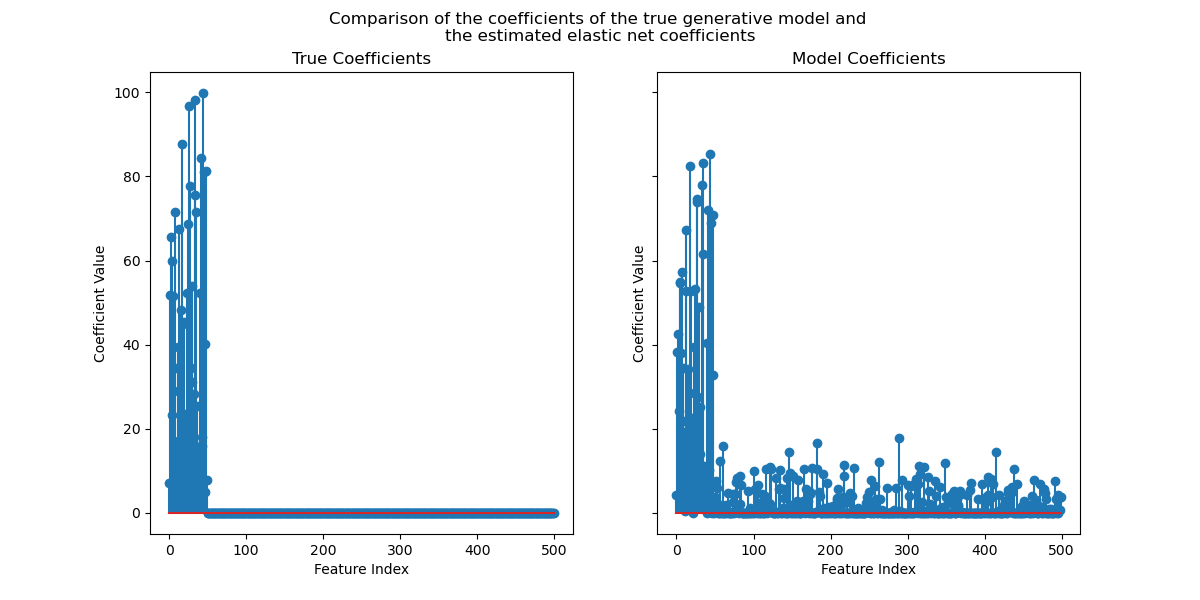
尽管原始系数是稀疏的,但估计系数并非如此稀疏。原因是我们将 l1_ratio 参数固定为 0.9。我们可以通过增加 l1_ratio 参数来强制模型获得更稀疏的解。
然而,我们观察到,对于真实生成模型中接近零的估计系数,我们的模型将其收缩到零。因此,我们没有恢复真实系数,但我们获得了与测试集上获得的性能相符的合理结果。
脚本总运行时间: (0 分 4.730 秒)
相关示例