注意
转到末尾 下载完整示例代码。或通过 JupyterLite 或 Binder 在浏览器中运行此示例
绘制分类概率#
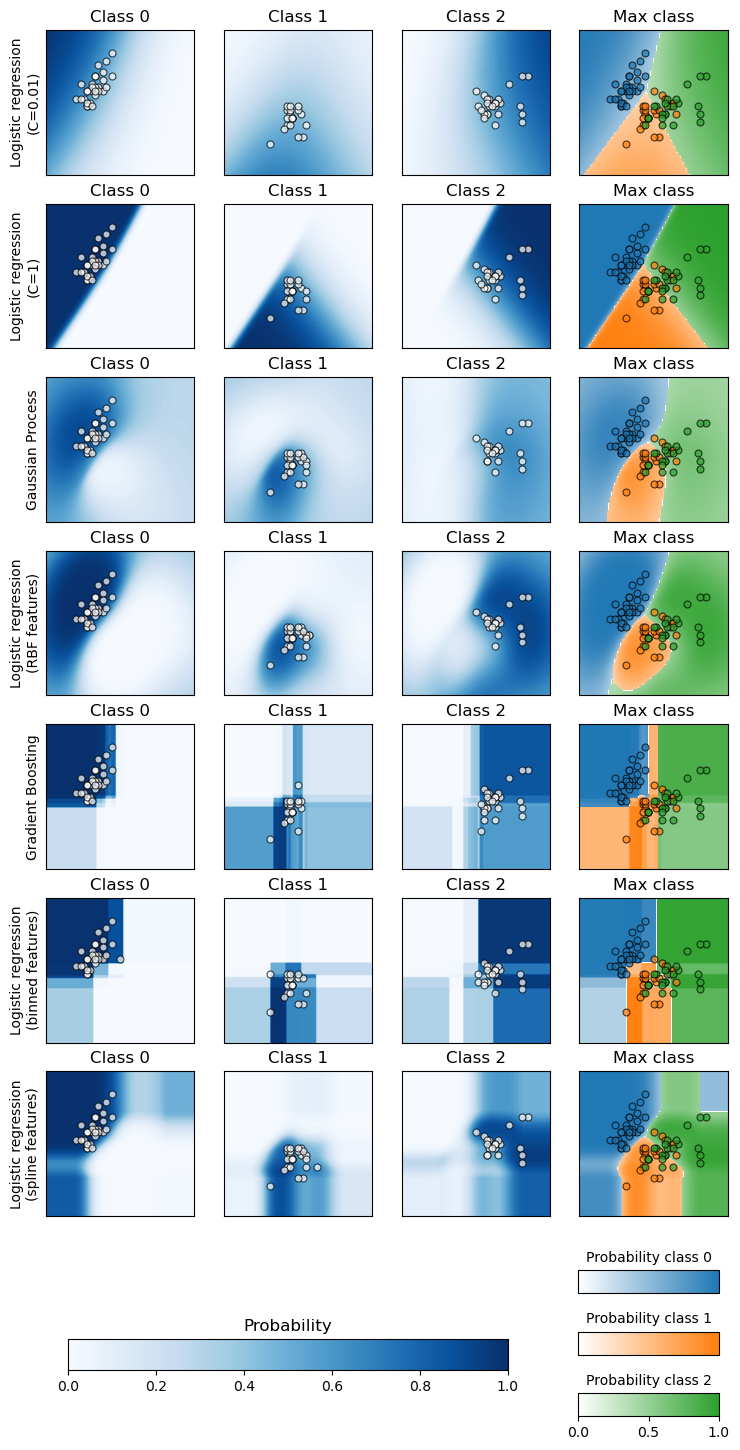
此示例演示了如何使用 sklearn.inspection.DecisionBoundaryDisplay 在二维特征空间中绘制各种分类器的预测类别概率,主要用于教学目的。
前三列显示了两个特征不同值下的预测概率。圆形标记表示被预测属于该类别的测试数据。
在最后一列中,每个图上都表示了所有三个类别;绘制了每个点上预测概率最高的类别。圆形标记显示了测试数据,并按其真实标签着色。
作者:scikit-learn 开发者 SPDX-License-Identifier: BSD-3-Clause
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from matplotlib import cm
from sklearn import datasets
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.kernel_approximation import Nystroem
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, log_loss, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import (
KBinsDiscretizer,
PolynomialFeatures,
SplineTransformer,
)
数据:鸢尾花数据集的 2D 投影#
iris = datasets.load_iris()
X = iris.data[:, 0:2] # we only take the first two features for visualization
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=42
)
概率分类器#
我们将绘制具有 predict_proba 方法的几个分类器的决策边界。这将使我们能够可视化分类器在其预测不确定区域中的不确定性。
classifiers = {
"Logistic regression\n(C=0.01)": LogisticRegression(C=0.1),
"Logistic regression\n(C=1)": LogisticRegression(C=100),
"Gaussian Process": GaussianProcessClassifier(kernel=1.0 * RBF([1.0, 1.0])),
"Logistic regression\n(RBF features)": make_pipeline(
Nystroem(kernel="rbf", gamma=5e-1, n_components=50, random_state=1),
LogisticRegression(C=10),
),
"Gradient Boosting": HistGradientBoostingClassifier(),
"Logistic regression\n(binned features)": make_pipeline(
KBinsDiscretizer(n_bins=5, quantile_method="averaged_inverted_cdf"),
PolynomialFeatures(interaction_only=True),
LogisticRegression(C=10),
),
"Logistic regression\n(spline features)": make_pipeline(
SplineTransformer(n_knots=5),
PolynomialFeatures(interaction_only=True),
LogisticRegression(C=10),
),
}
绘制决策边界#
对于每个分类器,我们在前三列绘制了每个类别的概率,在最后一列绘制了最可能类别的概率。
n_classifiers = len(classifiers)
scatter_kwargs = {
"s": 25,
"marker": "o",
"linewidths": 0.8,
"edgecolor": "k",
"alpha": 0.7,
}
y_unique = np.unique(y)
# Ensure legend not cut off
mpl.rcParams["savefig.bbox"] = "tight"
fig, axes = plt.subplots(
nrows=n_classifiers,
ncols=len(iris.target_names) + 1,
figsize=(4 * 2.2, n_classifiers * 2.2),
)
evaluation_results = []
levels = 100
for classifier_idx, (name, classifier) in enumerate(classifiers.items()):
y_pred = classifier.fit(X_train, y_train).predict(X_test)
y_pred_proba = classifier.predict_proba(X_test)
accuracy_test = accuracy_score(y_test, y_pred)
roc_auc_test = roc_auc_score(y_test, y_pred_proba, multi_class="ovr")
log_loss_test = log_loss(y_test, y_pred_proba)
evaluation_results.append(
{
"name": name.replace("\n", " "),
"accuracy": accuracy_test,
"roc_auc": roc_auc_test,
"log_loss": log_loss_test,
}
)
for label in y_unique:
# plot the probability estimate provided by the classifier
disp = DecisionBoundaryDisplay.from_estimator(
classifier,
X_train,
response_method="predict_proba",
class_of_interest=label,
ax=axes[classifier_idx, label],
vmin=0,
vmax=1,
cmap="Blues",
levels=levels,
)
axes[classifier_idx, label].set_title(f"Class {label}")
# plot data predicted to belong to given class
mask_y_pred = y_pred == label
axes[classifier_idx, label].scatter(
X_test[mask_y_pred, 0], X_test[mask_y_pred, 1], c="w", **scatter_kwargs
)
axes[classifier_idx, label].set(xticks=(), yticks=())
# add column that shows all classes by plotting class with max 'predict_proba'
max_class_disp = DecisionBoundaryDisplay.from_estimator(
classifier,
X_train,
response_method="predict_proba",
class_of_interest=None,
ax=axes[classifier_idx, len(y_unique)],
vmin=0,
vmax=1,
levels=levels,
)
for label in y_unique:
mask_label = y_test == label
axes[classifier_idx, 3].scatter(
X_test[mask_label, 0],
X_test[mask_label, 1],
c=max_class_disp.multiclass_colors_[[label], :],
**scatter_kwargs,
)
axes[classifier_idx, 3].set(xticks=(), yticks=())
axes[classifier_idx, 3].set_title("Max class")
axes[classifier_idx, 0].set_ylabel(name)
# colorbar for single class plots
ax_single = fig.add_axes([0.15, 0.01, 0.5, 0.02])
plt.title("Probability")
_ = plt.colorbar(
cm.ScalarMappable(norm=None, cmap=disp.surface_.cmap),
cax=ax_single,
orientation="horizontal",
)
# colorbars for max probability class column
max_class_cmaps = [s.cmap for s in max_class_disp.surface_]
for label in y_unique:
ax_max = fig.add_axes([0.73, (0.06 - (label * 0.04)), 0.16, 0.015])
plt.title(f"Probability class {label}", fontsize=10)
_ = plt.colorbar(
cm.ScalarMappable(norm=None, cmap=max_class_cmaps[label]),
cax=ax_max,
orientation="horizontal",
)
if label in (0, 1):
ax_max.set(xticks=(), yticks=())
定量评估#
pd.DataFrame(evaluation_results).round(2)
分析#
两个在原始特征上拟合的逻辑回归模型如预期显示出线性决策边界。对于这个特定问题,这似乎没有不利影响,因为这两个模型在测试集上进行定量评估时与非线性模型具有竞争力。我们可以观察到正则化程度会影响模型置信度:C 值较低的强正则化模型颜色更浅。正则化还会影响决策边界的方向,导致 ROC AUC 略有不同。
另一方面,log-loss 评估了锐度和校准,因此强烈偏向弱正则化的逻辑回归模型,这可能是因为强正则化模型置信度不足。这可以通过使用 sklearn.calibration.CalibrationDisplay 查看校准曲线来证实。
具有 RBF 特征的逻辑回归模型具有“斑点状”决策边界,在原始特征空间中是非线性的,并且与配置为使用 RBF 核的高斯过程分类器的决策边界非常相似。
在具有交互作用的分箱特征上拟合的逻辑回归模型具有在原始特征空间中非线性的决策边界,并且与梯度提升分类器的决策边界非常相似:两种模型在推断到特征空间的未见区域时都倾向于轴对齐的决策。
在具有交互作用的样条特征上拟合的逻辑回归模型具有相似的轴对齐外推行为,但在特征空间的密集区域中比前两个模型具有更平滑的决策边界。
总之,有趣的是,逻辑回归模型的特征工程可用于模仿各种非线性模型的一些归纳偏置。然而,对于这个特定数据集,使用原始特征足以训练出一个有竞争力的模型。对于其他数据集来说,情况不一定如此。
脚本总运行时间: (0 分 2.612 秒)
相关示例