注意
前往末尾 下载完整示例代码,或通过 JupyterLite 或 Binder 在您的浏览器中运行此示例。
可视化 VotingClassifier 的概率预测#
绘制由三个不同分类器预测并由 VotingClassifier 平均的玩具数据集中的预测类别概率。
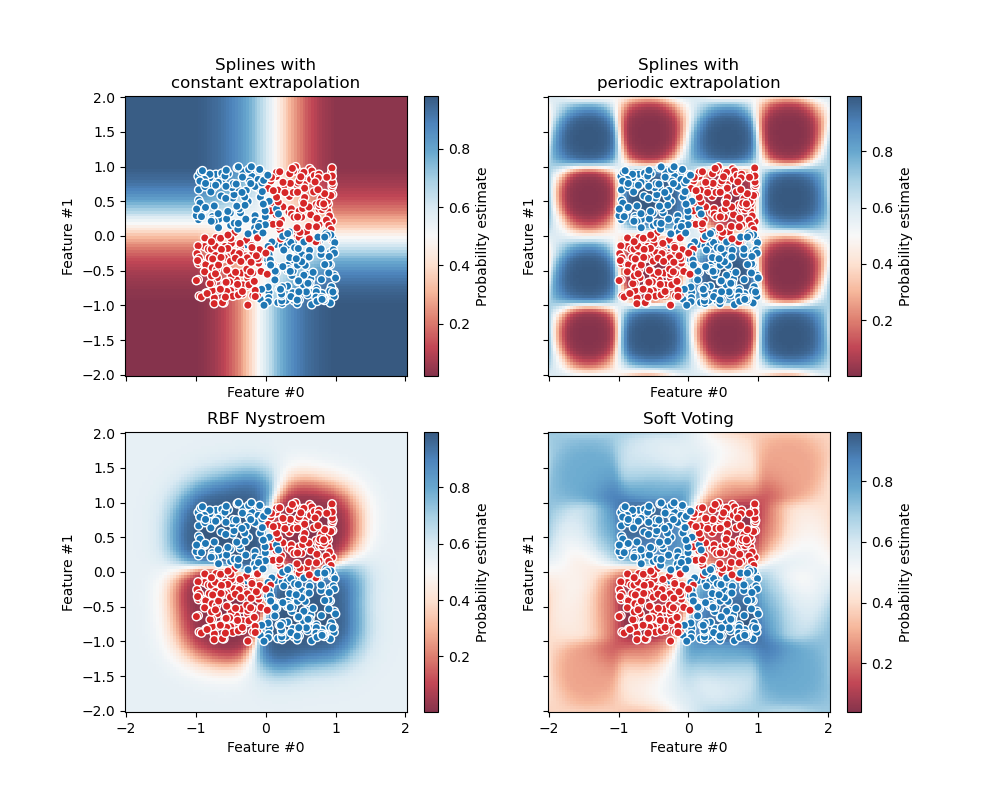
首先,初始化三个线性分类器。其中两个是带有交互项的样条模型,一个使用常数外推,另一个使用周期性外推。第三个分类器是使用默认“rbf”核的 Nystroem。
在本示例的第一部分,使用这三个分类器来演示使用 VotingClassifier 进行加权平均的软投票。我们设置 weights=[2, 1, 3],这意味着常数外推样条模型的预测权重是周期性样条模型的两倍,Nystroem 模型的预测权重是周期性样条模型的三倍。
第二部分演示了如何将软预测转换为硬预测。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
我们首先生成一个带有噪声的 XOR 数据集,这是一个二分类任务。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from matplotlib.colors import ListedColormap
n_samples = 500
rng = np.random.default_rng(0)
feature_names = ["Feature #0", "Feature #1"]
common_scatter_plot_params = dict(
cmap=ListedColormap(["tab:red", "tab:blue"]),
edgecolor="white",
linewidth=1,
)
xor = pd.DataFrame(
np.random.RandomState(0).uniform(low=-1, high=1, size=(n_samples, 2)),
columns=feature_names,
)
noise = rng.normal(loc=0, scale=0.1, size=(n_samples, 2))
target_xor = np.logical_xor(
xor["Feature #0"] + noise[:, 0] > 0, xor["Feature #1"] + noise[:, 1] > 0
)
X = xor[feature_names]
y = target_xor.astype(np.int32)
fig, ax = plt.subplots()
ax.scatter(X["Feature #0"], X["Feature #1"], c=y, **common_scatter_plot_params)
ax.set_title("The XOR dataset")
plt.show()
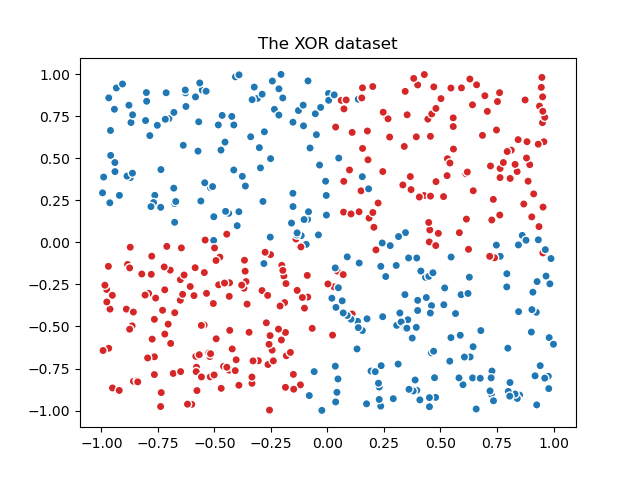
由于 XOR 数据集固有的非线性可分离性,通常会首选基于树的模型。然而,适当的特征工程与线性模型相结合可以产生有效的结果,并额外带来为受噪声影响的过渡区域中的样本生成更好校准概率的好处。
我们在整个数据集上定义并拟合模型。
from sklearn.ensemble import VotingClassifier
from sklearn.kernel_approximation import Nystroem
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures, SplineTransformer, StandardScaler
clf1 = make_pipeline(
SplineTransformer(degree=2, n_knots=2),
PolynomialFeatures(interaction_only=True),
LogisticRegression(C=10),
)
clf2 = make_pipeline(
SplineTransformer(
degree=2,
n_knots=4,
extrapolation="periodic",
include_bias=True,
),
PolynomialFeatures(interaction_only=True),
LogisticRegression(C=10),
)
clf3 = make_pipeline(
StandardScaler(),
Nystroem(gamma=2, random_state=0),
LogisticRegression(C=10),
)
weights = [2, 1, 3]
eclf = VotingClassifier(
estimators=[
("constant splines model", clf1),
("periodic splines model", clf2),
("nystroem model", clf3),
],
voting="soft",
weights=weights,
)
clf1.fit(X, y)
clf2.fit(X, y)
clf3.fit(X, y)
eclf.fit(X, y)
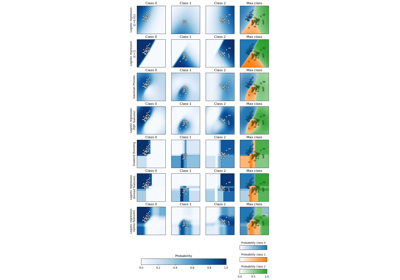
最后,我们使用 DecisionBoundaryDisplay 绘制预测概率。通过使用发散颜色映射(例如 "RdBu"),我们可以确保较深的颜色对应于接近 0 或 1 的 predict_proba,而白色对应于 0.5 的 predict_proba。
from itertools import product
from sklearn.inspection import DecisionBoundaryDisplay
fig, axarr = plt.subplots(2, 2, sharex="col", sharey="row", figsize=(10, 8))
for idx, clf, title in zip(
product([0, 1], [0, 1]),
[clf1, clf2, clf3, eclf],
[
"Splines with\nconstant extrapolation",
"Splines with\nperiodic extrapolation",
"RBF Nystroem",
"Soft Voting",
],
):
disp = DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="predict_proba",
plot_method="pcolormesh",
cmap="RdBu",
alpha=0.8,
ax=axarr[idx[0], idx[1]],
)
axarr[idx[0], idx[1]].scatter(
X["Feature #0"],
X["Feature #1"],
c=y,
**common_scatter_plot_params,
)
axarr[idx[0], idx[1]].set_title(title)
fig.colorbar(disp.surface_, ax=axarr[idx[0], idx[1]], label="Probability estimate")
plt.show()
作为健全性检查,我们可以验证对于给定样本,由 VotingClassifier 预测的概率确实是各个分类器软预测的加权平均值。
在本示例中的二分类情况下,predict_proba 数组的第一个条目包含属于类别 0(此处为红色)的概率,第二个条目包含属于类别 1(此处为蓝色)的概率。
test_sample = pd.DataFrame({"Feature #0": [-0.5], "Feature #1": [1.5]})
predict_probas = [est.predict_proba(test_sample).ravel() for est in eclf.estimators_]
for (est_name, _), est_probas in zip(eclf.estimators, predict_probas):
print(f"{est_name}'s predicted probabilities: {est_probas}")
constant splines model's predicted probabilities: [0.11272662 0.88727338]
periodic splines model's predicted probabilities: [0.99726573 0.00273427]
nystroem model's predicted probabilities: [0.3185838 0.6814162]
Weighted average of soft-predictions: [0.3630784 0.6369216]
我们可以看到,上面手动计算的预测概率与 VotingClassifier 产生的概率是等效的
print(
"Predicted probability of VotingClassifier: "
f"{eclf.predict_proba(test_sample).ravel()}"
)
Predicted probability of VotingClassifier: [0.3630784 0.6369216]
当提供权重时,要将软预测转换为硬预测,需要计算每个类别的加权平均预测概率。然后,最终的类别标签将从具有最高平均概率的类别标签中得出,这在二分类情况下对应于 predict_proba=0.5 的默认阈值。
Class with the highest weighted average of soft-predictions: 1
这等效于 VotingClassifier 的 predict 方法的输出。
print(f"Predicted class of VotingClassifier: {eclf.predict(test_sample).ravel()}")
Predicted class of VotingClassifier: [1]
软投票可以像任何其他概率分类器一样设置阈值。这允许您设置一个阈值概率,当预测概率达到该阈值时预测为正类别,而不是简单地选择具有最高预测概率的类别。
from sklearn.model_selection import FixedThresholdClassifier
eclf_other_threshold = FixedThresholdClassifier(
eclf, threshold=0.7, response_method="predict_proba"
).fit(X, y)
print(
"Predicted class of thresholded VotingClassifier: "
f"{eclf_other_threshold.predict(test_sample)}"
)
Predicted class of thresholded VotingClassifier: [0]
脚本总运行时间: (0 分 0.660 秒)
相关示例