注意
转到末尾 下载完整示例代码。或者通过 JupyterLite 或 Binder 在浏览器中运行此示例
scikit-learn 1.0 发布亮点#
我们非常高兴地宣布 scikit-learn 1.0 发布!该库已经稳定了一段时间,发布 1.0 版本是为了认可这一点并向用户发出信号。除了通常的两个版本弃用周期外,此版本不包含任何破坏性更改。未来,我们将尽力保持这种模式。
此版本包含一些新的关键功能以及许多改进和错误修复。下面我们将详细介绍此版本的一些主要功能。有关所有更改的详尽列表,请参阅发布说明。
要安装最新版本(使用 pip)
pip install --upgrade scikit-learn
或使用 conda
conda install -c conda-forge scikit-learn
关键字和位置参数#
scikit-learn API 提供了许多具有大量输入参数的函数和方法。例如,在此版本之前,可以实例化一个 HistGradientBoostingRegressor 如下:
HistGradientBoostingRegressor("squared_error", 0.1, 100, 31, None,
20, 0.0, 255, None, None, False, "auto", "loss", 0.1, 10, 1e-7,
0, None)
理解上述代码需要读者查阅 API 文档并检查每个参数的位置和含义。为了提高基于 scikit-learn 编写的代码的可读性,现在用户必须以关键字参数的形式提供大多数参数的名称,而不是位置参数。例如,上面的代码将是:
HistGradientBoostingRegressor(
loss="squared_error",
learning_rate=0.1,
max_iter=100,
max_leaf_nodes=31,
max_depth=None,
min_samples_leaf=20,
l2_regularization=0.0,
max_bins=255,
categorical_features=None,
monotonic_cst=None,
warm_start=False,
early_stopping="auto",
scoring="loss",
validation_fraction=0.1,
n_iter_no_change=10,
tol=1e-7,
verbose=0,
random_state=None,
)
这大大提高了可读性。位置参数自 0.23 版本以来已被弃用,现在将引发 TypeError。在某些情况下仍然允许有限数量的位置参数,例如在 PCA 中,PCA(10) 仍然允许,但 PCA(10, False) 则不允许。
样条变换器#
一种向数据集特征集添加非线性项的方法是使用新的 SplineTransformer 为连续/数值特征生成样条基函数。样条是分段多项式,由其多项式次数和节点位置参数化。SplineTransformer 实现了 B 样条基。
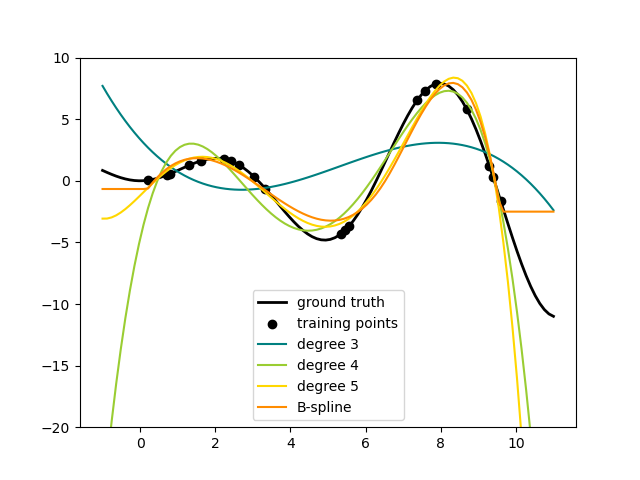
以下代码展示了样条的实际应用,更多信息请参阅用户指南。
import numpy as np
from sklearn.preprocessing import SplineTransformer
X = np.arange(5).reshape(5, 1)
spline = SplineTransformer(degree=2, n_knots=3)
spline.fit_transform(X)
array([[0.5 , 0.5 , 0. , 0. ],
[0.125, 0.75 , 0.125, 0. ],
[0. , 0.5 , 0.5 , 0. ],
[0. , 0.125, 0.75 , 0.125],
[0. , 0. , 0.5 , 0.5 ]])
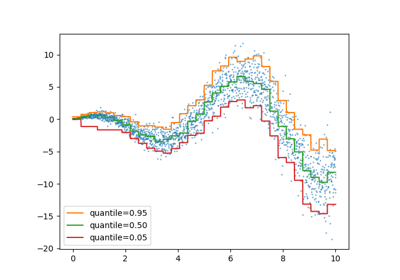
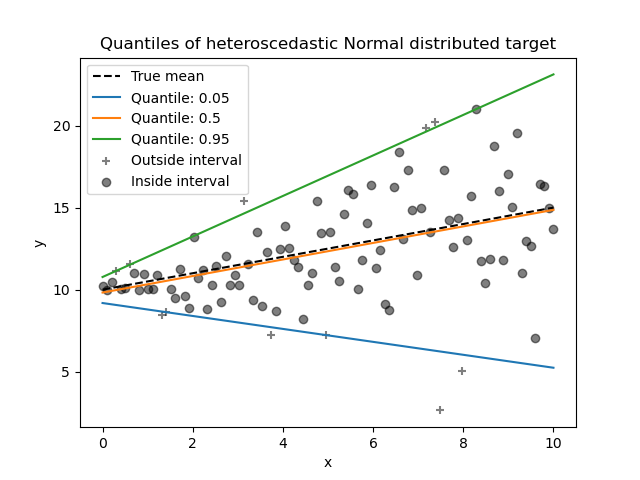
分位数回归器#
分位数回归估计在 \(X\) 条件下 \(y\) 的中位数或其他分位数,而普通最小二乘 (OLS) 估计条件均值。
作为一个线性模型,新的 QuantileRegressor 为第 \(q\) 个分位数(\(q \in (0, 1)\))提供线性预测 \(\hat{y}(w, X) = Xw\)。然后通过以下最小化问题找到权重或系数 \(w\):
这包括弹珠损失(又称线性损失),另请参阅 mean_pinball_loss:
以及由参数 alpha 控制的 L1 惩罚,类似于 linear_model.Lasso。
请查看以下示例了解其工作原理,并参阅用户指南了解更多详情。
特征名称支持#
当估计器在 fit 期间传入 pandas 的 dataframe 时,估计器将设置一个包含特征名称的 feature_names_in_ 属性。这是 SLEP007 的一部分。请注意,只有当 dataframe 中的列名都是字符串时,才启用特征名称支持。feature_names_in_ 用于检查在非-fit(例如 predict)中传入的 dataframe 的列名与 fit 中的特征一致。
import pandas as pd
from sklearn.preprocessing import StandardScaler
X = pd.DataFrame([[1, 2, 3], [4, 5, 6]], columns=["a", "b", "c"])
scalar = StandardScaler().fit(X)
scalar.feature_names_in_
array(['a', 'b', 'c'], dtype=object)
get_feature_names_out 的支持可用于已经具有 get_feature_names 的转换器,以及输入和输出之间存在一对一对应关系的转换器,例如 StandardScaler。get_feature_names_out 支持将在未来版本中添加到所有其他转换器。此外,compose.ColumnTransformer.get_feature_names_out 可用于组合其转换器的特征名称:
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
X = pd.DataFrame({"pet": ["dog", "cat", "fish"], "age": [3, 7, 1]})
preprocessor = ColumnTransformer(
[
("numerical", StandardScaler(), ["age"]),
("categorical", OneHotEncoder(), ["pet"]),
],
verbose_feature_names_out=False,
).fit(X)
preprocessor.get_feature_names_out()
array(['age', 'pet_cat', 'pet_dog', 'pet_fish'], dtype=object)
当此 preprocessor 与流水线一起使用时,分类器使用的特征名称通过切片和调用 get_feature_names_out 获得。
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
y = [1, 0, 1]
pipe = make_pipeline(preprocessor, LogisticRegression())
pipe.fit(X, y)
pipe[:-1].get_feature_names_out()
array(['age', 'pet_cat', 'pet_dog', 'pet_fish'], dtype=object)
更灵活的绘图 API#
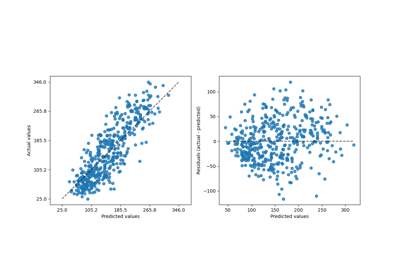
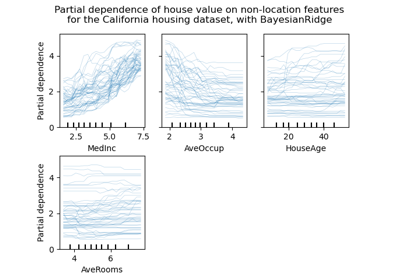
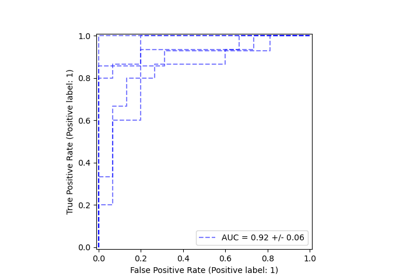
metrics.ConfusionMatrixDisplay、metrics.PrecisionRecallDisplay、metrics.DetCurveDisplay 和 inspection.PartialDependenceDisplay 现在公开了两个类方法:from_estimator 和 from_predictions,允许用户根据预测或估计器创建绘图。这意味着相应的 plot_* 函数已被弃用。请查看示例一和示例二,了解如何使用新的绘图功能。
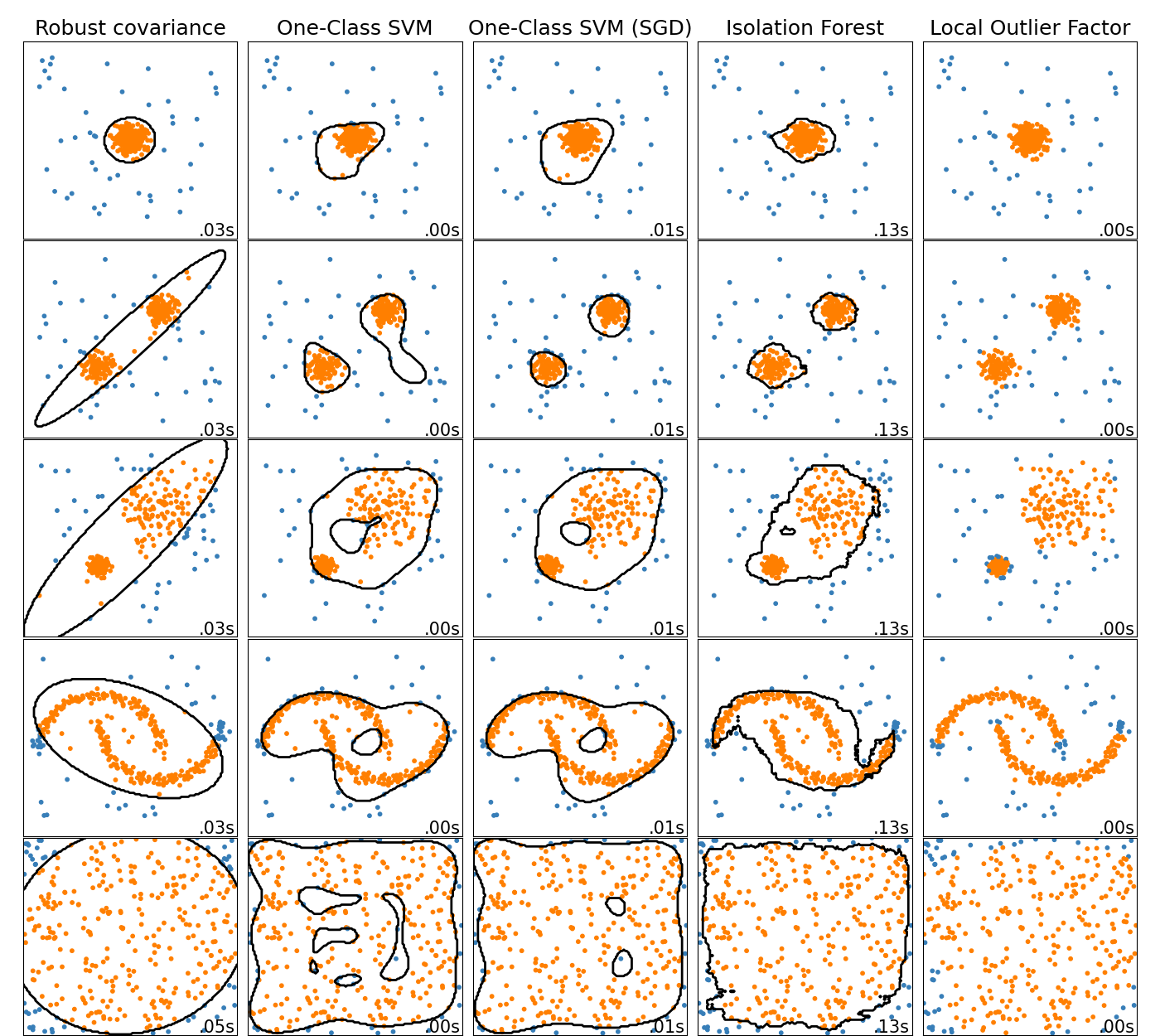
在线一类 SVM#
新的类 SGDOneClassSVM 实现了使用随机梯度下降的一类 SVM 的在线线性版本。结合核近似技术,SGDOneClassSVM 可以用于近似在 OneClassSVM 中实现的核化一类 SVM 的解,其拟合时间复杂度与样本数量呈线性关系。请注意,核化一类 SVM 的复杂度在样本数量上至多是二次的。SGDOneClassSVM 因此非常适合具有大量训练样本(> 10,000)的数据集,因为 SGD 变体可以快几个数量级。请查看此示例了解其用法,并参阅用户指南了解更多详情。
基于直方图的梯度提升模型现在稳定了#
HistGradientBoostingRegressor 和 HistGradientBoostingClassifier 不再是实验性的,可以直接导入和使用,如下所示:
from sklearn.ensemble import HistGradientBoostingClassifier
新的文档改进#
此版本包含许多文档改进。在超过 2100 个合并的拉取请求中,约有 800 个是对我们文档的改进。
脚本总运行时间: (0 分钟 0.015 秒)
相关示例