7.3. 数据预处理#
sklearn.preprocessing 包提供了几个常用的实用函数和转换器类,用于将原始特征向量转换为更适合下游估计器的表示形式。
通常,许多学习算法(如线性模型)受益于数据集的标准化(参见 特征缩放的重要性)。如果数据集中存在一些异常值,则鲁棒缩放器或其他转换器可能更合适。不同缩放器、转换器和归一化器在包含边缘异常值的数据集上的行为在 比较不同缩放器对含异常值数据的影响 中进行了强调。
7.3.1. 标准化,即均值移除和方差缩放#
数据集的**标准化**是 scikit-learn 中实现的**许多机器学习估计器的常见要求**;如果各个特征的分布不或多或少地像标准正态分布数据(**零均值和单位方差**的高斯分布),它们可能会表现不佳。
实践中,我们通常忽略分布的形状,仅通过移除每个特征的均值来使数据居中,然后通过将其非常数特征除以它们的标准差来进行缩放。
例如,学习算法目标函数中使用的许多元素(如支持向量机的RBF核或线性模型的l1和l2正则化器)可能假设所有特征都围绕零居中或具有相同数量级的方差。如果一个特征的方差比其他特征大几个数量级,它可能会主导目标函数,并使估计器无法按预期从其他特征中正确学习。
preprocessing 模块提供了 StandardScaler 实用类,这是一种对类数组数据集执行以下操作的快速简便方法
>>> from sklearn import preprocessing
>>> import numpy as np
>>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
>>> scaler = preprocessing.StandardScaler().fit(X_train)
>>> scaler
StandardScaler()
>>> scaler.mean_
array([1., 0., 0.33])
>>> scaler.scale_
array([0.81, 0.81, 1.24])
>>> X_scaled = scaler.transform(X_train)
>>> X_scaled
array([[ 0. , -1.22, 1.33 ],
[ 1.22, 0. , -0.267],
[-1.22, 1.22, -1.06 ]])
缩放后的数据具有零均值和单位方差。
>>> X_scaled.mean(axis=0)
array([0., 0., 0.])
>>> X_scaled.std(axis=0)
array([1., 1., 1.])
该类实现了 Transformer API,用于在训练集上计算均值和标准差,以便稍后能够在测试集上重新应用相同的转换。因此,该类适用于 Pipeline 的早期步骤。
>>> from sklearn.datasets import make_classification
>>> from sklearn.linear_model import LogisticRegression
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> X, y = make_classification(random_state=42)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
>>> pipe = make_pipeline(StandardScaler(), LogisticRegression())
>>> pipe.fit(X_train, y_train) # apply scaling on training data
Pipeline(steps=[('standardscaler', StandardScaler()),
('logisticregression', LogisticRegression())])
>>> pipe.score(X_test, y_test) # apply scaling on testing data, without leaking training data.
0.96
可以通过向 StandardScaler 的构造函数传入 with_mean=False 或 with_std=False 来禁用居中或缩放。
7.3.1.1. 将特征缩放到某个范围#
另一种标准化方法是将特征缩放到给定最小值和最大值之间,通常是零和一之间,或者使得每个特征的最大绝对值被缩放为单位大小。这可以通过分别使用 MinMaxScaler 或 MaxAbsScaler 来实现。
使用这种缩放的动机包括对特征极小标准差的鲁棒性以及在稀疏数据中保留零条目。
以下是一个将玩具数据矩阵缩放到 [0, 1] 范围的示例
>>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>> min_max_scaler = preprocessing.MinMaxScaler()
>>> X_train_minmax = min_max_scaler.fit_transform(X_train)
>>> X_train_minmax
array([[0.5 , 0. , 1. ],
[1. , 0.5 , 0.33333333],
[0. , 1. , 0. ]])
然后可以将转换器的同一实例应用于在 fit 调用期间未见过的一些新测试数据:将应用相同的缩放和平移操作,以与在训练数据上执行的转换保持一致。
>>> X_test = np.array([[-3., -1., 4.]])
>>> X_test_minmax = min_max_scaler.transform(X_test)
>>> X_test_minmax
array([[-1.5 , 0. , 1.66666667]])
可以检查缩放器属性以了解在训练数据上学习到的转换的确切性质
>>> min_max_scaler.scale_
array([0.5 , 0.5 , 0.33])
>>> min_max_scaler.min_
array([0. , 0.5 , 0.33])
如果 MinMaxScaler 给定了一个明确的 feature_range=(min, max),完整公式为
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min
MaxAbsScaler 的工作方式非常相似,但它通过除以每个特征中最大的最大值,将训练数据缩放到 [-1, 1] 范围。它适用于已经居中于零或稀疏的数据。
以下是如何使用前一个示例中的玩具数据和此缩放器
>>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>> max_abs_scaler = preprocessing.MaxAbsScaler()
>>> X_train_maxabs = max_abs_scaler.fit_transform(X_train)
>>> X_train_maxabs
array([[ 0.5, -1. , 1. ],
[ 1. , 0. , 0. ],
[ 0. , 1. , -0.5]])
>>> X_test = np.array([[ -3., -1., 4.]])
>>> X_test_maxabs = max_abs_scaler.transform(X_test)
>>> X_test_maxabs
array([[-1.5, -1. , 2. ]])
>>> max_abs_scaler.scale_
array([2., 1., 2.])
7.3.1.2. 稀疏数据缩放#
稀疏数据居中会破坏数据中的稀疏结构,因此很少是明智之举。然而,缩放稀疏输入可能是有意义的,特别是当特征处于不同尺度时。
MaxAbsScaler 专门设计用于缩放稀疏数据,是处理此问题的推荐方法。然而,StandardScaler 可以接受 scipy.sparse 矩阵作为输入,只要明确将 with_mean=False 传递给构造函数即可。否则,将引发 ValueError,因为默默地居中会破坏稀疏性,并经常由于无意中分配过多的内存而导致执行崩溃。RobustScaler 无法拟合稀疏输入,但您可以在稀疏输入上使用 transform 方法。
请注意,缩放器同时接受压缩稀疏行和压缩稀疏列格式(参见 scipy.sparse.csr_matrix 和 scipy.sparse.csc_matrix)。任何其他稀疏输入都将**转换为压缩稀疏行表示**。为了避免不必要的内存复制,建议在上游选择CSR或CSC表示。
最后,如果预计居中后的数据足够小,则使用稀疏矩阵的 toarray 方法将输入显式转换为数组是另一种选择。
7.3.1.3. 对含异常值数据进行缩放#
如果您的数据包含许多异常值,使用数据的均值和方差进行缩放可能效果不佳。在这些情况下,您可以使用 RobustScaler 作为替代。它使用更鲁棒的估计量来计算数据的中心和范围。
参考文献#
关于数据居中和缩放重要性的进一步讨论可在此FAQ中找到:我应该对数据进行归一化/标准化/重新缩放吗?
7.3.1.4. 居中核矩阵#
如果您有一个核 \(K\) 的核矩阵,该核在由函数 \(\phi(\cdot)\) 定义的特征空间中(可能隐式地)计算点积,则 KernelCenterer 可以转换核矩阵,使其包含由 \(\phi\) 定义的特征空间中的内积,然后移除该空间中的均值。换句话说,KernelCenterer 计算与正半定核 \(K\) 关联的居中Gram矩阵。
数学公式#
现在我们有了直观理解,我们可以看看数学公式。让 \(K\) 是在 fit 步骤中由形状为 (n_samples, n_features) 的数据矩阵 \(X\) 计算得到的形状为 (n_samples, n_samples) 的核矩阵。\(K\) 定义为
\(\phi(X)\) 是将 \(X\) 映射到希尔伯特空间的函数。居中核 \(\tilde{K}\) 定义为
其中 \(\tilde{\phi}(X)\) 是在希尔伯特空间中对 \(\phi(X)\) 进行居中操作的结果。
因此,可以通过使用函数 \(\phi(\cdot)\) 映射 \(X\) 并在新空间中居中数据来计算 \(\tilde{K}\)。然而,核通常用于避免使用 \(\phi(\cdot)\) 显式计算此映射的一些代数计算。事实上,可以像 [Scholkopf1998] 附录B中所示那样隐式居中
\(1_{\text{n}_{samples}}\) 是一个形状为 (n_samples, n_samples) 的矩阵,其中所有条目都等于 \(\frac{1}{\text{n}_{samples}}\)。在 transform 步骤中,核变为 \(K_{test}(X, Y)\),定义为
\(Y\) 是形状为 (n_samples_test, n_features) 的测试数据集,因此 \(K_{test}\) 的形状为 (n_samples_test, n_samples)。在这种情况下,居中 \(K_{test}\) 的操作如下
\(1'_{\text{n}_{samples}}\) 是一个形状为 (n_samples_test, n_samples) 的矩阵,其中所有条目都等于 \(\frac{1}{\text{n}_{samples}}\)。
参考文献
B. Schölkopf, A. Smola, and K.R. Müller, “Nonlinear component analysis as a kernel eigenvalue problem.” Neural computation 10.5 (1998): 1299-1319.
7.3.2. 非线性转换#
有两种类型的转换可用:分位数转换和幂转换。分位数转换和幂转换都基于特征的单调转换,因此保留了每个特征值的秩。
分位数转换根据公式 \(G^{-1}(F(X))\) 将所有特征转换为相同的所需分布,其中 \(F\) 是特征的累积分布函数,\(G^{-1}\) 是所需输出分布 \(G\) 的 分位数函数。这个公式使用了以下两个事实:(i) 如果 \(X\) 是一个具有连续累积分布函数 \(F\) 的随机变量,那么 \(F(X)\) 在 \([0,1]\) 上均匀分布;(ii) 如果 \(U\) 是一个在 \([0,1]\) 上均匀分布的随机变量,那么 \(G^{-1}(U)\) 具有分布 \(G\)。通过执行秩转换,分位数转换平滑了异常分布,并且比缩放方法受异常值的影响更小。但是,它会扭曲特征内部和特征之间的相关性和距离。
幂转换是一系列参数转换,旨在将任何分布的数据映射到尽可能接近高斯分布。
7.3.2.1. 映射到均匀分布#
QuantileTransformer 提供了一种非参数转换,用于将数据映射到介于0和1之间的均匀分布
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import train_test_split
>>> X, y = load_iris(return_X_y=True)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
>>> quantile_transformer = preprocessing.QuantileTransformer(random_state=0)
>>> X_train_trans = quantile_transformer.fit_transform(X_train)
>>> X_test_trans = quantile_transformer.transform(X_test)
>>> np.percentile(X_train[:, 0], [0, 25, 50, 75, 100])
array([ 4.3, 5.1, 5.8, 6.5, 7.9])
此特征对应于以厘米为单位的萼片长度。应用分位数转换后,这些标志点接近先前定义的分位数。
>>> np.percentile(X_train_trans[:, 0], [0, 25, 50, 75, 100])
...
array([ 0.00 , 0.24, 0.49, 0.73, 0.99 ])
这可以在具有类似备注的独立测试集上得到证实。
>>> np.percentile(X_test[:, 0], [0, 25, 50, 75, 100])
...
array([ 4.4 , 5.125, 5.75 , 6.175, 7.3 ])
>>> np.percentile(X_test_trans[:, 0], [0, 25, 50, 75, 100])
...
array([ 0.01, 0.25, 0.46, 0.60 , 0.94])
7.3.2.2. 映射到高斯分布#
在许多建模场景中,数据集特征的正态性是可取的。幂变换是一系列参数化的单调变换,旨在将任何分布的数据映射到尽可能接近高斯分布,以稳定方差并最小化偏度。
PowerTransformer 目前提供了两种这样的幂变换:Yeo-Johnson 变换和 Box-Cox 变换。
Yeo-Johnson 变换#
Box-Cox 变换#
Box-Cox 只能应用于严格正数数据。在这两种方法中,变换都由 \(\lambda\) 参数化,\(\lambda\) 通过最大似然估计确定。以下是使用 Box-Cox 将从对数正态分布中抽取的样本映射到正态分布的示例
>>> pt = preprocessing.PowerTransformer(method='box-cox', standardize=False)
>>> X_lognormal = np.random.RandomState(616).lognormal(size=(3, 3))
>>> X_lognormal
array([[1.28, 1.18 , 0.84 ],
[0.94, 1.60 , 0.388],
[1.35, 0.217, 1.09 ]])
>>> pt.fit_transform(X_lognormal)
array([[ 0.49 , 0.179, -0.156],
[-0.051, 0.589, -0.576],
[ 0.69 , -0.849, 0.101]])
尽管上述示例将 standardize 选项设置为 False,PowerTransformer 默认将对转换后的输出应用零均值、单位方差归一化。
以下是Box-Cox和Yeo-Johnson应用于各种概率分布的例子。请注意,当应用于某些分布时,幂变换能实现非常接近高斯分布的结果,但对于其他分布,它们则无效。这强调了在变换前后对数据进行可视化的重要性。
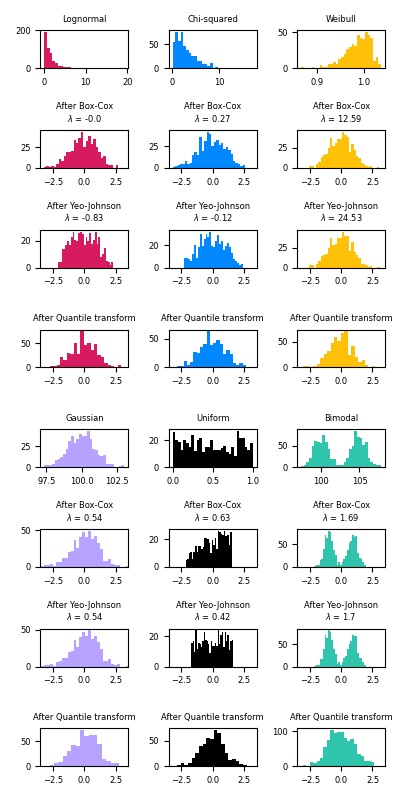
通过设置 output_distribution='normal',也可以使用 QuantileTransformer 将数据映射到正态分布。使用 Iris 数据集的早期示例
>>> quantile_transformer = preprocessing.QuantileTransformer(
... output_distribution='normal', random_state=0)
>>> X_trans = quantile_transformer.fit_transform(X)
>>> quantile_transformer.quantiles_
array([[4.3, 2. , 1. , 0.1],
[4.4, 2.2, 1.1, 0.1],
[4.4, 2.2, 1.2, 0.1],
...,
[7.7, 4.1, 6.7, 2.5],
[7.7, 4.2, 6.7, 2.5],
[7.9, 4.4, 6.9, 2.5]])
因此,输入的中间值变成输出的均值,居中于0。正态输出被剪裁,以使输入的最小值和最大值——分别对应于 1e-7 和 1 - 1e-7 分位数——在转换下不会变为无穷大。
7.3.3. 归一化#
**归一化**是**将单个样本缩放到单位范数**的过程。如果您计划使用二次形式(例如点积或任何其他核)来量化任意一对样本的相似性,此过程可能很有用。
此假设是 向量空间模型 的基础,该模型常用于文本分类和聚类上下文中。
函数 normalize 提供了一种快速简便的方法,可以在单个类数组数据集上执行此操作,可以使用 l1、l2 或 max 范数
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> X_normalized = preprocessing.normalize(X, norm='l2')
>>> X_normalized
array([[ 0.408, -0.408, 0.812],
[ 1. , 0. , 0. ],
[ 0. , 0.707, -0.707]])
preprocessing 模块还提供了一个实用类 Normalizer,它使用 Transformer API 实现相同的操作(尽管在这种情况下 fit 方法是无用的:该类是无状态的,因为此操作独立处理样本)。
因此,该类适用于 Pipeline 的早期步骤。
>>> normalizer = preprocessing.Normalizer().fit(X) # fit does nothing
>>> normalizer
Normalizer()
然后可以将归一化器实例应用于样本向量,就像任何转换器一样。
>>> normalizer.transform(X)
array([[ 0.408, -0.408, 0.812],
[ 1. , 0. , 0. ],
[ 0. , 0.707, -0.707]])
>>> normalizer.transform([[-1., 1., 0.]])
array([[-0.707, 0.707, 0.]])
注意:L2 归一化也称为空间符号预处理。
稀疏输入#
normalize 和 Normalizer **同时接受密集类数组和来自 scipy.sparse 的稀疏矩阵作为输入**。
对于稀疏输入,数据在被送入高效的Cython例程之前**转换为压缩稀疏行表示**(参见 scipy.sparse.csr_matrix)。为了避免不必要的内存复制,建议在上游选择CSR表示。
7.3.4. 编码类别特征#
通常,特征并非以连续值形式给出,而是以类别形式给出。例如,一个人可以有特征 ["male", "female"]、["from Europe", "from US", "from Asia"]、["uses Firefox", "uses Chrome", "uses Safari", "uses Internet Explorer"]。这些特征可以有效地编码为整数,例如 ["male", "from US", "uses Internet Explorer"] 可以表示为 [0, 1, 3],而 ["female", "from Asia", "uses Chrome"] 则为 [1, 2, 1]。
要将类别特征转换为此类整数编码,我们可以使用 OrdinalEncoder。此估计器将每个类别特征转换为一个新的整数特征(0到 n_categories - 1)
>>> enc = preprocessing.OrdinalEncoder()
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OrdinalEncoder()
>>> enc.transform([['female', 'from US', 'uses Safari']])
array([[0., 1., 1.]])
然而,这样的整数表示不能直接用于所有 scikit-learn 估计器,因为这些估计器期望连续输入,并且会将类别解释为有序的,这通常是不希望的(即,浏览器集合是任意排序的)。
默认情况下,OrdinalEncoder 还会透传由 np.nan 指示的缺失值。
>>> enc = preprocessing.OrdinalEncoder()
>>> X = [['male'], ['female'], [np.nan], ['female']]
>>> enc.fit_transform(X)
array([[ 1.],
[ 0.],
[nan],
[ 0.]])
OrdinalEncoder 提供了一个参数 encoded_missing_value,用于编码缺失值,无需创建管道和使用 SimpleImputer。
>>> enc = preprocessing.OrdinalEncoder(encoded_missing_value=-1)
>>> X = [['male'], ['female'], [np.nan], ['female']]
>>> enc.fit_transform(X)
array([[ 1.],
[ 0.],
[-1.],
[ 0.]])
上述处理等同于以下管道
>>> from sklearn.pipeline import Pipeline
>>> from sklearn.impute import SimpleImputer
>>> enc = Pipeline(steps=[
... ("encoder", preprocessing.OrdinalEncoder()),
... ("imputer", SimpleImputer(strategy="constant", fill_value=-1)),
... ])
>>> enc.fit_transform(X)
array([[ 1.],
[ 0.],
[-1.],
[ 0.]])
将类别特征转换为可用于 scikit-learn 估计器的另一种可能性是使用 One-of-K 编码,也称为 One-hot 或虚拟编码。这种类型的编码可以通过 OneHotEncoder 获得,它将每个具有 n_categories 个可能值的类别特征转换为 n_categories 个二进制特征,其中一个为 1,其余为 0。
继续上面的例子
>>> enc = preprocessing.OneHotEncoder()
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OneHotEncoder()
>>> enc.transform([['female', 'from US', 'uses Safari'],
... ['male', 'from Europe', 'uses Safari']]).toarray()
array([[1., 0., 0., 1., 0., 1.],
[0., 1., 1., 0., 0., 1.]])
默认情况下,每个特征可以取的值是从数据集中自动推断出来的,可以在 categories_ 属性中找到
>>> enc.categories_
[array(['female', 'male'], dtype=object), array(['from Europe', 'from US'], dtype=object), array(['uses Firefox', 'uses Safari'], dtype=object)]
可以通过 categories 参数明确指定这一点。在我们的数据集中,有两种性别,四种可能的洲和四种网络浏览器。
>>> genders = ['female', 'male']
>>> locations = ['from Africa', 'from Asia', 'from Europe', 'from US']
>>> browsers = ['uses Chrome', 'uses Firefox', 'uses IE', 'uses Safari']
>>> enc = preprocessing.OneHotEncoder(categories=[genders, locations, browsers])
>>> # Note that for there are missing categorical values for the 2nd and 3rd
>>> # feature
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OneHotEncoder(categories=[['female', 'male'],
['from Africa', 'from Asia', 'from Europe',
'from US'],
['uses Chrome', 'uses Firefox', 'uses IE',
'uses Safari']])
>>> enc.transform([['female', 'from Asia', 'uses Chrome']]).toarray()
array([[1., 0., 0., 1., 0., 0., 1., 0., 0., 0.]])
如果训练数据可能包含缺失的类别特征,通常最好指定 handle_unknown='infrequent_if_exist' 而不是如上所述手动设置 categories。当指定 handle_unknown='infrequent_if_exist' 并且在转换期间遇到未知类别时,不会引发错误,但该特征的结果独热编码列将全部为零,或者如果启用则被视为不常见类别。(handle_unknown='infrequent_if_exist' 仅支持独热编码)
>>> enc = preprocessing.OneHotEncoder(handle_unknown='infrequent_if_exist')
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OneHotEncoder(handle_unknown='infrequent_if_exist')
>>> enc.transform([['female', 'from Asia', 'uses Chrome']]).toarray()
array([[1., 0., 0., 0., 0., 0.]])
通过使用 drop 参数,也可以将每列编码为 n_categories - 1 列而不是 n_categories 列。此参数允许用户为要删除的每个特征指定一个类别。这对于避免某些分类器中输入矩阵的共线性很有用。例如,当使用非正则化回归(LinearRegression)时,这种功能很有用,因为共线性会导致协方差矩阵不可逆。
>>> X = [['male', 'from US', 'uses Safari'],
... ['female', 'from Europe', 'uses Firefox']]
>>> drop_enc = preprocessing.OneHotEncoder(drop='first').fit(X)
>>> drop_enc.categories_
[array(['female', 'male'], dtype=object), array(['from Europe', 'from US'], dtype=object),
array(['uses Firefox', 'uses Safari'], dtype=object)]
>>> drop_enc.transform(X).toarray()
array([[1., 1., 1.],
[0., 0., 0.]])
对于只有两个类别的特征,可能只想删除其中一列。在这种情况下,可以将参数 drop='if_binary'。
>>> X = [['male', 'US', 'Safari'],
... ['female', 'Europe', 'Firefox'],
... ['female', 'Asia', 'Chrome']]
>>> drop_enc = preprocessing.OneHotEncoder(drop='if_binary').fit(X)
>>> drop_enc.categories_
[array(['female', 'male'], dtype=object), array(['Asia', 'Europe', 'US'], dtype=object),
array(['Chrome', 'Firefox', 'Safari'], dtype=object)]
>>> drop_enc.transform(X).toarray()
array([[1., 0., 0., 1., 0., 0., 1.],
[0., 0., 1., 0., 0., 1., 0.],
[0., 1., 0., 0., 1., 0., 0.]])
在转换后的 X 中,第一列是带有“male”/“female”类别的特征的编码,而剩余的6列是分别带有3个类别的2个特征的编码。
当 handle_unknown='ignore' 且 drop 不为 None 时,未知类别将被编码为全零
>>> drop_enc = preprocessing.OneHotEncoder(drop='first',
... handle_unknown='ignore').fit(X)
>>> X_test = [['unknown', 'America', 'IE']]
>>> drop_enc.transform(X_test).toarray()
array([[0., 0., 0., 0., 0.]])
X_test 中的所有类别在转换期间都是未知的,并将映射为全零。这意味着未知类别将具有与被丢弃类别相同的映射。OneHotEncoder.inverse_transform 如果丢弃了类别,会将全零映射到被丢弃的类别;如果未丢弃类别,则映射为 None。
>>> drop_enc = preprocessing.OneHotEncoder(drop='if_binary', sparse_output=False,
... handle_unknown='ignore').fit(X)
>>> X_test = [['unknown', 'America', 'IE']]
>>> X_trans = drop_enc.transform(X_test)
>>> X_trans
array([[0., 0., 0., 0., 0., 0., 0.]])
>>> drop_enc.inverse_transform(X_trans)
array([['female', None, None]], dtype=object)
支持带有缺失值的类别特征#
OneHotEncoder 通过将缺失值视为一个额外类别来支持带有缺失值的类别特征
>>> X = [['male', 'Safari'],
... ['female', None],
... [np.nan, 'Firefox']]
>>> enc = preprocessing.OneHotEncoder(handle_unknown='error').fit(X)
>>> enc.categories_
[array(['female', 'male', nan], dtype=object),
array(['Firefox', 'Safari', None], dtype=object)]
>>> enc.transform(X).toarray()
array([[0., 1., 0., 0., 1., 0.],
[1., 0., 0., 0., 0., 1.],
[0., 0., 1., 1., 0., 0.]])
如果一个特征同时包含 np.nan 和 None,它们将被视为独立的类别
>>> X = [['Safari'], [None], [np.nan], ['Firefox']]
>>> enc = preprocessing.OneHotEncoder(handle_unknown='error').fit(X)
>>> enc.categories_
[array(['Firefox', 'Safari', None, nan], dtype=object)]
>>> enc.transform(X).toarray()
array([[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.],
[1., 0., 0., 0.]])
有关表示为字典而非标量的类别特征,请参阅 从字典加载特征。
7.3.4.1. 不常见类别#
OneHotEncoder 和 OrdinalEncoder 支持将不常见类别聚合为每个特征的单个输出。启用不常见类别聚合的参数是 min_frequency 和 max_categories。
min_frequency可以是一个大于或等于1的整数,也可以是一个在(0.0, 1.0)区间内的浮点数。如果min_frequency是一个整数,则基数小于min_frequency的类别将被视为不常见。如果min_frequency是一个浮点数,则基数小于总样本数这一比例的类别将被视为不常见。默认值为1,这意味着每个类别都单独编码。max_categories可以是None或任何大于1的整数。此参数为每个输入特征的输出特征数量设置了上限。max_categories包含组合不常见特征的特征。
在以下使用 OrdinalEncoder 的示例中,类别 'dog' 和 'snake' 被认为是不常见类别
>>> X = np.array([['dog'] * 5 + ['cat'] * 20 + ['rabbit'] * 10 +
... ['snake'] * 3], dtype=object).T
>>> enc = preprocessing.OrdinalEncoder(min_frequency=6).fit(X)
>>> enc.infrequent_categories_
[array(['dog', 'snake'], dtype=object)]
>>> enc.transform(np.array([['dog'], ['cat'], ['rabbit'], ['snake']]))
array([[2.],
[0.],
[1.],
[2.]])
OrdinalEncoder 的 max_categories **不**考虑缺失或未知类别。将 unknown_value 或 encoded_missing_value 设置为整数将使唯一整数代码的数量各增加一个。这可能导致最多 max_categories + 2 个整数代码。在以下示例中,“a”和“d”被认为是不常见并分组为一个类别,“b”和“c”是它们自己的类别,未知值编码为3,缺失值编码为4。
>>> X_train = np.array(
... [["a"] * 5 + ["b"] * 20 + ["c"] * 10 + ["d"] * 3 + [np.nan]],
... dtype=object).T
>>> enc = preprocessing.OrdinalEncoder(
... handle_unknown="use_encoded_value", unknown_value=3,
... max_categories=3, encoded_missing_value=4)
>>> _ = enc.fit(X_train)
>>> X_test = np.array([["a"], ["b"], ["c"], ["d"], ["e"], [np.nan]], dtype=object)
>>> enc.transform(X_test)
array([[2.],
[0.],
[1.],
[2.],
[3.],
[4.]])
类似地,OneHotEncoder 可以配置为将不常见类别分组
>>> enc = preprocessing.OneHotEncoder(min_frequency=6, sparse_output=False).fit(X)
>>> enc.infrequent_categories_
[array(['dog', 'snake'], dtype=object)]
>>> enc.transform(np.array([['dog'], ['cat'], ['rabbit'], ['snake']]))
array([[0., 0., 1.],
[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
通过将 handle_unknown 设置为 'infrequent_if_exist',未知类别将被视为不常见类别
>>> enc = preprocessing.OneHotEncoder(
... handle_unknown='infrequent_if_exist', sparse_output=False, min_frequency=6)
>>> enc = enc.fit(X)
>>> enc.transform(np.array([['dragon']]))
array([[0., 0., 1.]])
OneHotEncoder.get_feature_names_out 使用“infrequent”作为不常见特征名称
>>> enc.get_feature_names_out()
array(['x0_cat', 'x0_rabbit', 'x0_infrequent_sklearn'], dtype=object)
当 'handle_unknown' 设置为 'infrequent_if_exist' 且在转换中遇到未知类别时
如果未配置不常见类别支持,或者在训练期间没有不常见类别,则此特征的结果独热编码列将全部为零。在逆转换中,未知类别将表示为
None。如果在训练期间存在不常见类别,未知类别将被视为不常见类别。在逆变换中,'infrequent_sklearn' 将用于表示不常见类别。
不常见类别也可以使用 max_categories 进行配置。在以下示例中,我们将 max_categories=2 以限制输出中的特征数量。这将导致除 'cat' 类别外的所有类别都被视为不常见,从而产生两个特征,一个用于 'cat',另一个用于不常见类别(即所有其他类别)。
>>> enc = preprocessing.OneHotEncoder(max_categories=2, sparse_output=False)
>>> enc = enc.fit(X)
>>> enc.transform([['dog'], ['cat'], ['rabbit'], ['snake']])
array([[0., 1.],
[1., 0.],
[0., 1.],
[0., 1.]])
如果 max_categories 和 min_frequency 都不是默认值,则首先根据 min_frequency 选择类别,然后保留 max_categories 个类别。在以下示例中,min_frequency=4 仅将 snake 视为不常见,但 max_categories=3 强制 dog 也变得不常见。
>>> enc = preprocessing.OneHotEncoder(min_frequency=4, max_categories=3, sparse_output=False)
>>> enc = enc.fit(X)
>>> enc.transform([['dog'], ['cat'], ['rabbit'], ['snake']])
array([[0., 0., 1.],
[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
如果在 max_categories 的截止点处存在基数相同的不常见类别,则根据词典顺序取前 max_categories 个。在以下示例中,“b”、“c”和“d”具有相同的基数,并且在 max_categories=2 的情况下,“b”和“c”是不常见的,因为它们具有更高的词典顺序。
>>> X = np.asarray([["a"] * 20 + ["b"] * 10 + ["c"] * 10 + ["d"] * 10], dtype=object).T
>>> enc = preprocessing.OneHotEncoder(max_categories=3).fit(X)
>>> enc.infrequent_categories_
[array(['b', 'c'], dtype=object)]
7.3.4.2. 目标编码器#
TargetEncoder 使用以类别特征为条件的目标均值来编码无序类别,即名义类别 [PAR] [MIC]。这种编码方案对于高基数的类别特征很有用,因为独热编码会膨胀特征空间,使得下游模型处理起来更昂贵。高基数类别的经典例子是基于位置的,如邮政编码或区域。
二分类目标#
对于二分类目标,目标编码由下式给出
其中 \(S_i\) 是类别 \(i\) 的编码,\(n_{iY}\) 是 \(Y=1\) 且类别为 \(i\) 的观测数量,\(n_i\) 是类别为 \(i\) 的观测数量,\(n_Y\) 是 \(Y=1\) 的观测数量,\(n\) 是观测总数,\(\lambda_i\) 是类别 \(i\) 的收缩因子。收缩因子由下式给出
其中 \(m\) 是平滑因子,由 TargetEncoder 的 smooth 参数控制。较大的平滑因子将更侧重于全局均值。当 smooth="auto" 时,平滑因子计算为经验贝叶斯估计:\(m=\sigma_i^2/\tau^2\),其中 \(\sigma_i^2\) 是 y 在类别 \(i\) 下的方差,\(\tau^2\) 是 y 的全局方差。
多分类目标#
对于多分类目标,公式与二分类类似
其中 \(S_{ij}\) 是类别 \(i\) 和类别 \(j\) 的编码,\(n_{iY_j}\) 是 \(Y=j\) 且类别为 \(i\) 的观测数量,\(n_i\) 是类别为 \(i\) 的观测数量,\(n_{Y_j}\) 是 \(Y=j\) 的观测数量,\(n\) 是观测总数,\(\lambda_i\) 是类别 \(i\) 的收缩因子。
连续目标#
对于连续目标,公式与二分类类似
其中 \(L_i\) 是类别 \(i\) 的观测集合,\(n_i\) 是类别 \(i\) 的观测数量。
fit_transform 内部依赖于 交叉拟合 方案,以防止目标信息泄漏到训练时表示中,特别是对于非信息性高基数类别变量,并有助于防止下游模型过拟合虚假相关性。请注意,因此,fit(X, y).transform(X) 不等于 fit_transform(X, y)。在 fit_transform 中,训练数据被分成 k 折(由 cv 参数确定),每折都使用从其他 k-1 折学习到的编码进行编码。下图显示了 fit_transform 中默认 cv=5 的 交叉拟合 方案。

fit_transform 也使用整个训练集学习“全数据”编码。这在 fit_transform 中从不使用,但保存到属性 encodings_ 中,以备调用 transform 时使用。请注意,在 交叉拟合 方案期间为每折学习到的编码不会保存到属性中。
fit 方法**不**使用任何 交叉拟合 方案,并在整个训练集上学习一个编码,该编码用于在 transform 中对类别进行编码。此编码与 fit_transform 中学习到的“全数据”编码相同。
注意
TargetEncoder 将缺失值(如 np.nan 或 None)视为另一个类别,并像其他类别一样对其进行编码。在 fit 期间未见过的类别将使用目标均值进行编码,即 target_mean_。
示例
参考文献
7.3.5. 离散化#
离散化(也称为量化或分箱)提供了一种将连续特征划分为离散值的方法。某些具有连续特征的数据集可能会受益于离散化,因为离散化可以将连续属性的数据集转换为仅具有标称属性的数据集。
独热编码的离散化特征可以使模型更具表现力,同时保持可解释性。例如,使用离散化器进行预处理可以为线性模型引入非线性。有关更高级的可能性,特别是平滑的可能性,请参阅下面的 生成多项式特征。
7.3.5.1. K-bins 离散化#
KBinsDiscretizer 将特征离散化为 k 个箱
>>> X = np.array([[ -3., 5., 15 ],
... [ 0., 6., 14 ],
... [ 6., 3., 11 ]])
>>> est = preprocessing.KBinsDiscretizer(n_bins=[3, 2, 2], encode='ordinal').fit(X)
默认情况下,输出被独热编码为稀疏矩阵(参见 编码类别特征),这可以通过 encode 参数进行配置。对于每个特征,箱边缘在 fit 期间计算,并与箱的数量一起定义区间。因此,对于当前示例,这些区间定义为
特征 1:\({[-\infty, -1), [-1, 2), [2, \infty)}\)
特征 2:\({[-\infty, 5), [5, \infty)}\)
特征 3:\({[-\infty, 14), [14, \infty)}\)
基于这些箱区间,X 转换如下
>>> est.transform(X)
array([[ 0., 1., 1.],
[ 1., 1., 1.],
[ 2., 0., 0.]])
结果数据集包含有序属性,可在 Pipeline 中进一步使用。
离散化类似于为连续数据构建直方图。然而,直方图侧重于计数落入特定箱的特征,而离散化侧重于将特征值分配给这些箱。
KBinsDiscretizer 实现了不同的分箱策略,可以通过 strategy 参数选择。“uniform”策略使用固定宽度的箱。“quantile”策略使用分位数,使得每个特征中的箱填充相等。“kmeans”策略基于对每个特征独立执行的k-means聚类过程定义箱。
请注意,可以通过向 FunctionTransformer 传入一个定义离散化策略的可调用对象来指定自定义箱。例如,我们可以使用 Pandas 函数 pandas.cut
>>> import pandas as pd
>>> import numpy as np
>>> from sklearn import preprocessing
>>>
>>> bins = [0, 1, 13, 20, 60, np.inf]
>>> labels = ['infant', 'kid', 'teen', 'adult', 'senior citizen']
>>> transformer = preprocessing.FunctionTransformer(
... pd.cut, kw_args={'bins': bins, 'labels': labels, 'retbins': False}
... )
>>> X = np.array([0.2, 2, 15, 25, 97])
>>> transformer.fit_transform(X)
['infant', 'kid', 'teen', 'adult', 'senior citizen']
Categories (5, object): ['infant' < 'kid' < 'teen' < 'adult' < 'senior citizen']
示例
7.3.5.2. 特征二值化#
**特征二值化**是**将数值特征阈值化以获得布尔值**的过程。这对于下游概率估计器可能很有用,因为它们假设输入数据根据多元 伯努利分布 分布。例如,BernoulliRBM 就是这种情况。
在文本处理领域,使用二值特征值也很常见(可能是为了简化概率推理),尽管归一化计数(又称词频)或TF-IDF值特征在实践中通常表现略好。
至于 Normalizer,预处理模块提供了实用类 Binarizer,旨在用于 Pipeline 的早期阶段。fit 方法不执行任何操作,因为每个样本都是独立于其他样本处理的。
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> binarizer = preprocessing.Binarizer().fit(X) # fit does nothing
>>> binarizer
Binarizer()
>>> binarizer.transform(X)
array([[1., 0., 1.],
[1., 0., 0.],
[0., 1., 0.]])
可以调整二值化器的阈值
>>> binarizer = preprocessing.Binarizer(threshold=1.1)
>>> binarizer.transform(X)
array([[0., 0., 1.],
[1., 0., 0.],
[0., 0., 0.]])
与 Normalizer 类一样,预处理模块提供了一个辅助函数 binarize,用于不需要转换器API的情况。
请注意,Binarizer 与 KBinsDiscretizer 相似,当 k = 2 且 bin 边缘位于 threshold 值时。
7.3.6. 缺失值填充#
缺失值填充工具在 缺失值填充 中讨论。
7.3.7. 生成多项式特征#
通常,通过考虑输入数据的非线性特征来增加模型复杂度是很有用的。我们展示两种基于多项式的可能性:第一种使用纯多项式,第二种使用样条,即分段多项式。
7.3.7.1. 多项式特征#
一种简单常用的方法是多项式特征,它可以获取特征的高阶和交互项。它在 PolynomialFeatures 中实现
>>> import numpy as np
>>> from sklearn.preprocessing import PolynomialFeatures
>>> X = np.arange(6).reshape(3, 2)
>>> X
array([[0, 1],
[2, 3],
[4, 5]])
>>> poly = PolynomialFeatures(2)
>>> poly.fit_transform(X)
array([[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.]])
X的特征已从 \((X_1, X_2)\) 转换为 \((1, X_1, X_2, X_1^2, X_1X_2, X_2^2)\)。
在某些情况下,只需要特征之间的交互项,通过设置 interaction_only=True 即可获得。
>>> X = np.arange(9).reshape(3, 3)
>>> X
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> poly = PolynomialFeatures(degree=3, interaction_only=True)
>>> poly.fit_transform(X)
array([[ 1., 0., 1., 2., 0., 0., 2., 0.],
[ 1., 3., 4., 5., 12., 15., 20., 60.],
[ 1., 6., 7., 8., 42., 48., 56., 336.]])
X 的特征已从 \((X_1, X_2, X_3)\) 转换为 \((1, X_1, X_2, X_3, X_1X_2, X_1X_3, X_2X_3, X_1X_2X_3)\)。
请注意,在使用多项式核函数时,多项式特征在核方法(例如,SVC、KernelPCA)中隐式使用。
请参阅多项式和样条插值,了解如何使用生成的多项式特征进行岭回归。
7.3.7.2. 样条变换器#
添加非线性项而非纯特征多项式的另一种方法是使用 SplineTransformer 为每个特征生成样条基函数。样条是分段多项式,由其多项式次数和节(knots)的位置参数化。该 SplineTransformer 实现了B样条基,参见下面的参考文献。
注意
该 SplineTransformer 单独处理每个特征,即它不会提供交互项。
样条相对于多项式的一些优势是:
B样条非常灵活和稳健,如果您保持固定的低次数(通常为3),并适度调整节点数量。多项式需要更高的次数,这引出了下一点。
B样条在边界处没有像多项式那样(次数越高,情况越糟)的振荡行为。这被称为龙格现象。
B样条为超出边界(即超出拟合值范围)的外推提供了很好的选择。请查看选项
extrapolation。B样条生成一个带状结构的特征矩阵。对于单个特征,每行只包含
degree + 1个非零元素,它们连续出现且都是正数。这会产生一个具有良好数值特性(例如,低条件数)的矩阵,与多项式矩阵(被称为范德蒙矩阵)形成鲜明对比。低条件数对于线性模型的稳定算法很重要。
以下代码片段展示了样条的应用
>>> import numpy as np
>>> from sklearn.preprocessing import SplineTransformer
>>> X = np.arange(5).reshape(5, 1)
>>> X
array([[0],
[1],
[2],
[3],
[4]])
>>> spline = SplineTransformer(degree=2, n_knots=3)
>>> spline.fit_transform(X)
array([[0.5 , 0.5 , 0. , 0. ],
[0.125, 0.75 , 0.125, 0. ],
[0. , 0.5 , 0.5 , 0. ],
[0. , 0.125, 0.75 , 0.125],
[0. , 0. , 0.5 , 0.5 ]])
由于 X 已排序,可以很容易地看到带状矩阵输出。对于 degree=2,只有中间三个对角线是非零的。次数越高,样条的重叠度越大。
有趣的是,当 knots = strategy 时,degree=0 的 SplineTransformer 与 KBinsDiscretizer 在 encode='onehot-dense' 且 n_bins = n_knots - 1 的情况下是相同的。
示例
参考文献#
Eilers, P., & Marx, B. (1996). Flexible Smoothing with B-splines and Penalties. Statist. Sci. 11 (1996), no. 2, 89–121.
Perperoglou, A., Sauerbrei, W., Abrahamowicz, M. et al. A review of spline function procedures in R. BMC Med Res Methodol 19, 46 (2019).
7.3.8. 自定义变换器#
通常,您会希望将现有的 Python 函数转换为变换器,以协助数据清洗或处理。您可以使用 FunctionTransformer 来实现任意函数的变换器。例如,要在管道中构建一个应用对数变换的变换器,请执行以下操作:
>>> import numpy as np
>>> from sklearn.preprocessing import FunctionTransformer
>>> transformer = FunctionTransformer(np.log1p, validate=True)
>>> X = np.array([[0, 1], [2, 3]])
>>> # Since FunctionTransformer is no-op during fit, we can call transform directly
>>> transformer.transform(X)
array([[0. , 0.69314718],
[1.09861229, 1.38629436]])
您可以通过设置 check_inverse=True 并在调用 transform 之前调用 fit 来确保 func 和 inverse_func 互为逆函数。请注意,这会引发警告,并且可以通过 filterwarnings 将其转换为错误。
>>> import warnings
>>> warnings.filterwarnings("error", message=".*check_inverse*.",
... category=UserWarning, append=False)
有关使用 FunctionTransformer 从文本数据中提取特征的完整代码示例,请参阅使用异构数据源的列变换器和时间相关特征工程。