3.5. 验证曲线:绘制分数以评估模型#
每个估计器都有其优点和缺点。其泛化误差可以分解为偏差、方差和噪声。估计器的偏差是其在不同训练集上的平均误差。估计器的方差表示其对不同训练集的敏感程度。噪声是数据的一种特性。
在下面的图中,我们看到一个函数 \(f(x) = \cos (\frac{3}{2} \pi x)\) 以及该函数的一些带噪声的样本。我们使用三种不同的估计器来拟合该函数:使用1阶、4阶和15阶多项式特征的线性回归。我们看到,第一个估计器最多只能对样本和真实函数提供糟糕的拟合,因为它过于简单(高偏差);第二个估计器几乎完美地近似了它;而最后一个估计器完美地近似了训练数据,但未能很好地拟合真实函数,也就是说,它对变化的训练数据非常敏感(高方差)。
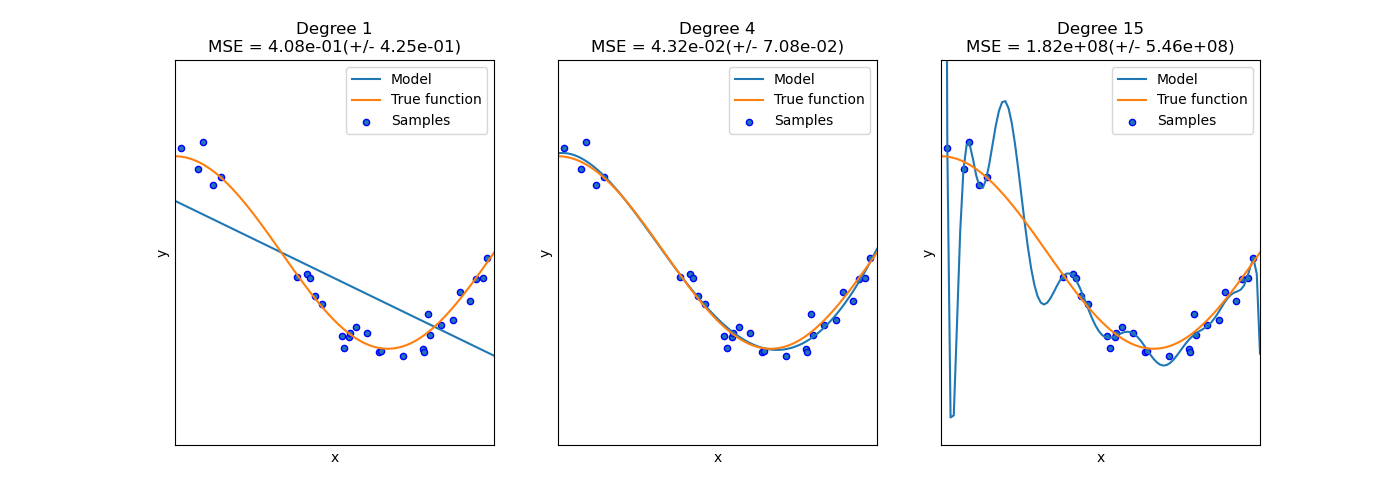
偏差和方差是估计器的固有属性,我们通常必须选择学习算法和超参数,以便偏差和方差都尽可能低(参见偏差-方差困境)。减少模型方差的另一种方法是使用更多的训练数据。然而,只有当真实函数过于复杂,以至于估计器无法以较低的方差近似时,才应该收集更多的训练数据。
在我们示例中看到的简单一维问题中,很容易看出估计器是受偏差还是方差的影响。然而,在高维空间中,模型变得非常难以可视化。因此,使用下面描述的工具通常会很有帮助。
示例
3.5.1. 验证曲线#
要验证模型,我们需要一个评分函数(参见指标和评分:量化预测质量),例如分类器的准确率。选择估计器多个超参数的正确方法当然是网格搜索或类似方法(参见调整估计器的超参数),这些方法会选择在验证集或多个验证集上得分最高的超参数。请注意,如果我们根据验证分数优化超参数,那么验证分数将有偏差,不再是泛化性能的良好估计。要获得对泛化性能的准确估计,我们必须在另一个测试集上计算分数。
然而,有时绘制单个超参数对训练分数和验证分数的影响会很有帮助,以找出估计器是否在某些超参数值下过拟合或欠拟合。
函数validation_curve在这种情况下可以提供帮助。
>>> import numpy as np
>>> from sklearn.model_selection import validation_curve
>>> from sklearn.datasets import load_iris
>>> from sklearn.svm import SVC
>>> np.random.seed(0)
>>> X, y = load_iris(return_X_y=True)
>>> indices = np.arange(y.shape[0])
>>> np.random.shuffle(indices)
>>> X, y = X[indices], y[indices]
>>> train_scores, valid_scores = validation_curve(
... SVC(kernel="linear"), X, y, param_name="C", param_range=np.logspace(-7, 3, 3),
... )
>>> train_scores
array([[0.90, 0.94, 0.91, 0.89, 0.92],
[0.9 , 0.92, 0.93, 0.92, 0.93],
[0.97, 1 , 0.98, 0.97, 0.99]])
>>> valid_scores
array([[0.9, 0.9 , 0.9 , 0.96, 0.9 ],
[0.9, 0.83, 0.96, 0.96, 0.93],
[1. , 0.93, 1 , 1 , 0.9 ]])
如果您只想绘制验证曲线,那么类ValidationCurveDisplay比手动使用matplotlib绘制validation_curve的结果更直接。您可以使用方法from_estimator,类似于validation_curve来生成并绘制验证曲线。
from sklearn.datasets import load_iris
from sklearn.model_selection import ValidationCurveDisplay
from sklearn.svm import SVC
from sklearn.utils import shuffle
X, y = load_iris(return_X_y=True)
X, y = shuffle(X, y, random_state=0)
ValidationCurveDisplay.from_estimator(
SVC(kernel="linear"), X, y, param_name="C", param_range=np.logspace(-7, 3, 10)
)
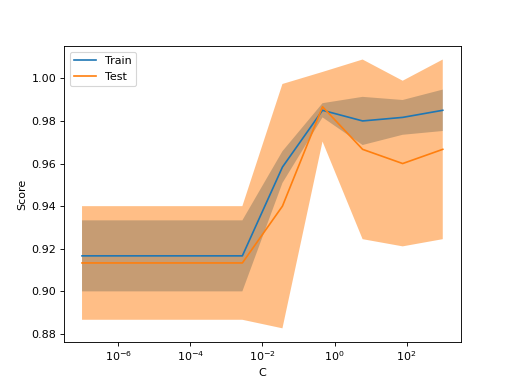
如果训练分数和验证分数都低,则估计器将欠拟合。如果训练分数高而验证分数低,则估计器过拟合;反之,它工作得非常好。低训练分数和高验证分数通常是不可能的。
3.5.2. 学习曲线#
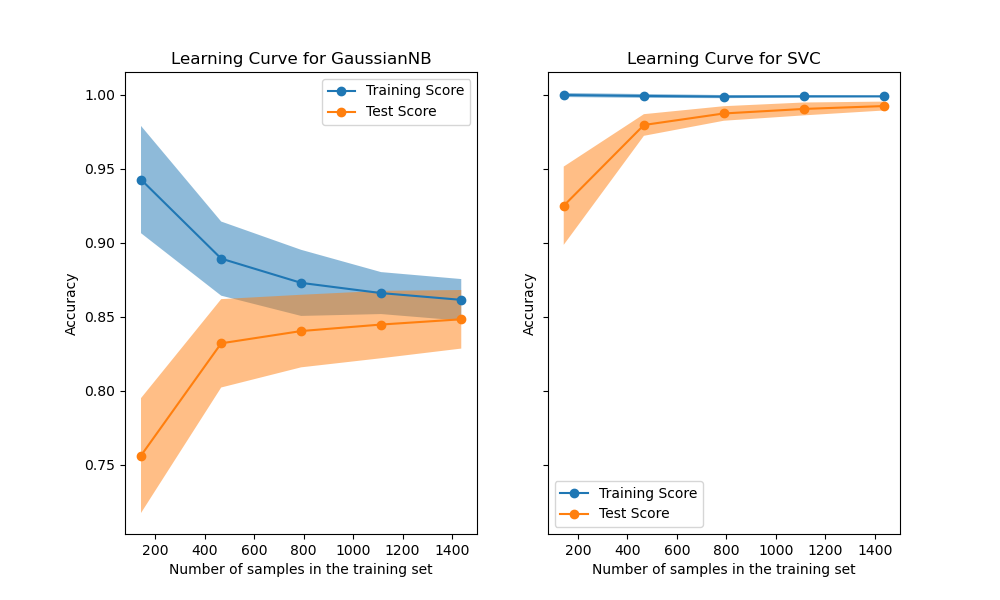
学习曲线显示了估计器在不同数量的训练样本下的验证分数和训练分数。它是一种工具,用于了解我们从添加更多训练数据中能受益多少,以及估计器是更受方差误差还是偏差误差的影响。考虑以下示例,我们绘制了朴素贝叶斯分类器和SVM的学习曲线。
对于朴素贝叶斯,随着训练集大小的增加,验证分数和训练分数都收敛到一个相当低的值。因此,我们可能不会从更多的训练数据中受益太多。
相比之下,对于少量数据,SVM的训练分数远大于验证分数。添加更多的训练样本很可能会提高泛化能力。
我们可以使用函数learning_curve来生成绘制此类学习曲线所需的值(已使用的样本数量、训练集上的平均分数和验证集上的平均分数)。
>>> from sklearn.model_selection import learning_curve
>>> from sklearn.svm import SVC
>>> train_sizes, train_scores, valid_scores = learning_curve(
... SVC(kernel='linear'), X, y, train_sizes=[50, 80, 110], cv=5)
>>> train_sizes
array([ 50, 80, 110])
>>> train_scores
array([[0.98, 0.98 , 0.98, 0.98, 0.98],
[0.98, 1. , 0.98, 0.98, 0.98],
[0.98, 1. , 0.98, 0.98, 0.99]])
>>> valid_scores
array([[1. , 0.93, 1. , 1. , 0.96],
[1. , 0.96, 1. , 1. , 0.96],
[1. , 0.96, 1. , 1. , 0.96]])
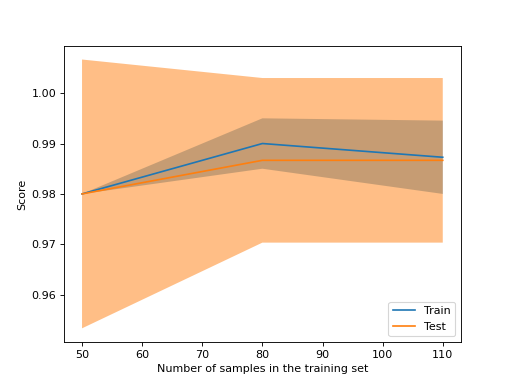
如果您只想绘制学习曲线,那么类LearningCurveDisplay将更容易使用。您可以使用方法from_estimator,类似于learning_curve来生成并绘制学习曲线。
from sklearn.datasets import load_iris
from sklearn.model_selection import LearningCurveDisplay
from sklearn.svm import SVC
from sklearn.utils import shuffle
X, y = load_iris(return_X_y=True)
X, y = shuffle(X, y, random_state=0)
LearningCurveDisplay.from_estimator(
SVC(kernel="linear"), X, y, train_sizes=[50, 80, 110], cv=5)
示例
有关使用学习曲线检查预测模型可扩展性的示例,请参见绘制学习曲线并检查模型可伸缩性。