7.7. 核近似#
此子模块包含用于近似与某些核(例如支持向量机中使用的核,参见支持向量机)对应的特征映射的函数。以下特征函数对输入执行非线性变换,可作为线性分类或其他算法的基础。
与隐式使用特征映射的核技巧相比,使用近似的显式特征映射的优点是,显式映射更适合在线学习,并且可以显著降低处理超大型数据集时的学习成本。标准的核化 SVM 对大型数据集的扩展性不佳,但通过使用近似核映射,可以采用效率更高的线性 SVM。特别是,核映射近似与SGDClassifier的结合使得在大型数据集上进行非线性学习成为可能。
由于使用近似嵌入的实证研究不多,因此建议在可能的情况下将结果与精确核方法进行比较。
另请参见
有关精确多项式变换,请参见多项式回归:使用基函数扩展线性模型。
7.7.1. 用于核近似的 Nystroem 方法#
Nystroem 方法,如在Nystroem中实现,是一种用于核的降秩近似的通用方法。它通过对计算核的数据进行无放回子采样行/列来实现。虽然精确方法的计算复杂度为\(\mathcal{O}(n^3_{\text{samples}})\),但近似方法的复杂度为\(\mathcal{O}(n^2_{\text{components}} \cdot n_{\text{samples}})\),其中可以在性能没有显著下降的情况下设置\(n_{\text{components}} \ll n_{\text{samples}}\)[WS2001]。
我们可以根据数据的特征构建核矩阵\(K\)的特征分解,然后将其分成已采样和未采样的数据点。
其中
\(U\) 是正交的
\(\Lambda\) 是特征值的对角矩阵
\(U_1\) 是所选样本的正交矩阵
\(U_2\) 是未选样本的正交矩阵
鉴于\(U_1 \Lambda U_1^T\)可以通过矩阵\(K_{11}\)的正交化获得,并且\(U_2 \Lambda U_1^T\)(以及其转置)可以计算,唯一需要阐明的是\(U_2 \Lambda U_2^T\)。为此,我们可以用已经计算过的矩阵来表示它
在fit期间,Nystroem类评估基\(U_1\),并计算归一化常数\(K_{11}^{-\frac12}\)。随后,在transform期间,将在基(由components_属性给出)和新数据点X之间确定核矩阵。然后将该矩阵乘以normalization_矩阵以得到最终结果。
默认情况下,Nystroem使用rbf核,但它可以使用任何核函数或预计算的核矩阵。所使用的样本数量——这也是计算出的特征的维度——由参数n_components给出。
示例
7.7.2. 径向基函数核#
RBFSampler为径向基函数核构造了一个近似映射,该映射也称为随机厨房水槽[RR2007]。这种变换可以用于在线性算法(例如线性 SVM)应用之前明确地建模核映射。
>>> from sklearn.kernel_approximation import RBFSampler
>>> from sklearn.linear_model import SGDClassifier
>>> X = [[0, 0], [1, 1], [1, 0], [0, 1]]
>>> y = [0, 0, 1, 1]
>>> rbf_feature = RBFSampler(gamma=1, random_state=1)
>>> X_features = rbf_feature.fit_transform(X)
>>> clf = SGDClassifier(max_iter=5)
>>> clf.fit(X_features, y)
SGDClassifier(max_iter=5)
>>> clf.score(X_features, y)
1.0
该映射依赖于对核值的蒙特卡洛近似。fit函数执行蒙特卡洛采样,而transform方法执行数据的映射。由于该过程固有的随机性,不同调用fit函数的结果可能有所不同。
fit函数接受两个参数:n_components,即特征变换的目标维度;以及gamma,RBF核的参数。更高的n_components将导致更好的核近似,并产生与核 SVM 生成的结果更相似的结果。请注意,“拟合”特征函数实际上不依赖于提供给fit函数的数据。仅使用数据的维度。有关该方法的详细信息可在[RR2007]中找到。
对于给定的n_components值,RBFSampler通常不如Nystroem精确。然而,RBFSampler的计算成本更低,从而使更大的特征空间的使用更加高效。
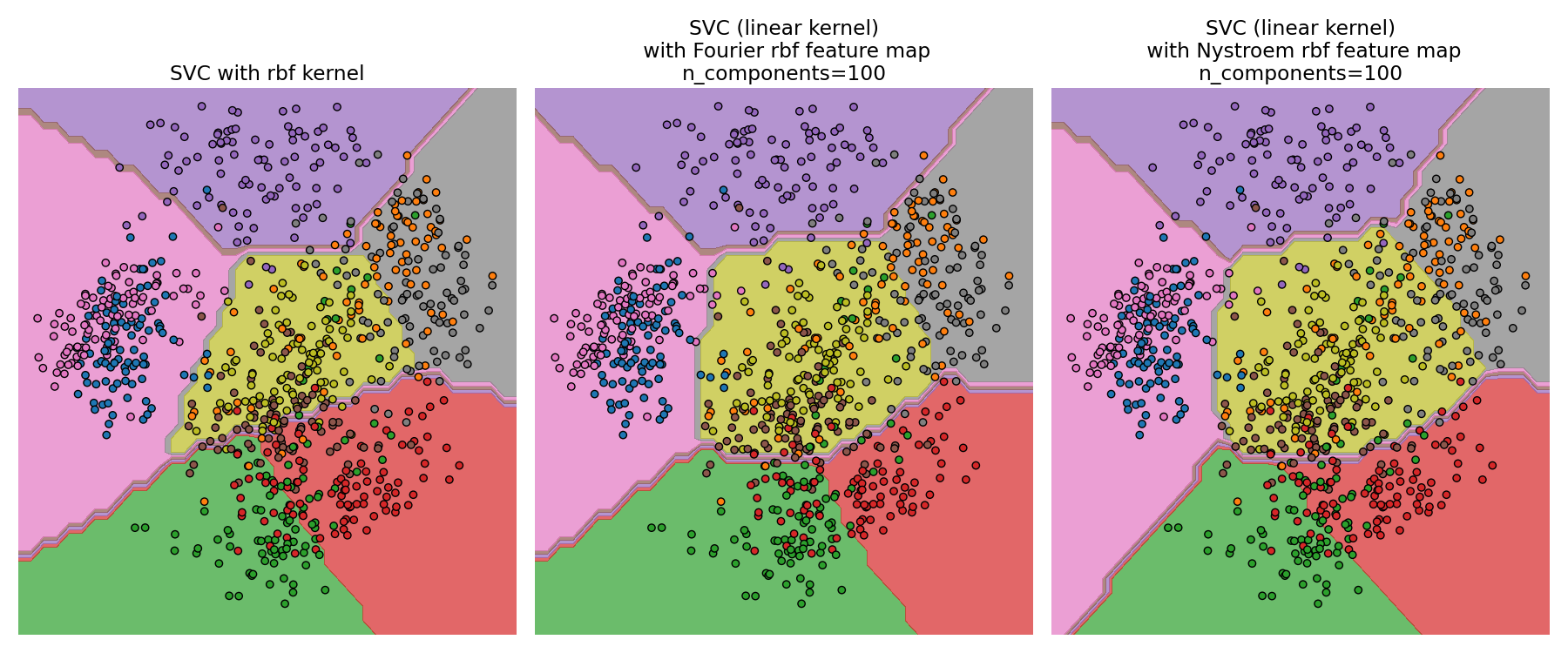
精确 RBF 核(左)与近似核(右)的比较#
示例
7.7.3. 加性卡方核#
加性卡方核是一种作用于直方图的核,常用于计算机视觉。
此处使用的加性卡方核由以下公式给出
这与sklearn.metrics.pairwise.additive_chi2_kernel不完全相同。[VZ2010]的作者更喜欢上述版本,因为它总是正定的。由于核是加性的,因此可以单独处理所有分量\(x_i\)进行嵌入。这使得可以在规则间隔采样傅里叶变换,而不是使用蒙特卡洛采样进行近似。
类AdditiveChi2Sampler实现了这种逐分量的确定性采样。每个分量被采样\(n\)次,每个输入维度产生\(2n+1\)个维度(两倍的原因是傅里叶变换的实部和虚部)。在文献中,\(n\)通常选择为 1 或 2,将数据集转换为大小为n_samples * 5 * n_features(在\(n=2\)的情况下)。
由AdditiveChi2Sampler提供的近似特征映射可以与RBFSampler提供的近似特征映射结合,以生成指数卡方核的近似特征映射。详细信息请参见[VZ2010],与[VVZ2010]中与RBFSampler的结合。
7.7.4. 偏斜卡方核#
偏斜卡方核由以下公式给出
它具有与计算机视觉中常用的指数卡方核相似的特性,但允许对特征映射进行简单的蒙特卡洛近似。
SkewedChi2Sampler的用法与上述RBFSampler的用法相同。唯一的区别在于自由参数,它被称为\(c\)。有关此映射的动机和数学细节,请参见[LS2010]。
7.7.5. 基于张量草图的多项式核近似#
多项式核是一种流行的核函数,由以下公式给出
其中
x,y是输入向量d是核的阶数
直观上,d阶多项式核的特征空间由输入特征之间所有可能的d阶乘积组成,这使得使用该核的学习算法能够考虑特征之间的交互作用。
TensorSketch [PP2013]方法,如在PolynomialCountSketch中实现,是一种可扩展的、与输入数据无关的多项式核近似方法。它基于Count sketch [WIKICS] [CCF2002]的概念,这是一种类似于特征哈希的降维技术,但它使用多个独立的哈希函数。TensorSketch获得两个向量(或向量自身)外积的Count Sketch,这可以作为多项式核特征空间的一个近似。特别是,TensorSketch不是显式计算外积,而是计算向量的Count Sketch,然后通过快速傅里叶变换使用多项式乘法来计算它们外积的Count Sketch。
方便的是,TensorSketch 的训练阶段仅包括初始化一些随机变量。因此,它与输入数据无关,即仅取决于输入特征的数量,而不取决于数据值。此外,该方法可以在\(\mathcal{O}(n_{\text{samples}}(n_{\text{features}} + n_{\text{components}} \log(n_{\text{components}})))\)时间内转换样本,其中\(n_{\text{components}}\)是所需输出维度,由n_components确定。
示例
7.7.6. 数学细节#
核方法,如支持向量机或核化 PCA,依赖于再生核希尔伯特空间的性质。对于任何正定核函数\(k\)(所谓的 Mercer 核),可以保证存在一个映射\(\phi\)到希尔伯特空间\(\mathcal{H}\),使得
其中\(\langle \cdot, \cdot \rangle\)表示希尔伯特空间中的内积。
如果一个算法,例如线性支持向量机或 PCA,仅依赖于数据点\(x_i\)的标量积,则可以使用\(k(x_i, x_j)\)的值,这相当于将算法应用于映射的数据点\(\phi(x_i)\)。使用\(k\)的优点是,映射\(\phi\)永远不需要显式计算,从而允许任意大的特征(甚至是无限的)。
核方法的一个缺点是,在优化过程中可能需要存储许多核值\(k(x_i, x_j)\)。如果将核化分类器应用于新数据\(y_j\),则需要计算\(k(x_i, y_j)\)以进行预测,这可能涉及到训练集中的许多不同\(x_i\)。
此子模块中的类允许近似嵌入\(\phi\),从而显式地使用表示\(\phi(x_i)\),这避免了应用核或存储训练样本的需要。
参考文献
“使用 Nyström 方法加速核机器” Williams, C.K.I.; Seeger, M. - 2001.
“用于大规模核机器的随机特征” Rahimi, A. and Recht, B. - Advances in neural information processing 2007,
“偏斜乘法直方图核的随机傅里叶近似” Li, F., Ionescu, C., and Sminchisescu, C. - Pattern Recognition, DAGM 2010, Lecture Notes in Computer Science.
“通过显式特征映射的高效加性核” Vedaldi, A. and Zisserman, A. - Computer Vision and Pattern Recognition 2010
“用于高效检测的广义 RBF 特征映射” Vempati, S. and Vedaldi, A. and Zisserman, A. and Jawahar, CV - 2010
“通过显式特征映射实现快速可扩展多项式核” Pham, N., & Pagh, R. - 2013
“在数据流中查找频繁项” Charikar, M., Chen, K., & Farach-Colton - 2002