9.1. 计算扩展策略:大数据#
对于某些应用,数据量、特征数量(或两者兼有)和/或处理速度对传统方法构成了挑战。在这种情况下,scikit-learn 提供了一些选项,您可以考虑使用它们来扩展您的系统。
9.1.1. 使用核外学习进行实例扩展#
核外(或“外部内存”)学习是一种用于从无法完全载入计算机主内存(RAM)的数据中进行学习的技术。
以下是实现此目标设计的系统概述
一种流式处理实例的方法
一种从实例中提取特征的方法
一种增量算法
9.1.1.1. 流式处理实例#
基本上,1. 可以是一个从硬盘文件、数据库、网络流等生成实例的读取器。然而,如何实现这些细节超出了本文档的范围。
9.1.1.2. 特征提取#
2. 可以是 scikit-learn 支持的各种特征提取方法中任何相关的方法。然而,当处理需要向量化且特征或值集事先未知的数据时,应特别注意。一个很好的例子是文本分类,其中在训练期间可能会发现未知词项。如果从应用角度看多次遍历数据是合理的,则可以使用有状态的向量化器。否则,可以使用无状态特征提取器来增加难度。目前,首选的方法是使用所谓的哈希技巧,其在 sklearn.feature_extraction.FeatureHasher 中实现,用于将分类变量表示为 Python 字典列表的数据集;或者使用 sklearn.feature_extraction.text.HashingVectorizer 用于文本文档。
9.1.1.3. 增量学习#
最后,对于 3. scikit-learn 中有多种选择。尽管并非所有算法都能增量学习(即无需一次性看到所有实例),但所有实现 partial_fit API 的估计器都是候选者。实际上,从迷你批量实例中增量学习(有时称为“在线学习”)的能力是核外学习的关键,因为它保证在任何给定时间主内存中只有少量实例。选择一个好的迷你批量大小,以平衡相关性和内存占用,可能需要一些调优[1]。
以下是针对不同任务的增量估计器列表
对于分类任务,需要注意一点:尽管无状态的特征提取例程可能能够处理新的/未见的属性,但增量学习器本身可能无法处理新的/未见的目标类别。在这种情况下,您必须在第一次调用 partial_fit 时使用 classes= 参数传入所有可能的类别。
选择合适算法时需要考虑的另一个方面是,并非所有算法都随着时间对每个示例给予相同的重视。感知机(Perceptron)即使在处理了许多示例后,仍然对错误标记的示例敏感,而 SGD* 和 PassiveAggressive* 系列算法对此类异常情况更具鲁棒性。反之,后两者也倾向于在流后期对那些显著不同但标记正确的示例给予较少的重视,因为它们的学习率会随时间降低。
9.1.1.4. 示例#
最后,我们提供了一个完整的文本文档核外分类示例。它旨在为希望构建核外学习系统的人提供一个起点,并展示了上面讨论的大部分概念。
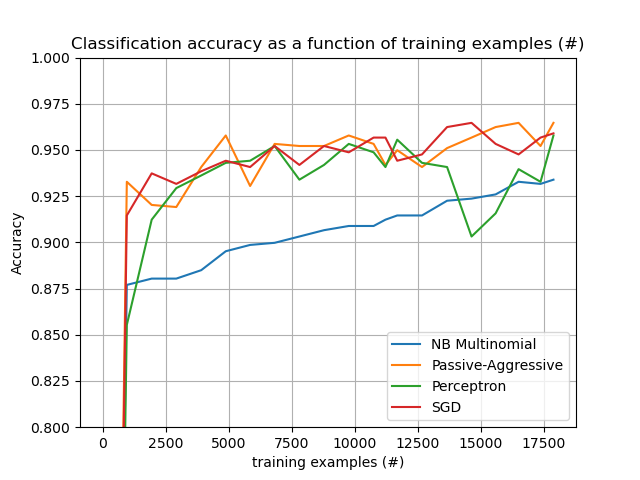
此外,它还展示了不同算法的性能随处理示例数量的变化趋势。
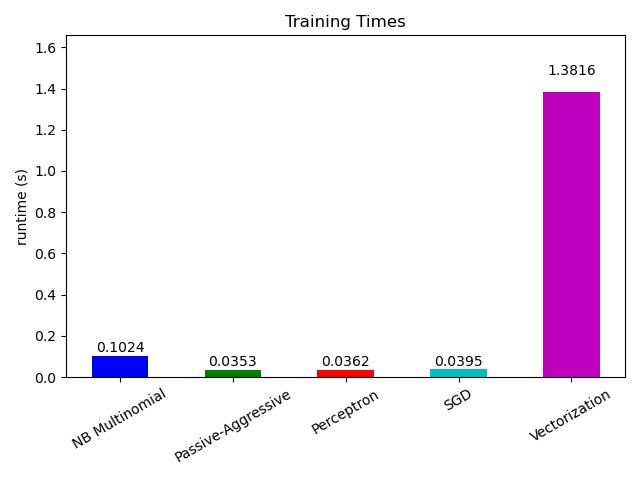
现在来看不同部分的计算时间,我们发现向量化比学习本身要昂贵得多。在不同算法中,MultinomialNB 是开销最大的,但其开销可以通过增加迷你批量大小来缓解(练习:将程序中的 minibatch_size 更改为 100 和 10000 并进行比较)。