2.9. 神经网络模型(无监督)#
2.9.1. 受限玻尔兹曼机#
受限玻尔兹曼机(RBM)是基于概率模型的无监督非线性特征学习器。RBM或RBM层级结构提取的特征在输入到线性分类器(例如线性SVM或感知机)时通常能获得良好的结果。
该模型对输入分布做出假设。目前,scikit-learn仅提供BernoulliRBM,它假设输入是二值数据或介于0和1之间的值,每个值编码特定特征被激活的概率。
RBM尝试使用特定的图模型最大化数据的似然性。所使用的参数学习算法(随机最大似然)阻止了表示偏离输入数据太远,这使得它们能够捕捉到有趣的规律性,但也使该模型对于小型数据集不太有用,并且通常不适用于密度估计。
该方法因使用独立RBM的权重初始化深度神经网络而获得普及。这种方法被称为无监督预训练。

示例
2.9.1.1. 图模型与参数化#
RBM的图模型是一个全连接的二分图。
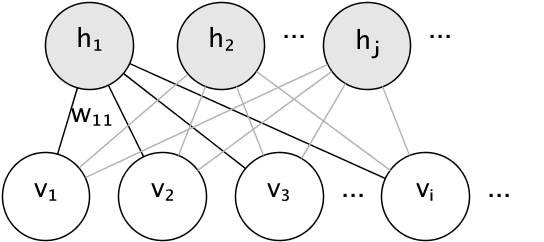
节点是随机变量,其状态取决于与其连接的其他节点的状态。因此,模型通过连接的权重以及每个可见单元和隐藏单元的一个截距(偏置)项进行参数化,图像中为简化起见省略了这些项。
能量函数衡量联合赋值的质量
在上面的公式中,\(\mathbf{b}\)和\(\mathbf{c}\)分别是可见层和隐藏层的截距向量。模型的联合概率通过能量定义
单词受限指的是模型的二分结构,它禁止隐藏单元之间或可见单元之间的直接交互。这意味着假设了以下条件独立性
二分结构允许使用高效的块吉布斯采样进行推断。
2.9.1.2. 伯努利受限玻尔兹曼机#
在BernoulliRBM中,所有单元都是二值随机单元。这意味着输入数据应该要么是二值的,要么是介于0和1之间的实数值,表示可见单元开启或关闭的概率。这对于字符识别是一个很好的模型,因为关注点在于哪些像素是活跃的,哪些不是。对于自然场景图像,它不再适用,因为背景、深度以及相邻像素趋向于取相同值的倾向。
每个单元的条件概率分布由其接收到的输入的逻辑S形激活函数给出
其中\(\sigma\)是逻辑S形函数
2.9.1.3. 随机最大似然学习#
在BernoulliRBM中实现的训练算法被称为随机最大似然(SML)或持久对比散度(PCD)。由于数据似然的形式,直接优化最大似然是不可行的
为简化起见,上式是为单个训练样本编写的。相对于权重的梯度由与上式对应的两项组成。它们通常被称为正梯度和负梯度,因为它们各自的符号。在此实现中,梯度是根据小批量样本估算的。
在最大化对数似然时,正梯度使模型偏好与观测训练数据兼容的隐藏状态。由于RBM的二分结构,它可以被高效计算。然而,负梯度是难以处理的。其目标是降低模型偏好的联合状态的能量,从而使其忠实于数据。它可以通过马尔可夫链蒙特卡洛方法,使用块吉布斯采样迭代地在给定另一个变量的情况下采样\(v\)和\(h\)来近似,直到链混合。以这种方式生成的样本有时被称为幻想粒子。这种方法效率低下,并且难以确定马尔可夫链是否混合。
对比散度方法建议在少量迭代(\(k\),通常甚至为1)后停止链。该方法速度快且方差低,但样本与模型分布相去甚远。
持久对比散度解决了这个问题。PCD不是在每次需要梯度时都启动一个新的链并只执行一个吉布斯采样步骤,而是在每次权重更新后保留一些链(幻想粒子),并对它们执行\(k\)个吉布斯步骤的更新。这使得粒子能够更彻底地探索空间。
参考文献
“深度信念网络的快速学习算法”, G. Hinton, S. Osindero, Y.-W. Teh, 2006
“使用似然梯度近似训练受限玻尔兹曼机”, T. Tieleman, 2008