1.4. 支持向量机#
支持向量机(SVMs)是一组监督学习方法,用于分类、回归和异常值检测。
支持向量机的优点是
在高维空间中表现良好。
在维度数量大于样本数量的情况下仍然有效。
在决策函数中使用训练点的子集(称为支持向量),因此也具有内存效率。
多功能:可以为决策函数指定不同的核函数。提供了常用核,但也可能指定自定义核。
支持向量机的缺点包括
scikit-learn 中的支持向量机支持密集(numpy.ndarray 及可通过 numpy.asarray 转换的类型)和稀疏(任何 scipy.sparse)样本向量作为输入。然而,要使用SVM对稀疏数据进行预测,它必须已经在此类数据上进行过拟合。为获得最佳性能,请使用 C 序的 numpy.ndarray(密集)或 scipy.sparse.csr_matrix(稀疏),且 dtype=float64。
1.4.1. 分类#
SVC、NuSVC 和 LinearSVC 是能够在数据集上执行二分类和多分类的类。
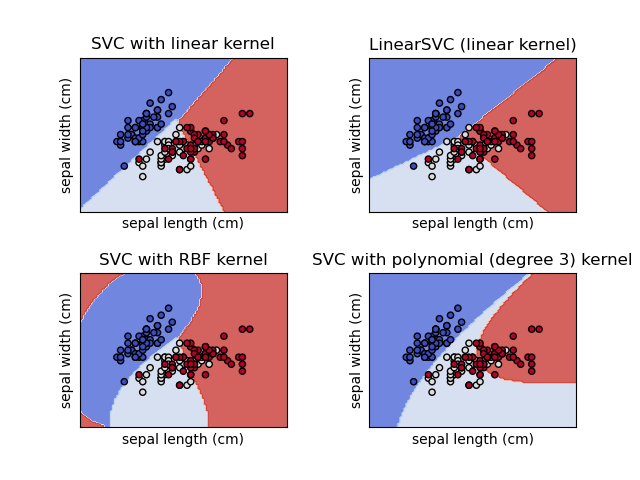
SVC 和 NuSVC 是相似的方法,但接受的参数集略有不同,并且具有不同的数学公式(参见数学公式部分)。另一方面,LinearSVC 是线性核情况下支持向量分类的另一种(更快)实现。它也缺少 SVC 和 NuSVC 的一些属性,例如 support_。LinearSVC 使用 squared_hinge 损失,并且由于其在 liblinear 中的实现,如果考虑截距,它还会对截距进行正则化。然而,通过仔细调整其 intercept_scaling 参数可以减少这种影响,该参数允许截距项与其它特征相比具有不同的正则化行为。因此,分类结果和分数可能与另外两个分类器不同。
与其他分类器一样,SVC、NuSVC 和 LinearSVC 接受两个数组作为输入:一个形状为 (n_samples, n_features) 的数组 X,包含训练样本;以及一个形状为 (n_samples) 的类别标签数组 y(字符串或整数)。
>>> from sklearn import svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf = svm.SVC()
>>> clf.fit(X, y)
SVC()
模型拟合后,即可用于预测新值
>>> clf.predict([[2., 2.]])
array([1])
SVM的决策函数(在数学公式中详述)依赖于训练数据的某个子集,这些子集被称为支持向量。这些支持向量的一些属性可以在 support_vectors_、support_ 和 n_support_ 属性中找到。
>>> # get support vectors
>>> clf.support_vectors_
array([[0., 0.],
[1., 1.]])
>>> # get indices of support vectors
>>> clf.support_
array([0, 1]...)
>>> # get number of support vectors for each class
>>> clf.n_support_
array([1, 1]...)
示例
1.4.1.1. 多类别分类#
SVC 和 NuSVC 实现了多类别分类的“一对一”方法。总共构建了 n_classes * (n_classes - 1) / 2 个分类器,每个分类器都使用来自两个类别的数据进行训练。为了提供与其他分类器一致的接口,decision_function_shape 选项允许将“一对一”分类器的结果单调地转换为形状为 (n_samples, n_classes) 的“一对多”决策函数,这是该参数的默认设置(默认='ovr')。
>>> X = [[0], [1], [2], [3]]
>>> Y = [0, 1, 2, 3]
>>> clf = svm.SVC(decision_function_shape='ovo')
>>> clf.fit(X, Y)
SVC(decision_function_shape='ovo')
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 6 classes: 4*3/2 = 6
6
>>> clf.decision_function_shape = "ovr"
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 4 classes
4
另一方面,LinearSVC 实现了“一对剩余”的多类别策略,从而训练了 n_classes 个模型。
>>> lin_clf = svm.LinearSVC()
>>> lin_clf.fit(X, Y)
LinearSVC()
>>> dec = lin_clf.decision_function([[1]])
>>> dec.shape[1]
4
有关决策函数的完整描述,请参见数学公式。
多类别策略详情#
请注意,LinearSVC 还通过使用选项 multi_class='crammer_singer' 实现了一种替代的多类别策略,即 Crammer 和 Singer [16] 提出的多类别 SVM。在实践中,通常首选“一对剩余”分类,因为结果大多相似,但运行时显著减少。
对于“一对剩余”的 LinearSVC,属性 coef_ 和 intercept_ 的形状分别为 (n_classes, n_features) 和 (n_classes,)。系数的每一行对应于 n_classes 个“一对剩余”分类器之一,截距也类似,按照“一”类别的顺序排列。
对于“一对一”的 SVC 和 NuSVC,属性的布局稍微复杂一些。对于线性核的情况,属性 coef_ 和 intercept_ 的形状分别为 (n_classes * (n_classes - 1) / 2, n_features) 和 (n_classes * (n_classes - 1) / 2)。这与上面描述的 LinearSVC 的布局相似,只是现在每一行对应一个二元分类器。类别 0 到 n 的顺序是“0 对 1”、“0 对 2”、...“0 对 n”、“1 对 2”、“1 对 3”、“1 对 n”、...“n-1 对 n”。
属性 dual_coef_ 的形状为 (n_classes-1, n_SV),其布局有些难以理解。列对应于涉及任何 n_classes * (n_classes - 1) / 2 个“一对一”分类器的支持向量。每个支持向量 v 在每个 n_classes - 1 个分类器中都具有一个对偶系数,这些分类器将 v 的类别与另一个类别进行比较。请注意,这些对偶系数中有些(但不是全部)可能为零。每列中的 n_classes - 1 个条目是这些对偶系数,按对立类别的顺序排列。
通过一个例子可能会更清楚:考虑一个三分类问题,其中类别 0 有三个支持向量 \(v^{0}_0, v^{1}_0, v^{2}_0\),类别 1 和 2 分别有两个支持向量 \(v^{0}_1, v^{1}_1\) 和 \(v^{0}_2, v^{1}_2\)。对于每个支持向量 \(v^{j}_i\),有两个对偶系数。我们称支持向量 \(v^{j}_i\) 在类别 \(i\) 和 \(k\) 之间分类器中的系数为 \(\alpha^{j}_{i,k}\)。那么 dual_coef_ 看起来是这样的:
\(\alpha^{0}_{0,1}\) |
\(\alpha^{1}_{0,1}\) |
\(\alpha^{2}_{0,1}\) |
\(\alpha^{0}_{1,0}\) |
\(\alpha^{1}_{1,0}\) |
\(\alpha^{0}_{2,0}\) |
\(\alpha^{1}_{2,0}\) |
\(\alpha^{0}_{0,2}\) |
\(\alpha^{1}_{0,2}\) |
\(\alpha^{2}_{0,2}\) |
\(\alpha^{0}_{1,2}\) |
\(\alpha^{1}_{1,2}\) |
\(\alpha^{0}_{2,1}\) |
\(\alpha^{1}_{2,1}\) |
类别 0 的支持向量系数 |
类别 1 的支持向量系数 |
类别 2 的支持向量系数 |
||||
示例
1.4.1.2. 分数和概率#
SVC 和 NuSVC 的 decision_function 方法为每个样本提供每个类别的分数(或在二分类情况下为每个样本提供一个分数)。当构造函数选项 probability 设置为 True 时,会启用类别成员资格概率估计(通过 predict_proba 和 predict_log_proba 方法)。在二分类情况下,概率使用 Platt 定标 [9] 进行校准:对SVM分数进行逻辑回归,并通过在训练数据上进行额外的交叉验证来拟合。在多类别情况下,这会根据 [10] 进行扩展。
注意
所有估计器都可以通过 CalibratedClassifierCV(参见概率校准)使用相同的概率校准过程。对于 SVC 和 NuSVC,此过程内置于底层使用的 libsvm 中,因此它不依赖于 scikit-learn 的 CalibratedClassifierCV。
Platt 定标中涉及的交叉验证对于大型数据集来说是一项耗时操作。此外,概率估计可能与分数不一致
分数的“argmax”可能不是概率的 argmax
在二分类中,即使
predict_proba的输出小于 0.5,样本也可能被predict标记为正类;类似地,即使predict_proba的输出大于 0.5,它也可能被标记为负类。
Platt 的方法也被认为存在理论问题。如果需要置信度分数,但这些分数不必是概率,则建议将 probability=False 并使用 decision_function 而不是 predict_proba。
请注意,当 decision_function_shape='ovr' 且 n_classes > 2 时,与 decision_function 不同,predict 方法默认不尝试打破平局。您可以将 break_ties=True 以使 predict 的输出与 np.argmax(clf.decision_function(...), axis=1) 相同,否则将始终返回平局类别中的第一个类别;但请记住这会带来计算成本。有关打破平局的示例,请参见SVM平局打破示例。
1.4.1.3. 不平衡问题#
在需要对某些类别或某些单个样本给予更高重要性的问题中,可以使用参数 class_weight 和 sample_weight。
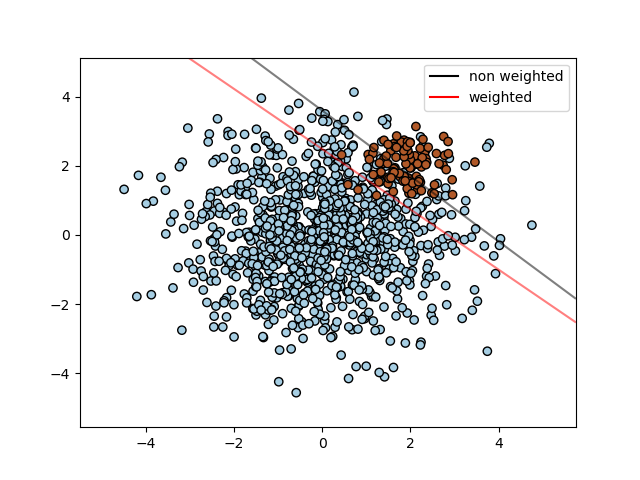
SVC(但不是 NuSVC)在 fit 方法中实现了参数 class_weight。它是一个形如 {class_label : value} 的字典,其中 value 是一个大于 0 的浮点数,它将类别 class_label 的参数 C 设置为 C * value。下图展示了不平衡问题的决策边界,分别有和没有权重校正。
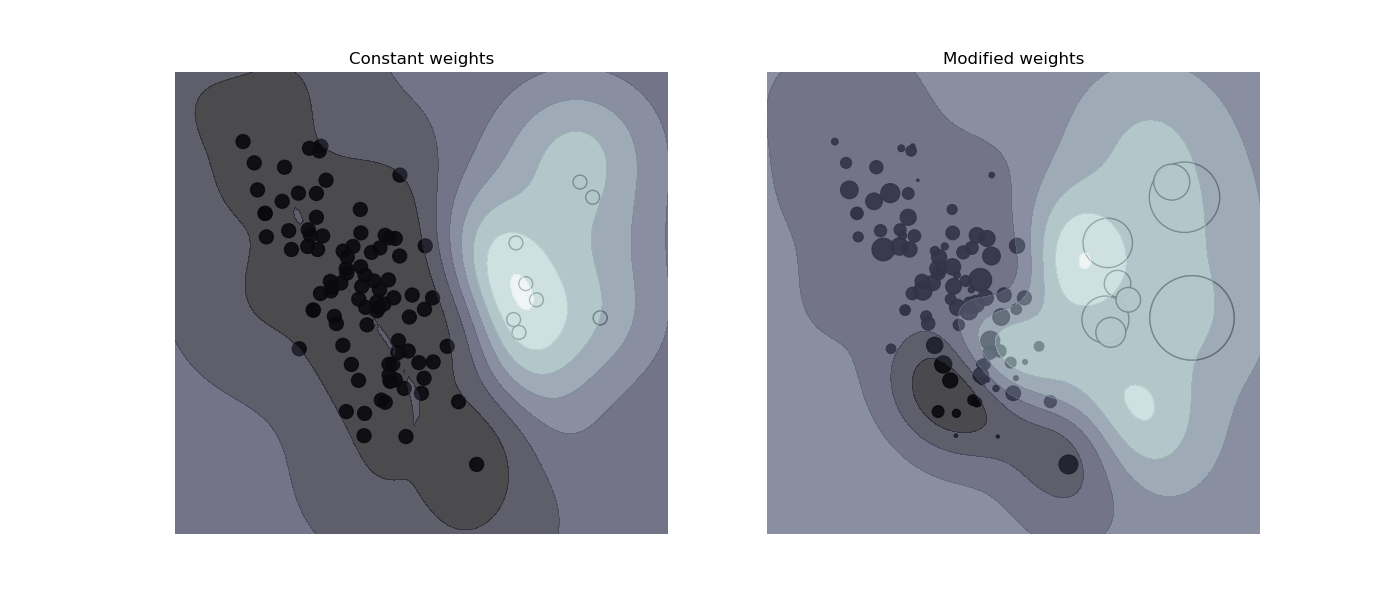
SVC、NuSVC、SVR、NuSVR、LinearSVC、LinearSVR 和 OneClassSVM 也通过 sample_weight 参数在 fit 方法中实现了单个样本的权重。与 class_weight 类似,这会将第 i 个样本的参数 C 设置为 C * sample_weight[i],这将鼓励分类器正确地处理这些样本。下图展示了样本权重对决策边界的影响。圆圈的大小与样本权重成正比。
示例
1.4.2. 回归#
支持向量分类方法可以扩展到解决回归问题。这种方法称为支持向量回归。
支持向量分类(如上所述)产生的模型仅依赖于训练数据的子集,因为构建模型的成本函数不关心超出间隔的训练点。类似地,支持向量回归产生的模型也仅依赖于训练数据的子集,因为成本函数会忽略预测值接近其目标的样本。
支持向量回归有三种不同的实现:SVR、NuSVR 和 LinearSVR。LinearSVR 提供比 SVR 更快的实现,但仅考虑线性核,而 NuSVR 的公式与 SVR 和 LinearSVR 略有不同。由于其在 liblinear 中的实现,LinearSVR 如果考虑截距也会对其进行正则化。然而,通过仔细调整其 intercept_scaling 参数可以减少这种影响,该参数允许截距项与其它特征相比具有不同的正则化行为。因此,分类结果和分数可能与另外两个分类器不同。有关更多详细信息,请参见实现细节。
与分类类一样,fit 方法将以向量 X、y 作为参数,只是在这种情况下,y 预计为浮点值而不是整数值
>>> from sklearn import svm
>>> X = [[0, 0], [2, 2]]
>>> y = [0.5, 2.5]
>>> regr = svm.SVR()
>>> regr.fit(X, y)
SVR()
>>> regr.predict([[1, 1]])
array([1.5])
示例
1.4.3. 密度估计、新颖性检测#
类 OneClassSVM 实现了一种单类 SVM,用于异常值检测。
有关 OneClassSVM 的描述和用法,请参见新颖性与异常值检测。
1.4.4. 复杂度#
支持向量机是强大的工具,但其计算和存储需求随训练向量的数量迅速增加。SVM 的核心是一个二次规划问题(QP),用于将支持向量与其余训练数据分离。基于 libsvm 的实现所使用的 QP 求解器在实践中(取决于数据集)的扩展范围在 \(O(n_{features} \times n_{samples}^2)\) 到 \(O(n_{features} \times n_{samples}^3)\) 之间,具体取决于 libsvm 缓存的使用效率。如果数据非常稀疏,\(n_{features}\) 应替换为样本向量中非零特征的平均数量。
对于线性情况,LinearSVC 中由 liblinear 实现使用的算法比其基于 libsvm 的对应版本 SVC 效率高得多,并且可以几乎线性地扩展到数百万个样本和/或特征。
1.4.5. 实用技巧#
避免数据复制:对于
SVC、SVR、NuSVC和NuSVR,如果传递给某些方法的数据不是 C 序连续且双精度的,则在调用底层 C 实现之前会对其进行复制。您可以通过检查给定 numpy 数组的flags属性来检查它是否为 C 连续。对于
LinearSVC(和LogisticRegression),任何作为 numpy 数组传递的输入都将被复制并转换为 liblinear 内部的稀疏数据表示(双精度浮点数和非零分量的 int32 索引)。如果您想拟合大规模线性分类器而不复制密集 numpy C 连续双精度数组作为输入,我们建议改用SGDClassifier类。目标函数可以配置为与LinearSVC模型几乎相同。核缓存大小:对于
SVC、SVR、NuSVC和NuSVR,核缓存的大小对大型问题的运行时间有很大影响。如果您有足够的 RAM,建议将cache_size设置为高于默认值 200(MB) 的值,例如 500(MB) 或 1000(MB)。设置 C:
C默认为1,这是一个合理的默认选择。如果您有大量带噪声的观测值,则应减小它:减小 C 对应于更多的正则化。LinearSVC和LinearSVR对较大的C值不太敏感,预测结果在达到某个阈值后停止改善。同时,较大的C值将需要更长的训练时间,有时甚至长达 10 倍,如 [11] 所示。支持向量机算法不是尺度不变的,因此强烈建议对数据进行缩放。例如,将输入向量 X 中的每个属性缩放到 [0,1] 或 [-1,+1] 之间,或者将其标准化,使其均值为 0,方差为 1。请注意,必须对测试向量应用相同的缩放以获得有意义的结果。这可以通过使用
Pipeline轻松完成。>>> from sklearn.pipeline import make_pipeline >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.svm import SVC >>> clf = make_pipeline(StandardScaler(), SVC())
有关缩放和归一化的更多详细信息,请参见数据预处理部分。
关于
shrinking参数,引用 [12] 的话:我们发现,如果迭代次数很多,那么 shrinking 可以缩短训练时间。然而,如果我们宽松地解决优化问题(例如,使用较大的停止容忍度),则不使用 shrinking 的代码可能会快得多。NuSVC/OneClassSVM/NuSVR中的参数nu近似训练误差和支持向量的比例。在
SVC中,如果数据不平衡(例如,正样本很多而负样本很少),请设置class_weight='balanced'和/或尝试不同的惩罚参数C。底层实现中的随机性:
SVC和NuSVC的底层实现仅在进行概率估计时(当probability设置为True时)使用随机数生成器来打乱数据。这种随机性可以通过random_state参数控制。如果probability设置为False,则这些估计器不具有随机性,并且random_state对结果没有影响。底层的OneClassSVM实现与SVC和NuSVC的实现相似。由于OneClassSVM不提供概率估计,因此它不具有随机性。底层的
LinearSVC实现在使用对偶坐标下降(即当dual设置为True时)拟合模型时,会使用随机数生成器来选择特征。因此,对于相同的输入数据,结果略有不同并不罕见。如果发生这种情况,请尝试使用较小的tol参数。这种随机性也可以通过random_state参数控制。当dual设置为False时,LinearSVC的底层实现不具有随机性,并且random_state对结果没有影响。使用
LinearSVC(penalty='l1', dual=False)提供的 L1 惩罚会产生稀疏解,即只有一部分特征权重不为零并对决策函数有贡献。增加C会产生更复杂的模型(选择更多特征)。产生“空”模型(所有权重为零)的C值可以使用l1_min_c计算。
1.4.6. 核函数#
核函数可以是以下任何一种
线性:\(\langle x, x'\rangle\)。
多项式:\((\gamma \langle x, x'\rangle + r)^d\),其中 \(d\) 由参数
degree指定,\(r\) 由coef0指定。RBF:\(\exp(-\gamma \|x-x'\|^2)\),其中 \(\gamma\) 由参数
gamma指定,必须大于 0。sigmoid:\(\tanh(\gamma \langle x,x'\rangle + r)\),其中 \(r\) 由
coef0指定。
不同的核由 kernel 参数指定
>>> linear_svc = svm.SVC(kernel='linear')
>>> linear_svc.kernel
'linear'
>>> rbf_svc = svm.SVC(kernel='rbf')
>>> rbf_svc.kernel
'rbf'
另请参见核近似,了解使用RBF核的更快、更具可扩展性的解决方案。
1.4.6.1. RBF核的参数#
当使用径向基函数 (RBF) 核训练 SVM 时,必须考虑两个参数:C 和 gamma。参数 C 是所有 SVM 核共有的,它权衡了训练样本的错误分类与决策面的简洁性。低的 C 会使决策面平滑,而高的 C 则旨在正确分类所有训练样本。gamma 定义了单个训练样本的影响力。 gamma 越大,其他样本必须越接近才能受到影响。
正确选择 C 和 gamma 对 SVM 的性能至关重要。建议使用 GridSearchCV,并让 C 和 gamma 以指数间隔选取,以选择好的值。
示例
1.4.6.2. 自定义核#
您可以通过提供 Python 函数作为核,或预计算 Gram 矩阵来定义自己的核。
使用自定义核的分类器与任何其他分类器行为相同,除了
字段
support_vectors_现在为空,只有支持向量的索引存储在support_中。fit()方法中第一个参数的引用(而非副本)被存储以供将来使用。如果在fit()和predict()的使用之间该数组发生变化,您将得到意想不到的结果。
将Python函数用作核#
您可以通过将函数传递给 kernel 参数来使用自己定义的核。
您的核函数必须接受两个形状分别为 (n_samples_1, n_features) 和 (n_samples_2, n_features) 的矩阵作为参数,并返回一个形状为 (n_samples_1, n_samples_2) 的核矩阵。
以下代码定义了一个线性核并创建了一个将使用该核的分类器实例
>>> import numpy as np
>>> from sklearn import svm
>>> def my_kernel(X, Y):
... return np.dot(X, Y.T)
...
>>> clf = svm.SVC(kernel=my_kernel)
使用Gram矩阵#
您可以通过使用 kernel='precomputed' 选项来传递预计算的核。然后,您应该将 Gram 矩阵而不是 X 传递给 fit 和 predict 方法。必须提供所有训练向量和测试向量之间的核值。
>>> import numpy as np
>>> from sklearn.datasets import make_classification
>>> from sklearn.model_selection import train_test_split
>>> from sklearn import svm
>>> X, y = make_classification(n_samples=10, random_state=0)
>>> X_train , X_test , y_train, y_test = train_test_split(X, y, random_state=0)
>>> clf = svm.SVC(kernel='precomputed')
>>> # linear kernel computation
>>> gram_train = np.dot(X_train, X_train.T)
>>> clf.fit(gram_train, y_train)
SVC(kernel='precomputed')
>>> # predict on training examples
>>> gram_test = np.dot(X_test, X_train.T)
>>> clf.predict(gram_test)
array([0, 1, 0])
示例
1.4.7. 数学公式#
支持向量机在高维或无限维空间中构建一个超平面或一组超平面,可用于分类、回归或其他任务。直观上,通过与任何类别最近的训练数据点具有最大距离的超平面(即所谓的函数间隔)可以实现良好的分离,因为一般来说,间隔越大,分类器的泛化误差越低。下图显示了线性可分问题的决策函数,其中有三个样本位于间隔边界上,被称为“支持向量”。
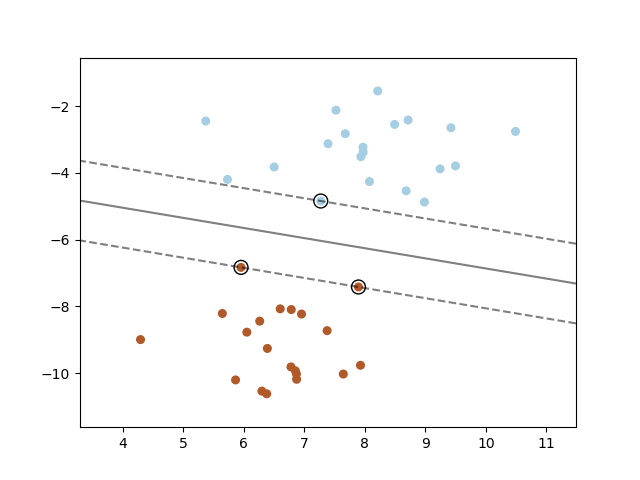
通常,当问题不是线性可分时,支持向量是位于间隔边界之内的样本。
我们推荐 [13] 和 [14] 作为 SVM 理论和实践的良好参考。
1.4.7.1. SVC#
给定两类训练向量 \(x_i \in \mathbb{R}^p\),i=1,…, n,以及一个向量 \(y \in \{1, -1\}^n\),我们的目标是找到 \(w \in \mathbb{R}^p\) 和 \(b \in \mathbb{R}\),使得 \(\text{sign} (w^T\phi(x) + b)\) 给出的预测对于大多数样本是正确的。
SVC 解决以下原始问题
直观地,我们试图最大化间隔(通过最小化 \(||w||^2 = w^Tw\)),同时对错误分类或位于间隔边界内的样本施加惩罚。理想情况下,对于所有样本,值 \(y_i (w^T \phi (x_i) + b)\) 应 \(\geq 1\),这表明预测是完美的。但问题通常并非总是能通过超平面完美分离,因此我们允许一些样本与其正确的间隔边界保持距离 \(\zeta_i\)。惩罚项 C 控制此惩罚的强度,因此,它充当逆正则化参数(参见下文注释)。
原始问题的对偶问题是
其中 \(e\) 是全一向量,\(Q\) 是一个 \(n\) 乘 \(n\) 的半正定矩阵,\(Q_{ij} \equiv y_i y_j K(x_i, x_j)\),其中 \(K(x_i, x_j) = \phi (x_i)^T \phi (x_j)\) 是核。项 \(\alpha_i\) 被称为对偶系数,它们受 \(C\) 的上限约束。这种对偶表示突出了训练向量通过函数 \(\phi\) 隐式映射到更高(可能无限)维空间的事实:参见核技巧。
一旦优化问题得到解决,给定样本 \(x\) 的 decision_function 输出变为
预测的类别对应于其符号。我们只需要对支持向量(即位于间隔内的样本)求和,因为其他样本的对偶系数 \(\alpha_i\) 为零。
这些参数可以通过属性 dual_coef_(包含乘积 \(y_i \alpha_i\))、support_vectors_(包含支持向量)和 intercept_(包含独立项 \(b\))进行访问。
注意
虽然源自 libsvm 和 liblinear 的 SVM 模型使用 C 作为正则化参数,但大多数其他估计器使用 alpha。两个模型之间正则化量的精确等效关系取决于模型优化的具体目标函数。例如,当使用的估计器是 Ridge 回归时,它们之间的关系为 \(C = \frac{1}{\alpha}\)。
LinearSVC#
原始问题可以等价地表述为
其中我们使用了合页损失(hinge loss)。这是 LinearSVC 直接优化的形式,但与对偶形式不同,这种形式不涉及样本间的内积,因此无法应用著名的核技巧。这就是为什么 LinearSVC 只支持线性核的原因(\(\phi\) 是恒等函数)。
1.4.7.2. SVR#
给定训练向量 \(x_i \in \mathbb{R}^p\),i=1,…, n,以及一个向量 \(y \in \mathbb{R}^n\),\(\varepsilon\)-SVR 解决以下原始问题
这里,我们惩罚那些预测值与其真实目标至少相距 \(\varepsilon\) 的样本。这些样本根据其预测值是位于 \(\varepsilon\) 管道上方还是下方,通过 \(\zeta_i\) 或 \(\zeta_i^*\) 来惩罚目标函数。
对偶问题是
其中 \(e\) 是全一向量,\(Q\) 是一个 \(n\) 乘 \(n\) 的半正定矩阵,\(Q_{ij} \equiv K(x_i, x_j) = \phi (x_i)^T \phi (x_j)\) 是核。这里训练向量通过函数 \(\phi\) 隐式映射到更高(可能无限)维空间。
预测值为
这些参数可以通过属性 dual_coef_ 访问,该属性保存差值 \(\alpha_i - \alpha_i^*\);通过 support_vectors_ 访问,该属性保存支持向量;以及通过 intercept_ 访问,该属性保存独立项 \(b\)。
1.4.8. 实现细节#
在内部,我们使用 libsvm [12] 和 liblinear [11] 来处理所有计算。这些库是使用 C 和 Cython 进行封装的。有关实现和所用算法的详细信息,请参阅它们各自的论文。
参考文献