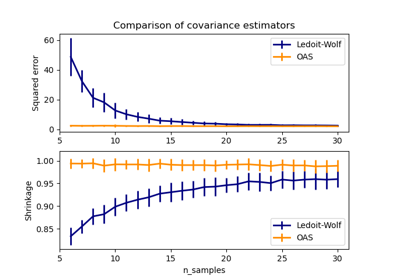
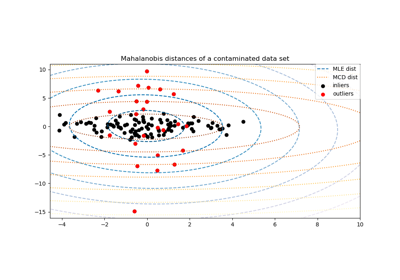
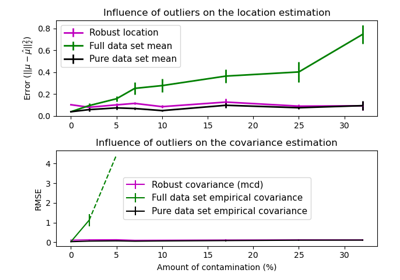
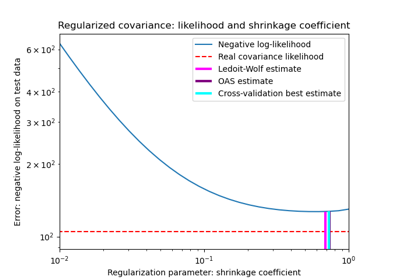
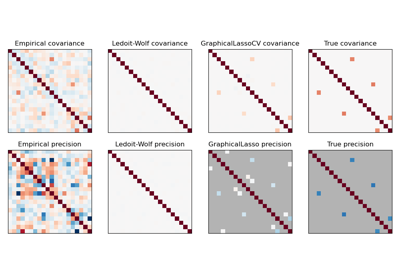
协方差估计# 关于 sklearn.covariance 模块的示例。 Ledoit-Wolf vs OAS 估计 Ledoit-Wolf vs OAS 估计 鲁棒协方差估计与马氏距离相关性 鲁棒协方差估计与马氏距离相关性 鲁棒协方差估计与经验协方差估计比较 鲁棒协方差估计与经验协方差估计比较 收缩协方差估计:LedoitWolf vs OAS 和最大似然 收缩协方差估计:LedoitWolf vs OAS 和最大似然 稀疏逆协方差估计 稀疏逆协方差估计