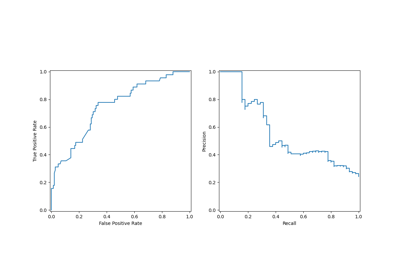
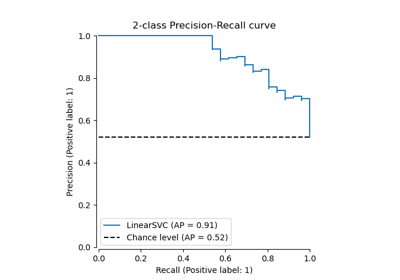
precision_recall_curve#
- sklearn.metrics.precision_recall_curve(y_true, y_score, *, pos_label=None, sample_weight=None, drop_intermediate=False)[source]#
计算不同概率阈值下的精确率-召回率对。
注意:此实现仅限于二分类任务。
精确率是
tp / (tp + fp)的比率,其中tp是真阳性数量,fp是假阳性数量。精确率直观地表示分类器将阴性样本不标记为阳性的能力。召回率是
tp / (tp + fn)的比率,其中tp是真阳性数量,fn是假阴性数量。召回率直观地表示分类器找到所有阳性样本的能力。最后两个精确率和召回率值分别为 1. 和 0.,它们没有对应的阈值。这确保了图表从 y 轴开始。
第一个精确率和召回率值分别是精确率=类别平衡和召回率=1.0,这对应于一个总是预测为阳性类别的分类器。
在用户指南中阅读更多内容。
- 参数:
- y_true形状为 (n_samples,) 的类数组
真实的二分类标签。如果标签不是 {-1, 1} 或 {0, 1},则应明确给出 pos_label。
- y_score形状为 (n_samples,) 的类数组
目标得分,可以是正类的概率估计,也可以是未阈值化的决策度量(如某些分类器的
decision_function所返回)。对于 decision_function 得分,大于或等于零的值应表示正类。- pos_labelint, float, bool 或 str, 默认值=None
正类的标签。当
pos_label=None时,如果 y_true 在 {-1, 1} 或 {0, 1} 中,则pos_label设置为 1,否则将引发错误。- sample_weight形状为 (n_samples,) 的类数组, 默认值=None
样本权重。
- drop_intermediatebool, 默认值=False
是否删除一些次优阈值,这些阈值不会出现在绘制的精确率-召回率曲线上。这对于创建更轻量级的精确率-召回率曲线很有用。
版本 1.3 新增。
- 返回:
- precision形状为 (n_thresholds + 1,) 的 ndarray
精确率值,其中第 i 个元素是得分 >= thresholds[i] 的预测的精确率,最后一个元素是 1。
- recall形状为 (n_thresholds + 1,) 的 ndarray
递减的召回率值,其中第 i 个元素是得分 >= thresholds[i] 的预测的召回率,最后一个元素是 0。
- thresholds形状为 (n_thresholds,) 的 ndarray
用于计算精确率和召回率的决策函数的递增阈值,其中
n_thresholds = len(np.unique(y_score))。
另请参见
PrecisionRecallDisplay.from_estimator给定二分类器绘制精确率-召回率曲线。
PrecisionRecallDisplay.from_predictions使用二分类器的预测绘制精确率-召回率曲线。
average_precision_score从预测得分计算平均精确率。
det_curve计算不同概率阈值下的错误率。
roc_curve计算受试者工作特征 (ROC) 曲线。
示例
>>> import numpy as np >>> from sklearn.metrics import precision_recall_curve >>> y_true = np.array([0, 0, 1, 1]) >>> y_scores = np.array([0.1, 0.4, 0.35, 0.8]) >>> precision, recall, thresholds = precision_recall_curve( ... y_true, y_scores) >>> precision array([0.5 , 0.66666667, 0.5 , 1. , 1. ]) >>> recall array([1. , 1. , 0.5, 0.5, 0. ]) >>> thresholds array([0.1 , 0.35, 0.4 , 0.8 ])