DBSCAN#
- class sklearn.cluster.DBSCAN(eps=0.5, *, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)[source]#
从向量数组或距离矩阵执行 DBSCAN 聚类。
DBSCAN - 基于密度的含噪声应用空间聚类。它能找到高密度的核心样本并从中扩展聚类。适用于包含相似密度聚类的数据。
该实现的内存复杂度在最坏情况下为 \(O({n}^2)\),这可能发生在
eps参数较大而min_samples较低时,而原始 DBSCAN 仅使用线性内存。更多详情请参阅下面的“备注”。在用户指南中阅读更多。
- 参数:
- eps浮点数,默认值=0.5
两个样本之间被视为彼此邻近的最大距离。这并非集群内点之间距离的最大界限。这是为您的数据集和距离函数选择合适 DBSCAN 参数最重要的参数。
- min_samples整数,默认值=5
一个邻域中被视为核心点的样本数量(或总权重)。这包括该点本身。如果将
min_samples设置为更高的值,DBSCAN 将找到更密集的聚类;而如果设置为更低的值,找到的聚类将更稀疏。- metric字符串或可调用对象,默认值='euclidean'
计算特征数组中实例之间距离时使用的度量。如果度量是字符串或可调用对象,它必须是
sklearn.metrics.pairwise_distances允许的度量参数选项之一。如果度量是“precomputed”(预计算),则 X 被假定为距离矩阵且必须是方阵。X 可以是稀疏图,在这种情况下,只有“非零”元素才可能被视为 DBSCAN 的邻居。0.17 版新增: 度量 precomputed 用于接受预计算的稀疏矩阵。
- metric_params字典,默认值=None
度量函数的额外关键字参数。
0.19 版新增。
- algorithm{'auto', 'ball_tree', 'kd_tree', 'brute'} 之一,默认值='auto'
NearestNeighbors 模块用于计算点间距离和查找最近邻居的算法。有关详细信息,请参阅 NearestNeighbors 模块文档。
- leaf_size整数,默认值=30
传递给 BallTree 或 cKDTree 的叶子大小。这会影响树的构建和查询速度,以及存储树所需的内存。最优值取决于问题的性质。
- p浮点数,默认值=None
用于计算点之间距离的闵可夫斯基度量的幂。如果为 None,则
p=2(相当于欧几里得距离)。- n_jobs整数,默认值=None
要运行的并行作业数。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。有关更多详细信息,请参阅术语表。
- 属性:
- core_sample_indices_形状为 (n_core_samples,) 的 ndarray
核心样本的索引。
- components_形状为 (n_core_samples, n_features) 的 ndarray
通过训练找到的每个核心样本的副本。
- labels_形状为 (n_samples) 的 ndarray
fit() 方法中给定数据集中每个点的聚类标签。噪声样本被赋予标签 -1。
- n_features_in_整数
在fit期间看到的特征数量。
0.24 版新增。
- feature_names_in_形状为 (
n_features_in_,) 的 ndarray 在fit期间看到的特征名称。仅当
X的所有特征名称都是字符串时才定义。1.0 版新增。
另请参阅
OPTICS在多个 eps 值下进行类似的聚类。我们的实现针对内存使用进行了优化。
备注
此实现批量计算所有邻域查询,这将内存复杂度增加到 O(n.d),其中 d 是平均邻居数,而原始 DBSCAN 的内存复杂度为 O(n)。根据所使用的
algorithm,在查询这些最近邻域时可能会导致更高的内存复杂度。避免查询复杂性的一种方法是,使用
NearestNeighbors.radius_neighbors_graph并设置mode='distance'来分块预计算稀疏邻域,然后在此处使用metric='precomputed'。另一种减少内存和计算时间的方法是移除(近似)重复点,并改用
sample_weight。OPTICS提供了一种类似的聚类方法,且内存使用量较低。参考文献
Ester, M., H. P. Kriegel, J. Sander, and X. Xu, “一种用于发现大型空间数据库中带噪声聚类的基于密度的算法”。收录于:第二届国际知识发现与数据挖掘会议论文集,俄勒冈州波特兰,AAAI出版社,第226-231页。1996
Schubert, E., Sander, J., Ester, M., Kriegel, H. P., & Xu, X. (2017)。“DBSCAN 再探究,再探究:为什么以及如何(仍然)使用 DBSCAN。” ACM Transactions on Database Systems (TODS), 42(3), 19。
示例
>>> from sklearn.cluster import DBSCAN >>> import numpy as np >>> X = np.array([[1, 2], [2, 2], [2, 3], ... [8, 7], [8, 8], [25, 80]]) >>> clustering = DBSCAN(eps=3, min_samples=2).fit(X) >>> clustering.labels_ array([ 0, 0, 0, 1, 1, -1]) >>> clustering DBSCAN(eps=3, min_samples=2)
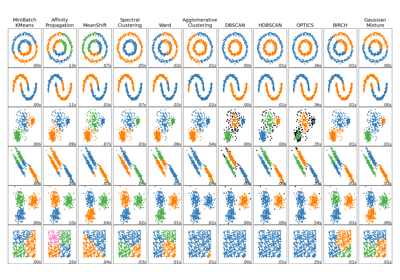
有关示例,请参阅DBSCAN 聚类算法演示。
有关 DBSCAN 与其他聚类算法的比较,请参阅在玩具数据集上比较不同的聚类算法
- fit(X, y=None, sample_weight=None)[source]#
从特征或距离矩阵执行 DBSCAN 聚类。
- 参数:
- X形状为 (n_samples, n_features) 或 (n_samples, n_samples) 的 {array-like, 稀疏矩阵}
要聚类的训练实例,如果
metric='precomputed'则为实例之间的距离。如果提供了稀疏矩阵,它将被转换为稀疏的csr_matrix。- y被忽略
未使用,按约定此处存在以保持 API 一致性。
- sample_weight形状为 (n_samples,) 的 array-like,默认值=None
每个样本的权重,使得权重至少为
min_samples的样本本身就是核心样本;具有负权重的样本可能会阻止其 eps 邻居成为核心样本。请注意,权重是绝对值,默认为 1。
- 返回:
- self对象
返回一个拟合后的自身实例。
- fit_predict(X, y=None, sample_weight=None)[source]#
从数据或距离矩阵计算聚类并预测标签。
- 参数:
- X形状为 (n_samples, n_features) 或 (n_samples, n_samples) 的 {array-like, 稀疏矩阵}
要聚类的训练实例,如果
metric='precomputed'则为实例之间的距离。如果提供了稀疏矩阵,它将被转换为稀疏的csr_matrix。- y被忽略
未使用,按约定此处存在以保持 API 一致性。
- sample_weight形状为 (n_samples,) 的 array-like,默认值=None
每个样本的权重,使得权重至少为
min_samples的样本本身就是核心样本;具有负权重的样本可能会阻止其 eps 邻居成为核心样本。请注意,权重是绝对值,默认为 1。
- 返回:
- labels形状为 (n_samples,) 的 ndarray
聚类标签。噪声样本被赋予标签 -1。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查看用户指南以了解路由机制的工作原理。
- 返回:
- routingMetadataRequest
一个封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deep布尔值,默认值=True
如果为 True,将返回此估计器及其包含的子对象(如果它们是估计器)的参数。
- 返回:
- params字典
参数名称映射到其值。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') DBSCAN[source]#
请求传递给
fit方法的元数据。请注意,此方法仅在
enable_metadata_routing=True时才相关(请参阅sklearn.set_config)。请参阅用户指南以了解路由机制的工作原理。每个参数的选项为:
True: 请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略该请求。False: 不请求元数据,且元估计器不会将其传递给fit。None: 不请求元数据,如果用户提供元数据,元估计器将引发错误。str: 元数据应以这个给定别名而非原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。1.3 版新增。
注意
此方法仅在将此估计器用作元估计器的子估计器时才相关,例如在
Pipeline中使用时。否则,它没有效果。- 参数:
- sample_weight字符串、True、False 或 None,默认值=sklearn.utils.metadata_routing.UNCHANGED
fit中sample_weight参数的元数据路由。
- 返回:
- self对象
更新后的对象。