2.8. 密度估计#
密度估计介于无监督学习、特征工程和数据建模之间。一些最流行和有用的密度估计技术包括混合模型,如高斯混合模型(GaussianMixture),以及基于邻居的方法,如核密度估计(KernelDensity)。高斯混合模型在聚类的上下文中进行了更充分的讨论,因为该技术作为一种无监督聚类方案也很有用。
密度估计是一个非常简单的概念,大多数人已经熟悉一种常见的密度估计技术:直方图。
2.8.1. 密度估计:直方图#
直方图是一种简单的数据可视化方法,其中定义了数据“桶”,并统计每个桶内的数据点数量。以下图的左上角面板展示了一个直方图示例。
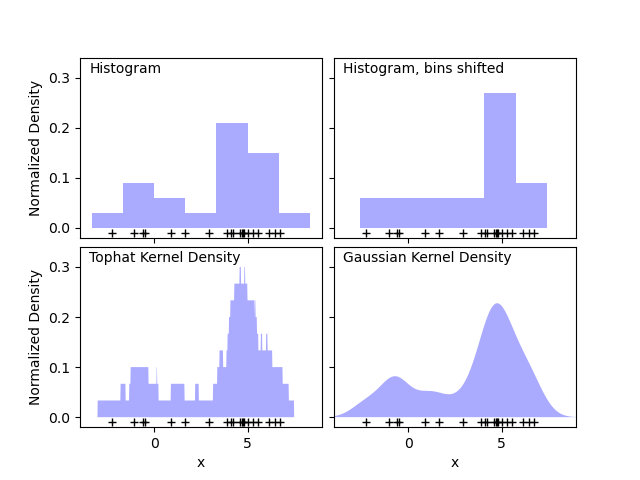
然而,直方图的一个主要问题是,分桶的选择可能对最终的可视化产生不成比例的影响。考虑上图的右上角面板。它显示了相同数据的直方图,但数据桶向右平移。两个可视化的结果看起来完全不同,可能导致对数据的不同解释。
直观地,我们也可以将直方图想象成一堆方块,每个数据点一个方块。通过在适当的网格空间中堆叠方块,我们得到了直方图。但是,如果不是在规则网格上堆叠方块,而是将每个方块中心放置在其所代表的数据点上,并求和每个位置的总高度呢?这个想法就产生了左下角的可是化结果。它可能不如直方图那么整洁,但数据驱动方块位置的事实意味着它能更好地表示底层数据。
这种可视化是核密度估计的一个例子,本例中使用了平顶核(即在每个点上放置一个方形方块)。通过使用更平滑的核,我们可以得到一个更平滑的分布。右下角的图显示了高斯核密度估计,其中每个点都为总和贡献了一条高斯曲线。结果是一个平滑的密度估计,它从数据中得出,并作为点分布的强大非参数模型。
2.8.2. 核密度估计#
scikit-learn 中的核密度估计在 KernelDensity 估计器中实现,该估计器使用 Ball Tree 或 KD Tree 进行高效查询(有关这些的讨论,请参阅最近邻)。尽管上述示例为简单起见使用了1D数据集,但核密度估计可以在任意维度上进行,尽管在实践中,维度灾难会导致其在高维度下的性能下降。
在下图中,从双峰分布中抽取了100个点,并显示了三种不同核选择下的核密度估计
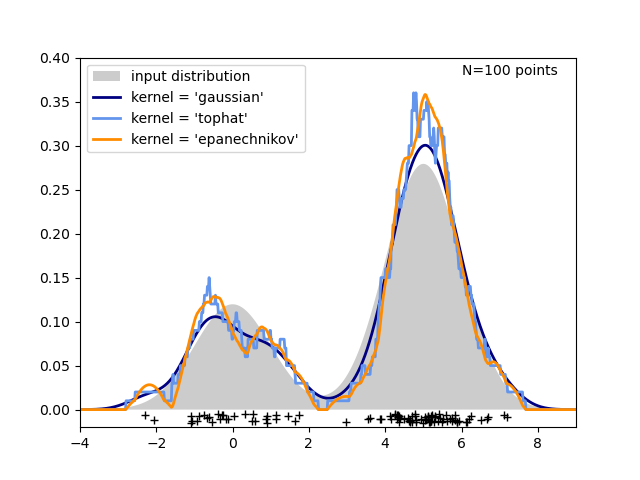
很明显,核的形状如何影响所得分布的平滑度。scikit-learn 核密度估计器可以按如下方式使用
>>> from sklearn.neighbors import KernelDensity
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> kde = KernelDensity(kernel='gaussian', bandwidth=0.2).fit(X)
>>> kde.score_samples(X)
array([-0.41075698, -0.41075698, -0.41076071, -0.41075698, -0.41075698,
-0.41076071])
这里我们使用了 kernel='gaussian',如上所示。在数学上,核是一个正函数 \(K(x;h)\),由带宽参数 \(h\) 控制。给定这种核形式,点集 \(x_i; i=1\cdots N\) 中点 \(y\) 处的密度估计由下式给出
这里的带宽充当平滑参数,控制结果中偏差和方差之间的权衡。大带宽导致非常平滑(即高偏差)的密度分布。小带宽导致不平滑(即高方差)的密度分布。
参数 bandwidth 控制这种平滑。可以手动设置此参数,也可以使用 Scott 和 Silverman 的估计方法。
KernelDensity 实现了几种常见的核形式,如下图所示
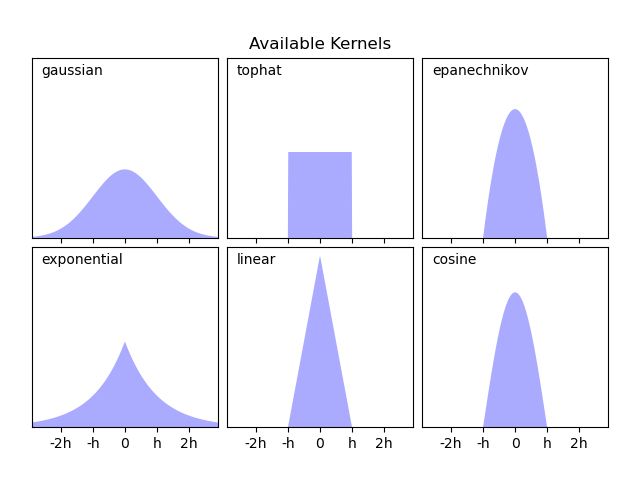
核的数学表达式#
这些核的形式如下:
高斯核(
kernel = 'gaussian')\(K(x; h) \propto \exp(- \frac{x^2}{2h^2} )\)
平顶核(
kernel = 'tophat')\(K(x; h) \propto 1\) 若 \(x < h\)
Epanechnikov 核(
kernel = 'epanechnikov')\(K(x; h) \propto 1 - \frac{x^2}{h^2}\)
指数核(
kernel = 'exponential')\(K(x; h) \propto \exp(-x/h)\)
线性核(
kernel = 'linear')\(K(x; h) \propto 1 - x/h\) 若 \(x < h\)
余弦核(
kernel = 'cosine')\(K(x; h) \propto \cos(\frac{\pi x}{2h})\) 若 \(x < h\)
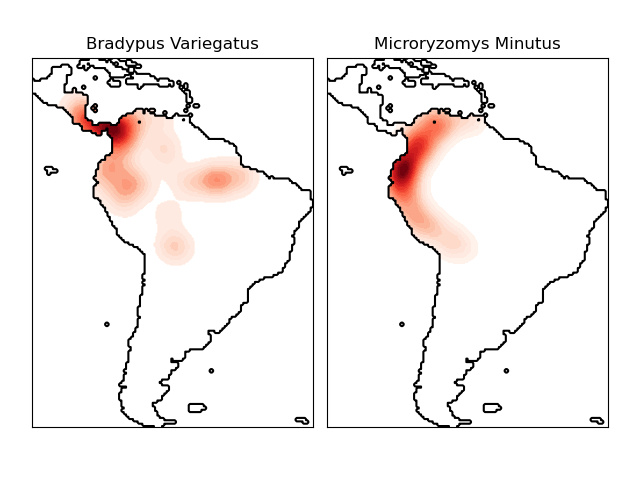
核密度估计器可以与任何有效的距离度量一起使用(有关可用度量列表,请参阅DistanceMetric),尽管结果仅在欧几里得度量下才进行正确归一化。一个特别有用的度量是半正矢距离,它测量球体上点之间的角距离。以下是使用核密度估计可视化地理空间数据的示例,本例中为南美洲大陆上两种不同物种的观测分布
核密度估计的另一个有用应用是学习数据集的非参数生成模型,以便有效地从该生成模型中抽取新样本。以下是使用此过程创建一组新手写数字的示例,其中使用了基于数据PCA投影学习的高斯核

“新”数据由输入数据的线性组合组成,其权重根据 KDE 模型进行概率性抽取。
示例
简单一维核密度估计:一维简单核密度估计的计算。
核密度估计:使用核密度估计学习手写数字数据的生成模型,并从该模型中抽取新样本的示例。
物种分布的核密度估计:使用半正矢距离度量可视化地理空间数据的核密度估计示例。