9.1. 计算扩展策略:更大的数据#
对于某些应用场景,样本数量、特征数量(或两者兼有)和/或需要处理它们的速度对于传统方法来说极具挑战性。在这些情况下,scikit-learn提供了一些选项供您考虑,以使您的系统能够扩展。
9.1.1. 使用核外学习进行实例扩展#
核外(或“外部存储”)学习是一种用于从无法放入计算机主内存(RAM)的数据中进行学习的技术。
下面是一个为实现此目标而设计的系统草图
一种流式传输实例的方法
一种从实例中提取特征的方法
一种增量算法
9.1.1.1. 流式传输实例#
基本上,1. 可以是从硬盘上的文件、数据库、网络流等生成实例的读取器。然而,如何实现这一点的细节超出了本文档的范围。
9.1.1.2. 提取特征#
2. 可以是scikit-learn支持的各种特征提取方法中任何相关的方法。然而,当处理需要向量化且特征或值集事先未知的数据时,应特别小心。一个很好的例子是文本分类,在训练过程中可能会发现未知术语。如果从应用的角度来看,对数据进行多次遍历是合理的,则可以使用有状态向量化器。否则,可以通过使用无状态特征提取器来增加难度。目前,实现此目的的首选方法是使用所谓的哈希技巧,如针对表示为Python字典列表的分类变量数据集实现的sklearn.feature_extraction.FeatureHasher,或针对文本文档实现的sklearn.feature_extraction.text.HashingVectorizer。
9.1.1.3. 增量学习#
最后,对于3.,我们在scikit-learn中有很多选项。尽管并非所有算法都能增量学习(即无需一次性看到所有实例),但所有实现partial_fit API的估计器都是候选者。实际上,从一小批实例(有时称为“在线学习”)中增量学习的能力是核外学习的关键,因为它保证在任何给定时间主内存中只有少量实例。选择一个平衡相关性和内存占用的小批量大小可能需要一些调整[1]。
以下是针对不同任务的增量估计器列表
对于分类而言,一个需要注意的重要事项是,尽管无状态特征提取例程可能能够处理新的/未见的属性,但增量学习器本身可能无法处理新的/未见的目标类别。在这种情况下,您必须使用classes=参数将所有可能的类别传递给第一个partial_fit调用。
选择合适的算法时要考虑的另一个方面是,并非所有算法都随着时间对每个示例给予相同的重视。具体来说,即使在处理了许多示例之后,Perceptron仍然对标记错误的示例很敏感,而SGD*系列对这类伪影具有更强的鲁棒性。相反,后者也倾向于在流中较晚出现时,对明显不同但标记正确的示例给予较少的重视,因为它们的学习率会随着时间推移而降低。
9.1.1.4. 示例#
最后,我们有一个关于文本文档的核外分类的完整示例。它旨在为希望构建核外学习系统的人员提供一个起点,并演示了上面讨论的大部分概念。
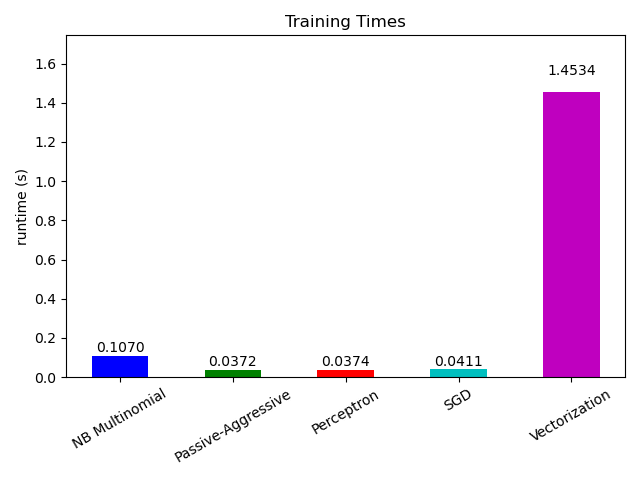
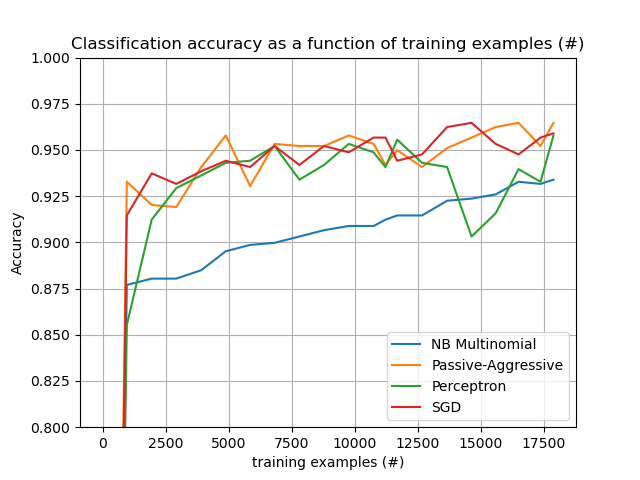
此外,它还展示了不同算法的性能随着处理示例数量的增加而演变的情况。
现在看一下不同部分的计算时间,我们发现向量化比学习本身要昂贵得多。在不同的算法中,MultinomialNB是最昂贵的,但其开销可以通过增加小批量的大小来减轻(练习:在程序中将minibatch_size更改为100和10000并进行比较)。