3.3. 调整类别预测的决策阈值#
分类最好分为两个部分:
学习预测模型的统计问题,理想情况下是预测类别概率;
根据这些概率预测采取具体行动的决策问题。
让我们以一个与天气预报相关的简单例子来说明:第一点与回答“明天下雨的概率是多少?”有关,第二点与回答“明天我是否应该带伞?”有关。
在 scikit-learn API 中,第一点是使用predict_proba 或decision_function提供分数来解决的。前者返回每个类别的条件概率估计\(P(y|X)\),而后者返回每个类别的决策分数。
相应的标签决策是通过predict获得的。在二元分类中,决策规则或行动是通过对分数进行阈值处理来定义的,从而为每个样本预测单个类别标签。在 scikit-learn 的二元分类中,类别标签预测是通过硬编码的截止规则获得的:当条件概率\(P(y|X)\)大于 0.5(使用predict_proba获得)或决策分数大于 0(使用decision_function获得)时,预测正类别。
在这里,我们展示一个例子来说明条件概率估计\(P(y|X)\)和类别标签之间的关系。
>>> from sklearn.datasets import make_classification
>>> from sklearn.tree import DecisionTreeClassifier
>>> X, y = make_classification(random_state=0)
>>> classifier = DecisionTreeClassifier(max_depth=2, random_state=0).fit(X, y)
>>> classifier.predict_proba(X[:4])
array([[0.94 , 0.06 ],
[0.94 , 0.06 ],
[0.0416..., 0.9583...],
[0.0416..., 0.9583...]])
>>> classifier.predict(X[:4])
array([0, 0, 1, 1])
虽然这些硬编码规则乍一看似乎是合理的默认行为,但它们对于大多数用例来说肯定不是理想的。让我们用一个例子来说明。
考虑这样一个场景:一个预测模型被部署来协助医生检测肿瘤。在这种情况下,医生很可能感兴趣的是识别所有癌症患者,并且不遗漏任何癌症患者,以便他们可以为他们提供正确的治疗。换句话说,医生优先考虑实现高召回率。当然,这种对召回率的重视是以可能出现更多假阳性预测、降低模型精度为代价的。这是医生愿意承担的风险,因为漏诊癌症的代价远高于进一步诊断测试的代价。因此,在决定是否将患者归类为患有癌症时,当条件概率估计远低于 0.5 时,将其归类为癌症阳性可能更有益。
3.3.1. 调整后的决策阈值#
解决引言中所述问题的一种方法是在模型训练完成后调整分类器的决策阈值。TunedThresholdClassifierCV 使用内部交叉验证来调整此阈值。最佳阈值的选择旨在最大化给定的指标。
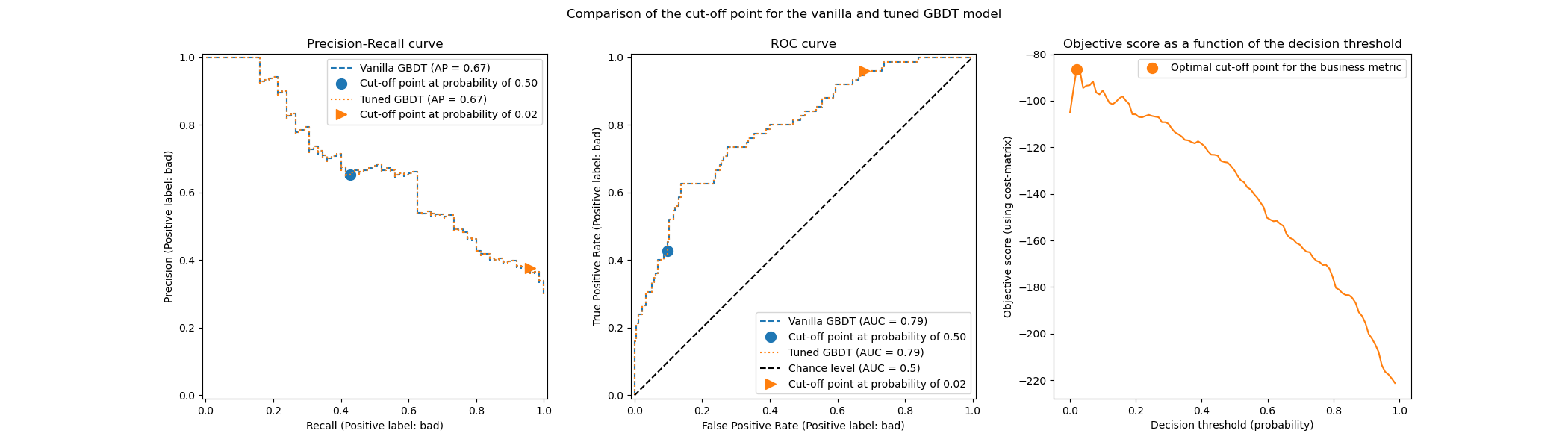
下图说明了梯度提升分类器的决策阈值调整。虽然普通分类器和调整后的分类器提供相同的predict_proba 输出,因此具有相同的受试者工作特征 (ROC) 曲线和精确率-召回率曲线,但由于调整后的决策阈值,类别标签预测结果不同。普通分类器预测条件概率大于 0.5 的目标类别,而调整后的分类器预测概率非常低(约 0.02)的目标类别。此决策阈值优化了业务(在本例中为保险公司)定义的效用指标。
3.3.1.1. 调整决策阈值的选项#
可以通过参数scoring控制的不同策略来调整决策阈值。
调整阈值的一种方法是最大化预定义的 scikit-learn 指标。可以通过调用函数get_scorer_names找到这些指标。默认情况下,使用的是平衡准确率作为指标,但请注意,应根据用例选择有意义的指标。
注意
重要的是要注意,这些指标带有默认参数,特别是目标类别的标签(即pos_label)。因此,如果此标签不适合您的应用程序,则需要定义一个评分器并使用make_scorer传递正确的pos_label(以及其他参数)。请参考Callable scorers以获取定义自己的评分函数的信息。例如,我们展示了在最大化f1_score时如何将目标标签0的信息传递给评分器。
>>> from sklearn.linear_model import LogisticRegression
>>> from sklearn.model_selection import TunedThresholdClassifierCV
>>> from sklearn.metrics import make_scorer, f1_score
>>> X, y = make_classification(
... n_samples=1_000, weights=[0.1, 0.9], random_state=0)
>>> pos_label = 0
>>> scorer = make_scorer(f1_score, pos_label=pos_label)
>>> base_model = LogisticRegression()
>>> model = TunedThresholdClassifierCV(base_model, scoring=scorer)
>>> scorer(model.fit(X, y), X, y)
0.88...
>>> # compare it with the internal score found by cross-validation
>>> model.best_score_
0.86...
3.3.1.2. 关于内部交叉验证的重要说明#
默认情况下,TunedThresholdClassifierCV 使用 5 折分层交叉验证来调整决策阈值。cv参数允许控制交叉验证策略。可以通过设置cv="prefit"并提供已拟合的分类器来绕过交叉验证。在这种情况下,决策阈值是在提供给fit方法的数据上进行调整的。
但是,使用此选项时应格外小心。由于存在过拟合的风险,因此切勿使用相同的数据来训练分类器和调整决策阈值。有关更多详细信息,请参阅以下示例部分(参见考虑模型重拟合和交叉验证)。如果资源有限,请考虑为cv使用浮点数以限制为内部单次训练测试拆分。
cv="prefit"选项仅应在提供的分类器已完成训练并且您只想使用新的验证集查找最佳决策阈值时使用。
3.3.1.3. 手动设置决策阈值#
前面几节讨论了查找最佳决策阈值的策略。也可以使用类FixedThresholdClassifier手动设置决策阈值。如果您不想在调用fit时重拟合模型,请使用FrozenEstimator包装您的子估计器,并执行FixedThresholdClassifier(FrozenEstimator(estimator), ...)。
3.3.1.4. 示例#
请参阅题为后期调整决策函数的临界点的示例,以了解决策阈值的后期调整。
请参阅题为后期调整决策阈值以进行成本敏感学习的示例,以了解成本敏感学习和决策阈值调整。