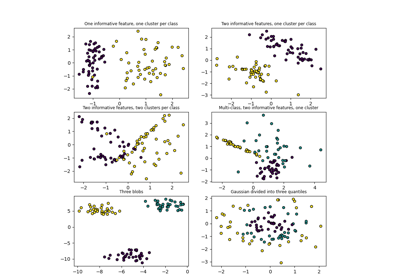
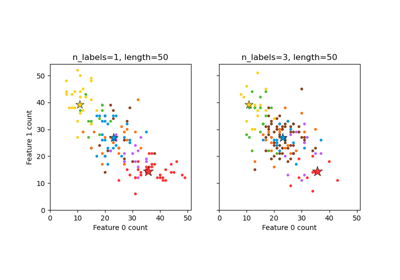
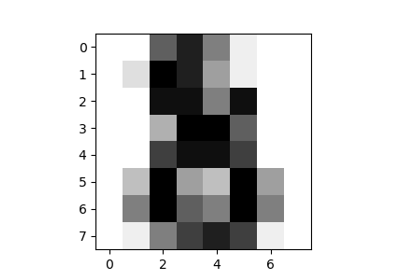
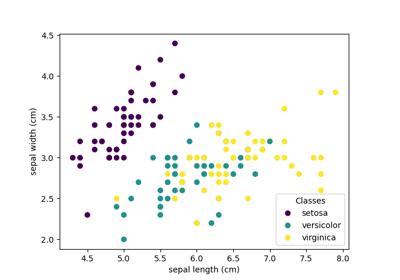
数据集示例# 有关 sklearn.datasets 模块的示例。 绘制随机生成的分类数据集 绘制随机生成的分类数据集 绘制随机生成的多标签数据集 绘制随机生成的多标签数据集 数字数据集 数字数据集 鸢尾花数据集 鸢尾花数据集