多类训练元估计器的概述#
在本例中,我们将讨论当目标变量由两个以上类别组成时的分类问题。这称为多类分类。
在 scikit-learn 中,所有估计器都开箱即用地支持多类分类:为最终用户实现了最合理的策略。 sklearn.multiclass 模块实现了各种策略,可以用于实验或开发仅支持二元分类的第三方估计器。
sklearn.multiclass 包括 OvO/OvR 策略,用于通过拟合一组二元分类器来训练多类分类器(OneVsOneClassifier 和 OneVsRestClassifier 元估计器)。本例将回顾它们。
酵母 UCI 数据集#
在本例中,我们使用一个 UCI 数据集 [1],通常称为酵母数据集。我们使用 sklearn.datasets.fetch_openml 函数从 OpenML 加载数据集。
from sklearn.datasets import fetch_openml
X, y = fetch_openml(data_id=181, as_frame=True, return_X_y=True)
为了了解我们正在处理的数据科学问题的类型,我们可以检查我们想要构建预测模型的目标。
y.value_counts().sort_index()
class_protein_localization
CYT 463
ERL 5
EXC 35
ME1 44
ME2 51
ME3 163
MIT 244
NUC 429
POX 20
VAC 30
Name: count, dtype: int64
我们看到目标是离散的,由 10 个类别组成。因此,我们处理的是一个多类分类问题。
策略比较#
在以下实验中,我们使用 DecisionTreeClassifier 和 RepeatedStratifiedKFold 交叉验证,进行 3 次分割和 5 次重复。
我们比较以下策略
:class:~sklearn.tree.DecisionTreeClassifier 可以处理多类分类,无需任何特殊调整。它的工作原理是将训练数据分解成更小的子集,并关注每个子集中最常见的类别。通过重复此过程,模型可以准确地将输入数据分类到多个不同的类别中。
OneVsOneClassifier训练一组二元分类器,其中每个分类器都经过训练来区分两个类别。OneVsRestClassifier: 训练一组二元分类器,其中每个分类器都经过训练来区分一个类别和其余类别。OutputCodeClassifier: 训练一组二元分类器,其中每个分类器都经过训练来区分一组类别和其余类别。类别集由代码本定义,代码本在 scikit-learn 中是随机生成的。此方法公开了一个参数code_size来控制代码本的大小。我们将其设置为大于 1,因为我们对压缩类别表示不感兴趣。
import pandas as pd
from sklearn.model_selection import RepeatedStratifiedKFold, cross_validate
from sklearn.multiclass import (
OneVsOneClassifier,
OneVsRestClassifier,
OutputCodeClassifier,
)
from sklearn.tree import DecisionTreeClassifier
cv = RepeatedStratifiedKFold(n_splits=3, n_repeats=5, random_state=0)
tree = DecisionTreeClassifier(random_state=0)
ovo_tree = OneVsOneClassifier(tree)
ovr_tree = OneVsRestClassifier(tree)
ecoc = OutputCodeClassifier(tree, code_size=2)
cv_results_tree = cross_validate(tree, X, y, cv=cv, n_jobs=2)
cv_results_ovo = cross_validate(ovo_tree, X, y, cv=cv, n_jobs=2)
cv_results_ovr = cross_validate(ovr_tree, X, y, cv=cv, n_jobs=2)
cv_results_ecoc = cross_validate(ecoc, X, y, cv=cv, n_jobs=2)
现在我们可以比较不同策略的统计性能。我们绘制不同策略的得分分布。
from matplotlib import pyplot as plt
scores = pd.DataFrame(
{
"DecisionTreeClassifier": cv_results_tree["test_score"],
"OneVsOneClassifier": cv_results_ovo["test_score"],
"OneVsRestClassifier": cv_results_ovr["test_score"],
"OutputCodeClassifier": cv_results_ecoc["test_score"],
}
)
ax = scores.plot.kde(legend=True)
ax.set_xlabel("Accuracy score")
ax.set_xlim([0, 0.7])
_ = ax.set_title(
"Density of the accuracy scores for the different multiclass strategies"
)
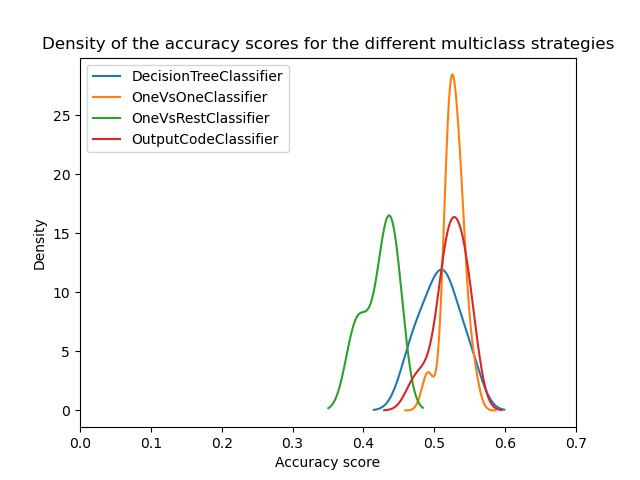
乍一看,我们可以看到决策树分类器的内置策略运行得很好。一对一和纠错输出代码策略运行得更好。但是,一对多策略的运行效果不如其他策略。
事实上,这些结果再现了文献中报道的一些内容,如 [2] 中所述。然而,事情并非看起来那么简单。
超参数搜索的重要性#
后来在 [3] 中表明,如果首先优化基本分类器的超参数,多类策略将显示出相似的得分。
在这里,我们尝试通过至少优化基本决策树的深度来再现这样的结果。
from sklearn.model_selection import GridSearchCV
param_grid = {"max_depth": [3, 5, 8]}
tree_optimized = GridSearchCV(tree, param_grid=param_grid, cv=3)
ovo_tree = OneVsOneClassifier(tree_optimized)
ovr_tree = OneVsRestClassifier(tree_optimized)
ecoc = OutputCodeClassifier(tree_optimized, code_size=2)
cv_results_tree = cross_validate(tree_optimized, X, y, cv=cv, n_jobs=2)
cv_results_ovo = cross_validate(ovo_tree, X, y, cv=cv, n_jobs=2)
cv_results_ovr = cross_validate(ovr_tree, X, y, cv=cv, n_jobs=2)
cv_results_ecoc = cross_validate(ecoc, X, y, cv=cv, n_jobs=2)
scores = pd.DataFrame(
{
"DecisionTreeClassifier": cv_results_tree["test_score"],
"OneVsOneClassifier": cv_results_ovo["test_score"],
"OneVsRestClassifier": cv_results_ovr["test_score"],
"OutputCodeClassifier": cv_results_ecoc["test_score"],
}
)
ax = scores.plot.kde(legend=True)
ax.set_xlabel("Accuracy score")
ax.set_xlim([0, 0.7])
_ = ax.set_title(
"Density of the accuracy scores for the different multiclass strategies"
)
plt.show()
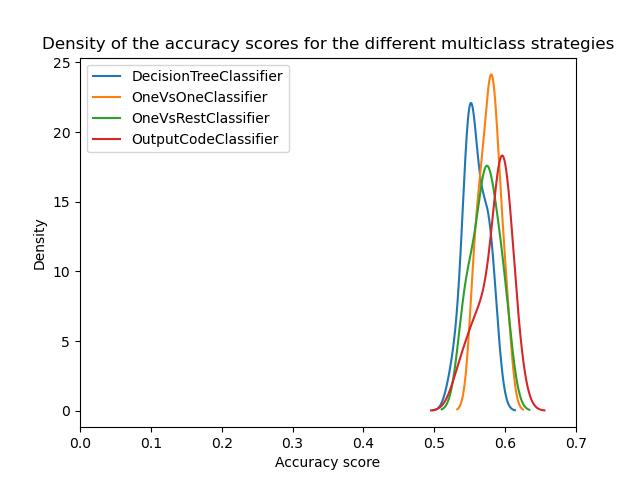
我们可以看到,一旦优化了超参数,所有多类策略都具有相似的性能,正如 [3] 中所讨论的。
结论#
我们可以对这些结果获得一些直觉。
首先,一对一和纠错输出代码在超参数未优化时优于树的原因在于它们集成了一组更大的分类器。集成提高了泛化性能。这有点类似于为什么在没有采取措施优化超参数的情况下,装袋分类器通常比单个决策树表现更好。
然后,我们看到了优化超参数的重要性。事实上,即使像集成这样的技术有助于减少这种影响,在开发预测模型时也应该定期探索它。
最后,重要的是要记住,scikit-learn 中的估计器是使用特定的策略开发的,以便开箱即用地处理多类分类。因此,对于这些估计器来说,这意味着不需要使用不同的策略。这些策略主要用于仅支持二元分类的第三方估计器。在所有情况下,我们还表明应该优化超参数。
参考文献#
脚本总运行时间:(0 分钟 21.625 秒)
相关示例