注意
转到末尾 下载完整的示例代码或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
使用树林进行特征重要性分析#
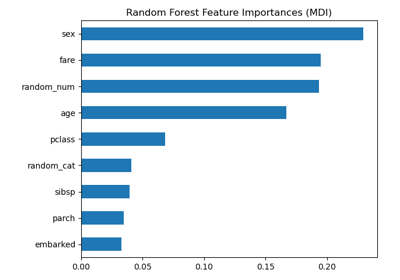
此示例展示了如何使用树林(forest of trees)来评估特征在人工分类任务中的重要性。蓝色条形图显示了森林的特征重要性,误差线表示树间的变异性。
正如所料,该图表明有3个特征具有信息量,而其余特征则没有。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
数据生成和模型拟合#
我们生成一个只包含3个信息特征的合成数据集。我们特意不打乱数据集,以确保信息特征对应于X的前三列。此外,我们将数据集分成训练和测试子集。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(
n_samples=1000,
n_features=10,
n_informative=3,
n_redundant=0,
n_repeated=0,
n_classes=2,
random_state=0,
shuffle=False,
)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
将拟合一个随机森林分类器来计算特征重要性。
from sklearn.ensemble import RandomForestClassifier
feature_names = [f"feature {i}" for i in range(X.shape[1])]
forest = RandomForestClassifier(random_state=0)
forest.fit(X_train, y_train)
基于平均不纯度下降的特征重要性#
特征重要性由拟合属性 feature_importances_ 提供,它们是作为每棵树中不纯度下降积累的平均值和标准差计算的。
警告
基于不纯度的特征重要性对于高基数特征(许多唯一值)可能会产生误导。请参阅下面的 排列特征重要性 作为替代方案。
Elapsed time to compute the importances: 0.014 seconds
让我们绘制基于不纯度的重要性。
import pandas as pd
forest_importances = pd.Series(importances, index=feature_names)
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=std, ax=ax)
ax.set_title("Feature importances using MDI")
ax.set_ylabel("Mean decrease in impurity")
fig.tight_layout()
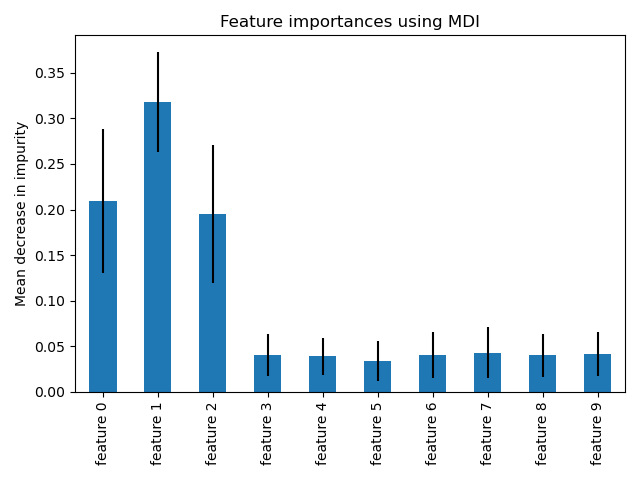
我们观察到,正如预期的那样,前三个特征被认为很重要。
基于特征排列的特征重要性#
排列特征重要性克服了基于不纯度的特征重要性的局限性:它们不会偏向高基数特征,并且可以在留出的测试集上计算。
from sklearn.inspection import permutation_importance
start_time = time.time()
result = permutation_importance(
forest, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
forest_importances = pd.Series(result.importances_mean, index=feature_names)
Elapsed time to compute the importances: 0.906 seconds
计算完整的排列重要性成本更高。每个特征被打乱n次,并使用模型对打乱的数据进行预测,以查看性能下降。有关更多详细信息,请参阅 排列特征重要性。我们现在可以绘制重要性排名。
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=result.importances_std, ax=ax)
ax.set_title("Feature importances using permutation on full model")
ax.set_ylabel("Mean accuracy decrease")
fig.tight_layout()
plt.show()
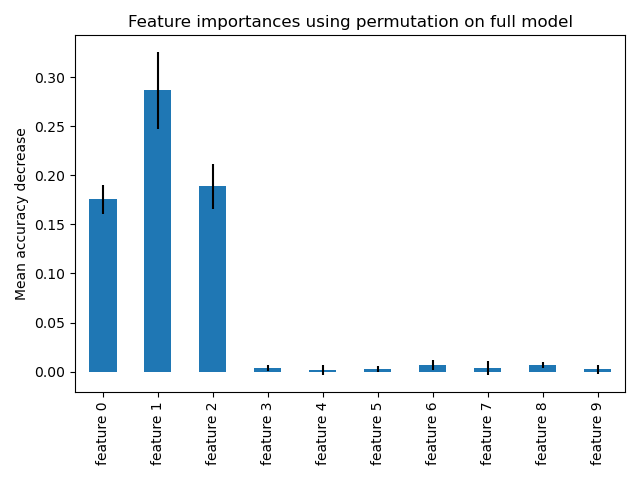
使用这两种方法都检测到相同的特征是最重要的。尽管相对重要性有所不同。从图表可以看出,MDI 比排列重要性更不可能完全忽略某个特征。
脚本总运行时间: (0 minutes 1.351 seconds)
相关示例