注意
转到末尾 下载完整的示例代码或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
绘制交叉验证预测#
此示例展示了如何将 cross_val_predict 与 PredictionErrorDisplay 结合使用来可视化预测误差。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
我们将加载糖尿病数据集并创建一个线性回归模型的实例。
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
X, y = load_diabetes(return_X_y=True)
lr = LinearRegression()
cross_val_predict 返回一个与 y 大小相同的数组,其中每个条目都是通过交叉验证获得的预测值。
from sklearn.model_selection import cross_val_predict
y_pred = cross_val_predict(lr, X, y, cv=10)
由于 cv=10,这意味着我们训练了 10 个模型,每个模型都用于预测 10 个折叠中的一个。我们现在可以使用 PredictionErrorDisplay 来可视化预测误差。
在左轴上,我们绘制观察值 \(y\) 与模型给出的预测值 \(\hat{y}\)。在右轴上,我们绘制残差(即观察值和预测值之间的差异)与预测值。
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
fig, axs = plt.subplots(ncols=2, figsize=(8, 4))
PredictionErrorDisplay.from_predictions(
y,
y_pred=y_pred,
kind="actual_vs_predicted",
subsample=100,
ax=axs[0],
random_state=0,
)
axs[0].set_title("Actual vs. Predicted values")
PredictionErrorDisplay.from_predictions(
y,
y_pred=y_pred,
kind="residual_vs_predicted",
subsample=100,
ax=axs[1],
random_state=0,
)
axs[1].set_title("Residuals vs. Predicted Values")
fig.suptitle("Plotting cross-validated predictions")
plt.tight_layout()
plt.show()
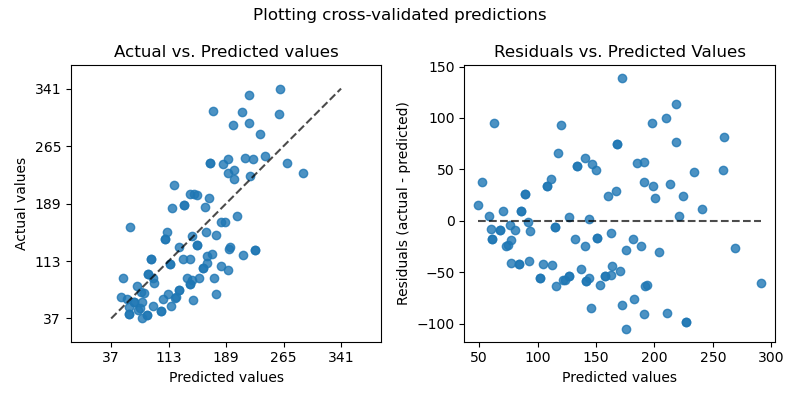
值得注意的是,在此示例中,我们仅将 cross_val_predict 用于可视化目的。
当不同的 CV 折叠在大小和分布上有所不同时,通过计算由 cross_val_predict 返回的连接预测值来评估模型性能的单个性能指标会存在问题。
建议使用 cross_val_score 或 cross_validate 来计算每个折叠的性能指标。
脚本总运行时间: (0 minutes 0.160 seconds)
相关示例