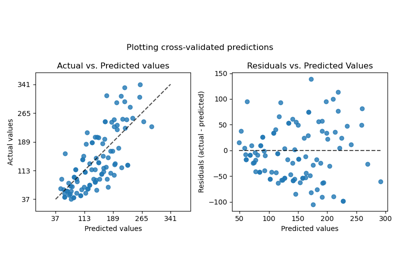
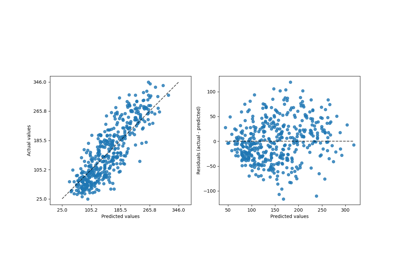
PredictionErrorDisplay#
- class sklearn.metrics.PredictionErrorDisplay(*, y_true, y_pred)[source]#
回归模型预测误差的可视化。
此工具可使用散点图显示“残差 vs 预测值”或“实际值 vs 预测值”,以定性评估回归器的行为,最好是在保留数据点上进行评估。
有关如何创建可视化工具的详细信息,请参阅
from_estimator或from_predictions的文档字符串。所有参数都作为属性存储。有关
scikit-learn可视化工具的一般信息,请阅读 可视化指南 中的更多内容。有关解释这些图表的详细信息,请参阅 模型评估指南。1.2 版本新增。
- 参数:
- y_true形状为 (n_samples,) 的 ndarray
真实值。
- y_pred形状为 (n_samples,) 的 ndarray
预测值。
- 属性:
- line_matplotlib Artist
表示
y_true == y_pred的最佳线。因此,对于kind="predictions",它是一条对角线;对于kind="residuals",它是一条水平线。- errors_lines_matplotlib Artist or None
残差线。如果
with_errors=False,则设置为None。- scatter_matplotlib Artist
散点图数据点。
- ax_matplotlib Axes
包含不同 matplotlib 轴的轴。
- figure_matplotlib Figure
包含散点和线的图形。
另请参阅
PredictionErrorDisplay.from_estimator给定估计器和一些数据的预测误差可视化。
PredictionErrorDisplay.from_predictions给定真实和预测目标的预测误差可视化。
示例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import load_diabetes >>> from sklearn.linear_model import Ridge >>> from sklearn.metrics import PredictionErrorDisplay >>> X, y = load_diabetes(return_X_y=True) >>> ridge = Ridge().fit(X, y) >>> y_pred = ridge.predict(X) >>> display = PredictionErrorDisplay(y_true=y, y_pred=y_pred) >>> display.plot() <...> >>> plt.show()
- classmethod from_estimator(estimator, X, y, *, kind='residual_vs_predicted', subsample=1000, random_state=None, ax=None, scatter_kwargs=None, line_kwargs=None)[source]#
给定回归器和一些数据,绘制预测误差。
有关
scikit-learn可视化工具的一般信息,请阅读 可视化指南 中的更多内容。有关解释这些图表的详细信息,请参阅 模型评估指南。1.2 版本新增。
- 参数:
- estimatorestimator instance
已拟合的回归器或已拟合的
Pipeline,其中最后一个估计器是回归器。- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
输入值。
- yarray-like of shape (n_samples,)
目标值。
- kind{“actual_vs_predicted”, “residual_vs_predicted”}, default=”residual_vs_predicted”
要绘制的图表类型
“actual_vs_predicted”绘制观察值(y 轴)vs. 预测值(x 轴)。
“residual_vs_predicted”绘制残差(即观察值和预测值之间的差异,y 轴)vs. 预测值(x 轴)。
- subsamplefloat, int or None, default=1_000
对要显示在散点图上的样本进行采样。如果为
float,则应在 0 到 1 之间,表示原始数据集的比例。如果为int,则表示散点图上显示的样本数。如果为None,则不应用子采样。默认情况下,将显示 1000 个或更少的样本。- random_stateint or RandomState, default=None
当
subsample不为None时,控制随机性。有关详细信息,请参阅 词汇表。- axmatplotlib axes, default=None
用于绘图的坐标轴对象。如果为
None,则会创建新的图和坐标轴。- scatter_kwargsdict, default=None
传递给
matplotlib.pyplot.scatter调用的关键字字典。- line_kwargsdict, default=None
传递给
matplotlib.pyplot.plot调用以绘制最佳线的关键字字典。
- 返回:
- display
PredictionErrorDisplay 存储计算值的对象。
- display
另请参阅
PredictionErrorDisplay用于回归的预测误差可视化。
PredictionErrorDisplay.from_predictions给定真实和预测目标的预测误差可视化。
示例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import load_diabetes >>> from sklearn.linear_model import Ridge >>> from sklearn.metrics import PredictionErrorDisplay >>> X, y = load_diabetes(return_X_y=True) >>> ridge = Ridge().fit(X, y) >>> disp = PredictionErrorDisplay.from_estimator(ridge, X, y) >>> plt.show()
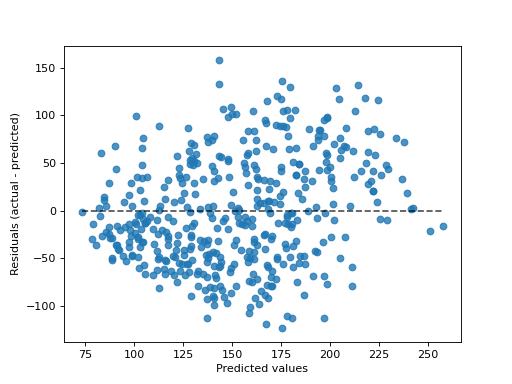
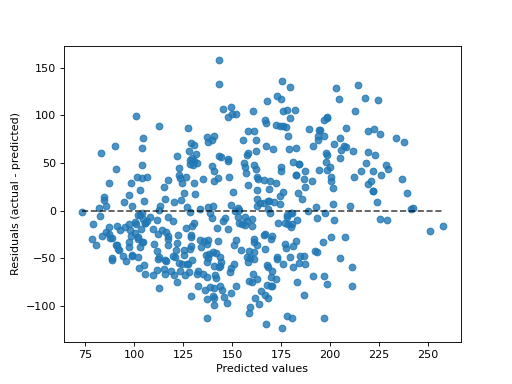
- classmethod from_predictions(y_true, y_pred, *, kind='residual_vs_predicted', subsample=1000, random_state=None, ax=None, scatter_kwargs=None, line_kwargs=None)[source]#
给定真实和预测目标,绘制预测误差。
有关
scikit-learn可视化工具的一般信息,请阅读 可视化指南 中的更多内容。有关解释这些图表的详细信息,请参阅 模型评估指南。1.2 版本新增。
- 参数:
- y_true形状为 (n_samples,) 的 array-like
真实目标值。
- y_pred形状为 (n_samples,) 的类数组
预测目标值。
- kind{“actual_vs_predicted”, “residual_vs_predicted”}, default=”residual_vs_predicted”
要绘制的图表类型
“actual_vs_predicted”绘制观察值(y 轴)vs. 预测值(x 轴)。
“residual_vs_predicted”绘制残差(即观察值和预测值之间的差异,y 轴)vs. 预测值(x 轴)。
- subsamplefloat, int or None, default=1_000
对要显示在散点图上的样本进行采样。如果为
float,则应在 0 到 1 之间,表示原始数据集的比例。如果为int,则表示散点图上显示的样本数。如果为None,则不应用子采样。默认情况下,将显示 1000 个或更少的样本。- random_stateint or RandomState, default=None
当
subsample不为None时,控制随机性。有关详细信息,请参阅 词汇表。- axmatplotlib axes, default=None
用于绘图的坐标轴对象。如果为
None,则会创建新的图和坐标轴。- scatter_kwargsdict, default=None
传递给
matplotlib.pyplot.scatter调用的关键字字典。- line_kwargsdict, default=None
传递给
matplotlib.pyplot.plot调用以绘制最佳线的关键字字典。
- 返回:
- display
PredictionErrorDisplay 存储计算值的对象。
- display
另请参阅
PredictionErrorDisplay用于回归的预测误差可视化。
PredictionErrorDisplay.from_estimator给定估计器和一些数据的预测误差可视化。
示例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import load_diabetes >>> from sklearn.linear_model import Ridge >>> from sklearn.metrics import PredictionErrorDisplay >>> X, y = load_diabetes(return_X_y=True) >>> ridge = Ridge().fit(X, y) >>> y_pred = ridge.predict(X) >>> disp = PredictionErrorDisplay.from_predictions(y_true=y, y_pred=y_pred) >>> plt.show()
- plot(ax=None, *, kind='residual_vs_predicted', scatter_kwargs=None, line_kwargs=None)[source]#
绘制可视化图。
额外的关键字参数将传递给 matplotlib 的
plot。- 参数:
- axmatplotlib axes, default=None
用于绘图的坐标轴对象。如果为
None,则会创建新的图和坐标轴。- kind{“actual_vs_predicted”, “residual_vs_predicted”}, default=”residual_vs_predicted”
要绘制的图表类型
“actual_vs_predicted”绘制观察值(y 轴)vs. 预测值(x 轴)。
“residual_vs_predicted”绘制残差(即观察值和预测值之间的差异,y 轴)vs. 预测值(x 轴)。
- scatter_kwargsdict, default=None
传递给
matplotlib.pyplot.scatter调用的关键字字典。- line_kwargsdict, default=None
传递给
matplotlib.pyplot.plot调用以绘制最佳线的关键字字典。
- 返回:
- display
PredictionErrorDisplay 存储计算值的对象。
- display