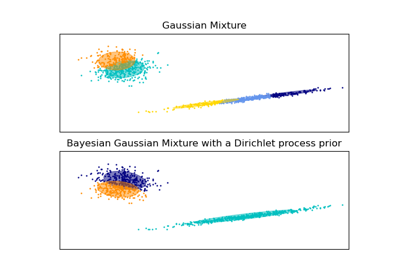
BayesianGaussianMixture#
- class sklearn.mixture.BayesianGaussianMixture(*, n_components=1, covariance_type='full', tol=0.001, reg_covar=1e-06, max_iter=100, n_init=1, init_params='kmeans', weight_concentration_prior_type='dirichlet_process', weight_concentration_prior=None, mean_precision_prior=None, mean_prior=None, degrees_of_freedom_prior=None, covariance_prior=None, random_state=None, warm_start=False, verbose=0, verbose_interval=10)[源]#
高斯混合的变分贝叶斯估计。
该类允许推断高斯混合模型参数的近似后验分布。有效组件的数量可以从数据中推断出来。
此类实现了两种类型的权重分布先验:具有狄利克雷分布的有限混合模型和具有狄利克雷过程的无限混合模型。实际上,狄利克雷过程推理算法是近似的,并使用具有固定最大组件数的截断分布(称为“粘性破碎”表示)。实际使用的组件数量几乎总是取决于数据。
版本 0.18 新增。
在用户指南中阅读更多内容。
- 参数:
- n_componentsint, default=1
混合组件的数量。根据数据和
weight_concentration_prior的值,模型可以决定不使用所有组件,方法是将某些组件的weights_设置为非常接近零的值。因此,有效组件的数量小于n_components。- covariance_type{‘full’, ‘tied’, ‘diag’, ‘spherical’}, default=’full’
描述要使用的协方差参数类型的字符串。必须是以下之一:
‘full’(每个组件都有自己的通用协方差矩阵),
‘tied’(所有组件共享相同的通用协方差矩阵),
‘diag’(每个组件都有自己的对角线协方差矩阵),
‘spherical’(每个组件都有自己的单一方差)。
- tolfloat, default=1e-3
收敛阈值。当模型对训练数据的似然(或下界)的平均增益低于此阈值时,EM迭代将停止。
- reg_covarfloat, default=1e-6
添加到协方差对角线的非负正则化。允许确保所有协方差矩阵都是正定的。
- max_iterint, default=100
要执行的EM迭代次数。
- n_initint, default=1
要执行的初始化次数。将保留似然度下界值最高的那个结果。
- init_params{‘kmeans’, ‘k-means++’, ‘random’, ‘random_from_data’}, default=’kmeans’
用于初始化权重、均值和协方差的方法。字符串必须是以下之一:
‘kmeans’:使用kmeans初始化响应。
‘k-means++’:使用k-means++方法进行初始化。
‘random’:随机初始化响应。
‘random_from_data’:初始均值是随机选择的数据点。
版本v1.1更改:
init_params现在接受‘random_from_data’和‘k-means++’作为初始化方法。- weight_concentration_prior_type{‘dirichlet_process’, ‘dirichlet_distribution’}, default=’dirichlet_process’
描述权重浓度先验类型的字符串。
- weight_concentration_priorfloat or None, default=None
权重分布(狄利克雷)中每个分量的狄利克雷浓度。这在文献中通常称为gamma。较高的浓度将更多的质量集中在中心,并会导致更多的组件处于活跃状态,而较低的浓度参数将导致更多的质量位于混合权重单纯形的边缘。参数值必须大于0。如果为None,则设置为
1. / n_components。- mean_precision_priorfloat or None, default=None
均值分布(高斯)的精度先验。控制均值可以放置的范围。较大的值将簇均值集中在
mean_prior附近。参数值必须大于0。如果为None,则设置为1。- mean_priorarray-like, shape (n_features,), default=None
均值分布(高斯)的先验。如果为None,则设置为X的均值。
- degrees_of_freedom_priorfloat or None, default=None
协方差分布(Wishart)的自由度先验。如果为None,则设置为
n_features。- covariance_priorfloat or array-like, default=None
协方差分布(Wishart)的先验。如果为None,则使用X的协方差初始化经验协方差先验。形状取决于
covariance_type。(n_features, n_features) if 'full', (n_features, n_features) if 'tied', (n_features) if 'diag', float if 'spherical'
- random_stateint, RandomState instance or None, default=None
控制用于初始化参数的方法(参见
init_params)的随机种子。此外,它还控制从拟合分布中生成随机样本(参见sample方法)。传递一个整数以获得跨多个函数调用的可重复输出。参见术语表。- warm_startbool, default=False
如果‘warm_start’为True,则最后一个拟合结果用作下一次fit()调用的初始化。这可以加快fit()多次应用于相似问题的收敛速度。参见术语表。
- verboseint, default=0
启用详细输出。如果为1,则打印当前初始化和每次迭代步骤。如果大于1,则还会打印每一步的对数概率和所需时间。
- verbose_intervalint, default=10
在下次打印之前完成的迭代次数。
- 属性:
- weights_array-like of shape (n_components,)
每个混合分量的权重。
- means_array-like of shape (n_components, n_features)
每个混合分量的均值。
- covariances_array-like
每个混合分量的协方差。形状取决于
covariance_type。(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- precisions_array-like
混合中每个分量的精度矩阵。精度矩阵是协方差矩阵的逆。协方差矩阵是对称正定的,因此高斯混合模型可以通过精度矩阵等效地参数化。存储精度矩阵而不是协方差矩阵可以更有效地计算测试时新样本的对数似然。形状取决于
covariance_type。(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- precisions_cholesky_array-like
混合分量精度矩阵的Cholesky分解。精度矩阵是协方差矩阵的逆。协方差矩阵是对称正定的,因此高斯混合模型可以通过精度矩阵等效地参数化。存储精度矩阵而不是协方差矩阵可以更有效地计算测试时新样本的对数似然。形状取决于
covariance_type。(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- converged_bool
True表示已达到推理的最佳拟合收敛,否则为False。
- n_iter_int
推理的最佳拟合达到收敛所使用的步数。
- lower_bound_float
推理的最佳拟合的模型证据(训练数据)的下界值。
- lower_bounds_array-like of shape (
n_iter_,) 推理的最佳拟合的每次迭代的模型证据下界值列表。
- weight_concentration_prior_tuple or float
权重分布(狄利克雷)中每个分量的狄利克雷浓度。类型取决于
weight_concentration_prior_type。(float, float) if 'dirichlet_process' (Beta parameters), float if 'dirichlet_distribution' (Dirichlet parameters).
较高的浓度将更多的质量集中在中心,并会导致更多的组件处于活跃状态,而较低的浓度参数将导致更多的质量位于单纯形的边缘。
- weight_concentration_array-like of shape (n_components,)
权重分布(狄利克雷)中每个分量的狄利克雷浓度。
- mean_precision_prior_float
均值分布(高斯)的精度先验。控制均值可以放置的范围。较大的值将簇均值集中在
mean_prior附近。如果mean_precision_prior设置为None,则mean_precision_prior_设置为1。- mean_precision_array-like of shape (n_components,)
均值分布(高斯)中每个分量的精度。
- mean_prior_array-like of shape (n_features,)
均值分布(高斯)的先验。
- degrees_of_freedom_prior_float
协方差分布(Wishart)的自由度先验。
- degrees_of_freedom_array-like of shape (n_components,)
模型中每个分量的自由度。
- covariance_prior_float or array-like
协方差分布(Wishart)的先验。形状取决于
covariance_type。(n_features, n_features) if 'full', (n_features, n_features) if 'tied', (n_features) if 'diag', float if 'spherical'
- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
另请参阅
GaussianMixture使用EM进行有限高斯混合拟合。
References
示例
>>> import numpy as np >>> from sklearn.mixture import BayesianGaussianMixture >>> X = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [12, 4], [10, 7]]) >>> bgm = BayesianGaussianMixture(n_components=2, random_state=42).fit(X) >>> bgm.means_ array([[2.49 , 2.29], [8.45, 4.52 ]]) >>> bgm.predict([[0, 0], [9, 3]]) array([0, 1])
- fit(X, y=None)[源]#
使用EM算法估计模型参数。
该方法执行
n_init次模型拟合,并选择具有最大似然度或下界值的参数。在每次尝试中,方法会在E步和M步之间迭代max_iter次,直到似然度或下界的变化小于tol,否则将引发ConvergenceWarning。如果warm_start为True,则n_init将被忽略,并且在第一次调用时执行一次初始化。在连续调用时,训练将从上次中断的地方开始。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
n_features维数据点列表。每行对应一个数据点。
- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- 返回:
- selfobject
拟合后的混合模型。
- fit_predict(X, y=None)[源]#
使用X估计模型参数并预测X的标签。
该方法执行
n_init次模型拟合,并选择具有最大似然度或下界值的参数。在每次尝试中,方法会在E步和M步之间迭代max_iter次,直到似然度或下界的变化小于tol,否则将引发ConvergenceWarning。拟合后,它将预测输入数据点的最可能标签。0.20 版本新增。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
n_features维数据点列表。每行对应一个数据点。
- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- 返回:
- labelsarray, shape (n_samples,)
组件标签。
- get_metadata_routing()[源]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[源]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- predict(X)[源]#
使用训练好的模型预测X中的数据样本的标签。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
n_features维数据点列表。每行对应一个数据点。
- 返回:
- labelsarray, shape (n_samples,)
组件标签。
- predict_proba(X)[源]#
评估X中每个样本的组件密度。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
n_features维数据点列表。每行对应一个数据点。
- 返回:
- resparray, shape (n_samples, n_components)
X中每个样本的每个高斯分量的密度。
- sample(n_samples=1)[源]#
从拟合的高斯分布中生成随机样本。
- 参数:
- n_samplesint, default=1
要生成的样本数量。
- 返回:
- Xarray, shape (n_samples, n_features)
随机生成的样本。
- yarray, shape (nsamples,)
组件标签。
- score(X, y=None)[源]#
计算给定数据X的每样本平均对数似然。
- 参数:
- Xarray-like of shape (n_samples, n_dimensions)
n_features维数据点列表。每行对应一个数据点。
- y被忽略
未使用,按照惯例为保持 API 一致性而存在。
- 返回:
- log_likelihoodfloat
X在高斯混合模型下的对数似然。