FeatureAgglomeration#
- class sklearn.cluster.FeatureAgglomeration(n_clusters=2, *, metric='euclidean', memory=None, connectivity=None, compute_full_tree='auto', linkage='ward', pooling_func=<function mean>, distance_threshold=None, compute_distances=False)[source]#
特征凝聚。
递归地合并特征对的聚类。
有关
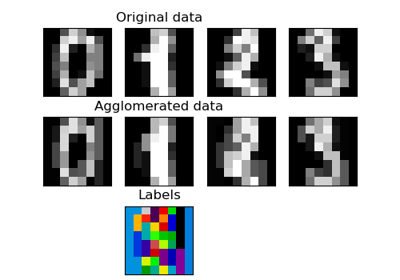
FeatureAgglomeration策略与单变量特征选择策略(基于 ANOVA)的比较示例,请参阅 Feature agglomeration vs. univariate selection。在 User Guide 中阅读更多内容。
- 参数:
- n_clustersint or None, default=2
要查找的聚类数量。如果
distance_threshold不是None,则必须为None。- metricstr or callable, default=”euclidean”
用于计算连接的度量。可以是 “euclidean”、“l1”、“l2”、“manhattan”、“cosine” 或 “precomputed”。如果连接是 “ward”,则只接受 “euclidean”。如果为 “precomputed”,则 fit 方法需要距离矩阵作为输入。
1.2 版本新增。
- memorystr 或具有 joblib.Memory 接口的对象, 默认为 None
用于缓存树计算的输出。默认情况下,不进行缓存。如果给定字符串,则为缓存目录的路径。
- connectivityarray-like, sparse matrix, or callable, default=None
连接矩阵。根据给定的数据结构定义每个特征的相邻特征。这本身可以是一个连接矩阵,也可以是一个将数据转换为连接矩阵的可调用对象,例如从
kneighbors_graph派生而来。默认值为None,即层次聚类算法是非结构化的。- compute_full_tree‘auto’ or bool, default=’auto’
在
n_clusters处提前停止构建树。如果聚类数量与特征数量相比不小,这有助于减少计算时间。此选项仅在指定连接矩阵时有用。另请注意,当改变聚类数量并使用缓存时,计算完整树可能更有利。如果distance_threshold不是None,则必须为True。默认情况下,compute_full_tree为 “auto”,当distance_threshold不是None或n_clusters小于 100 或0.02 * n_samples中的较大值时,等同于True。否则,“auto” 等同于False。- linkage{“ward”, “complete”, “average”, “single”}, default=”ward”
要使用的连接准则。连接准则决定了用于计算特征集之间距离的方法。算法将合并使此准则最小化的聚类对。
“ward” 最小化合并聚类的方差。
“complete” 或最大连接使用两个集合中所有特征之间的最大距离。
“average” 使用两个集合中每个特征之间距离的平均值。
“single” 使用两个集合中所有特征之间距离的最小值。
- pooling_funccallable, default=np.mean
这将合并的特征值组合成一个单一值,应该接受形状为 [M, N] 的数组和关键字参数
axis=1,并将其归约为大小为 [M] 的数组。- distance_thresholdfloat, default=None
链接距离阈值,当聚类之间的距离达到或超过此阈值时将不再合并。如果不是
None,则n_clusters必须为None且compute_full_tree必须为True。0.21 版本新增。
- compute_distancesbool, default=False
即使未使用
distance_threshold,也会计算聚类之间的距离。这可用于树状图可视化,但会引入计算和内存开销。0.24 版本新增。
- 属性:
- n_clusters_int
算法找到的聚类数量。如果
distance_threshold=None,它将等于给定的n_clusters。- labels_array-like of (n_features,)
每个特征的聚类标签。
- n_leaves_int
层次树中的叶子数量。
- n_connected_components_int
图中连通分量的估计数量。
版本 0.21 中新增:
n_connected_components_已添加以替换n_components_。- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
- children_array-like of shape (n_nodes-1, 2)
每个非叶节点的子节点。小于
n_features的值对应于作为原始样本的树叶节点。大于或等于n_features的节点i是一个非叶节点,其子节点为children_[i - n_features]。或者,在第 i 次迭代中,children[i][0]和children[i][1]合并形成节点n_features + i。- distances_array-like of shape (n_nodes-1,)
对应于
children_中位置的节点之间的距离。仅在使用了distance_threshold或将compute_distances设置为True时计算。
另请参阅
AgglomerativeClustering对样本而不是特征进行凝聚聚类。
ward_tree使用 ward 连接的层次聚类。
示例
>>> import numpy as np >>> from sklearn import datasets, cluster >>> digits = datasets.load_digits() >>> images = digits.images >>> X = np.reshape(images, (len(images), -1)) >>> agglo = cluster.FeatureAgglomeration(n_clusters=32) >>> agglo.fit(X) FeatureAgglomeration(n_clusters=32) >>> X_reduced = agglo.transform(X) >>> X_reduced.shape (1797, 32)
- fit(X, y=None)[source]#
对数据进行层次聚类拟合。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
数据。
- y被忽略
Not used, present here for API consistency by convention.
- 返回:
- selfobject
返回转换器。
- property fit_predict#
拟合并返回每个样本的聚类分配结果。
- fit_transform(X, y=None, **fit_params)[source]#
拟合数据,然后对其进行转换。
使用可选参数
fit_params将转换器拟合到X和y,并返回X的转换版本。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
输入样本。
- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组对象,默认=None
目标值(对于无监督转换,为 None)。
- **fit_paramsdict
额外的拟合参数。仅当估计器在其
fit方法中接受额外的参数时才传递。
- 返回:
- X_newndarray array of shape (n_samples, n_features_new)
转换后的数组。
- get_feature_names_out(input_features=None)[source]#
获取转换的输出特征名称。
The feature names out will prefixed by the lowercased class name. For example, if the transformer outputs 3 features, then the feature names out are:
["class_name0", "class_name1", "class_name2"].- 参数:
- input_featuresarray-like of str or None, default=None
Only used to validate feature names with the names seen in
fit.
- 返回:
- feature_names_outstr 对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- inverse_transform(X)[source]#
反转转换并返回大小为
n_features的向量。- 参数:
- Xarray-like of shape (n_samples, n_clusters) or (n_clusters,)
要分配给每个样本聚类的值。
- 返回:
- X_originalndarray of shape (n_samples, n_features) or (n_features,)
大小为
n_samples的向量,其中包含分配给每个样本聚类的X值。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用 API 的示例,请参阅引入 set_output API。
- 参数:
- transform{“default”, “pandas”, “polars”}, default=None
配置
transform和fit_transform的输出。"default": 转换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 转换配置保持不变
1.4 版本新增: 添加了
"polars"选项。
- 返回:
- selfestimator instance
估计器实例。