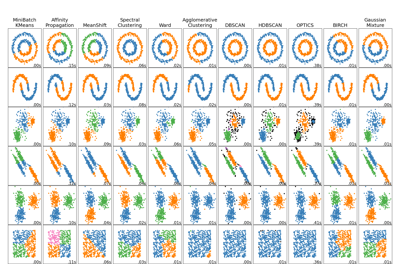
HDBSCAN#
- class sklearn.cluster.HDBSCAN(min_cluster_size=5, min_samples=None, cluster_selection_epsilon=0.0, max_cluster_size=None, metric='euclidean', metric_params=None, alpha=1.0, algorithm='auto', leaf_size=40, n_jobs=None, cluster_selection_method='eom', allow_single_cluster=False, store_centers=None, copy='warn')[source]#
使用分层基于密度的聚类对数据进行聚类。
HDBSCAN - Hierarchical Density-Based Spatial Clustering of Applications with Noise (基于分层密度的带噪声空间应用聚类). Performs
DBSCANover varying epsilon values and integrates the result to find a clustering that gives the best stability over epsilon. This allows HDBSCAN to find clusters of varying densities (unlikeDBSCAN), and be more robust to parameter selection. Read more in the User Guide.在版本 1.3 中新增。
- 参数:
- min_cluster_sizeint, default=5
对于一个组,成为一个簇的最小样本数;小于此大小的组将被视为噪声。
- min_samplesint, default=None
参数
k用于计算点x_p与其第 k 个最近邻居之间的距离。当为None时,默认为min_cluster_size。- cluster_selection_epsilonfloat, default=0.0
距离阈值。小于此值的簇将被合并。有关更多信息,请参阅 [5]。
- max_cluster_sizeint, default=None
"eom"簇选择算法返回的簇大小限制。当max_cluster_size=None时没有限制。如果cluster_selection_method="leaf",则无效。- metricstr or callable, default=’euclidean’
用于计算特征数组中实例之间距离的度量标准。
如果 metric 是字符串或可调用对象,它必须是
pairwise_distances允许作为其 metric 参数的选项之一。如果 metric 是 "precomputed",则假定 X 是距离矩阵且必须为方阵。
- metric_paramsdict, default=None
传递给距离度量标准的参数。
- alphafloat, default=1.0
在稳健单链接(robust single linkage)中使用的距离缩放参数。有关更多信息,请参阅 [3]。
- algorithm{“auto”, “brute”, “kd_tree”, “ball_tree”}, default=”auto”
用于计算核心距离的具体算法;默认设置为
"auto",它会尝试使用KDTree树(如果可能),否则使用BallTree树。"kd_tree"和"ball_tree"算法都使用NearestNeighbors估计器。如果在
fit期间传入的X是稀疏的,或者metric对KDTree和BallTree都无效,则它会回退使用"brute"算法。- leaf_sizeint, default=40
当 KDTree 或 BallTree 用作核心距离算法时,用于快速最近邻查询的树的叶子大小。大型数据集和小的
leaf_size可能会导致过度的内存使用。如果内存不足,请考虑增加leaf_size参数。对于algorithm="brute"无效。- n_jobsint, default=None
并行计算距离的作业数。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。有关更多详细信息,请参阅 Glossary。- cluster_selection_method{“eom”, “leaf”}, default=”eom”
用于从压缩树中选择簇的方法。HDBSCAN* 的标准方法是使用 Excess of Mass (
"eom") 算法来寻找最持久的簇。或者,您可以选择树叶处的簇——这提供了最细粒度和同质的簇。- allow_single_clusterbool, default=False
默认情况下,HDBSCAN* 不会产生单个簇,将其设置为 True 将覆盖此设置,并允许单个簇结果,以防您认为这对于您的数据集是有效的结果。
- store_centersstr, default=None
计算和存储哪些簇中心(如果有)。选项包括:
None:不计算也不存储任何中心。"centroid":通过取其位置的加权平均值来计算中心。请注意,该算法使用欧几里得度量,不保证输出将是一个观测到的数据点。"medoid":通过取拟合数据中最小化与簇中所有其他点距离的点来计算中心。这比 "centroid" 慢,因为它需要计算同一簇中点之间的额外成对距离,但保证输出是观测到的数据点。medoid 对于任意度量也定义良好,并且不依赖于欧几里得度量。"both":计算并存储两种形式的中心。
- copybool, default=False
如果
copy=True,那么任何时候将要进行的就地修改会覆盖传递给 fit 的数据时,将首先制作一个副本,确保原始数据保持不变。目前,它仅在metric="precomputed"、传递密集数组或 CSR 稀疏矩阵以及algorithm="brute"时适用。Changed in version 1.10:
copy的默认值将在版本 1.10 中从False更改为True。
- 属性:
- labels_ndarray of shape (n_samples,)
传递给 fit 的数据集中每个点的簇标签。离群值标签如下:
噪声样本被赋予标签 -1。
具有无限元素(+/- np.inf)的样本被赋予标签 -2。
具有缺失数据的样本被赋予标签 -3,即使它们也具有无限元素。
- probabilities_ndarray of shape (n_samples,)
每个样本是其分配簇的成员的强度。
聚类样本的概率与其作为簇的一部分的持久程度成正比。
噪声样本的概率为零。
具有无限元素(+/- np.inf)的样本概率为 0。
具有缺失数据的样本概率为
np.nan。
- n_features_in_int
在 拟合 期间看到的特征数。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。- centroids_ndarray of shape (n_clusters, n_features)
一个集合,包含在标准欧几里得度量下计算的每个簇的质心。如果簇本身是非凸的,质心可能落在其各自簇的“外部”。
请注意,
n_clusters只计算非离群值簇。也就是说,离群值簇的-1, -2, -3标签被排除。- medoids_ndarray of shape (n_clusters, n_features)
一个集合,包含在传递给
metric参数的度量下计算的每个簇的中心点(medoid)。中心点是原始簇中最小化到该簇中所有其他点的平均距离的点,使用所选的度量。可以将其视为将基于metric的质心投影回簇的结果。请注意,
n_clusters只计算非离群值簇。也就是说,离群值簇的-1, -2, -3标签被排除。
另请参阅
注意事项
这里的
min_samples参数包括点本身,而 scikit-learn-contrib/hdbscan 中的实现不包括。要在两个版本中获得相同的结果,这里的min_samples值必须比 scikit-learn-contrib/hdbscan 中使用的值大 1。References
示例
>>> import numpy as np >>> from sklearn.cluster import HDBSCAN >>> from sklearn.datasets import load_digits >>> X, _ = load_digits(return_X_y=True) >>> hdb = HDBSCAN(copy=True, min_cluster_size=20) >>> hdb.fit(X) HDBSCAN(copy=True, min_cluster_size=20) >>> hdb.labels_.shape == (X.shape[0],) True >>> np.unique(hdb.labels_).tolist() [-1, 0, 1, 2, 3, 4, 5, 6, 7]
- dbscan_clustering(cut_distance, min_cluster_size=5)[source]#
返回由不带边界点的 DBSCAN 给出的聚类。
返回与针对特定 cut_distance(或 epsilon)运行 DBSCAN* 等效的聚类。DBSCAN* 可以被认为是去掉了边界点的 DBSCAN。因此,这些结果可能与
cluster.DBSCAN略有不同,因为在非核心点上的实现存在差异。这也可以被认为是源自通过单链接树进行恒定高度切割的平面聚类。
这表示为稳健单链接聚类选择切割值的结果。
min_cluster_size允许平面聚类声明噪声点(以及小于min_cluster_size的簇)。- 参数:
- cut_distancefloat
用于生成平面聚类的互可达性距离切割值。
- min_cluster_sizeint, default=5
小于此值的簇将被标记为“噪声”,并保持在结果平面聚类中未聚类。
- 返回:
- labelsndarray of shape (n_samples,)
一个簇标签数组,每个数据点一个。离群值标签如下:
噪声样本被赋予标签 -1。
具有无限元素(+/- np.inf)的样本被赋予标签 -2。
具有缺失数据的样本被赋予标签 -3,即使它们也具有无限元素。
- fit(X, y=None)[source]#
基于分层密度聚类查找簇。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features), or ndarray of shape (n_samples, n_samples)
一个特征数组,如果
metric='precomputed',则为样本之间的距离数组。- yNone
忽略。
- 返回:
- selfobject
返回 self。
- fit_predict(X, y=None)[source]#
对 X 进行聚类并返回相关的簇标签。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features), or ndarray of shape (n_samples, n_samples)
一个特征数组,如果
metric='precomputed',则为样本之间的距离数组。- yNone
忽略。
- 返回:
- yndarray of shape (n_samples,)
聚类标签。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。