adjusted_mutual_info_score#
- sklearn.metrics.adjusted_mutual_info_score(labels_true, labels_pred, *, average_method='arithmetic')[源]#
两个聚类之间的调整互信息。
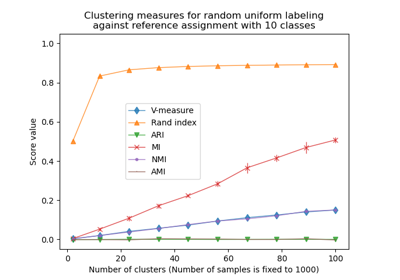
调整互信息 (AMI) 是互信息 (MI) 分数的一个调整,用于考虑偶然性。它考虑了这样的事实:对于具有更多簇的两个聚类,MI 通常更高,无论实际上共享的信息是否更多。对于两个聚类 \(U\) 和 \(V\),AMI 表示为
AMI(U, V) = [MI(U, V) - E(MI(U, V))] / [avg(H(U), H(V)) - E(MI(U, V))]
此度量独立于标签的绝对值:类或簇标签值的排列不会以任何方式改变分数。
此度量标准还是对称的:将 \(U\) (
label_true) 与 \(V\) (labels_pred) 互换将返回相同的分数。当不知道真实基本事实时,这对于测量同一数据集上两种独立标签分配策略的一致性很有用。请注意,此函数比其他度量标准(例如调整兰德指数)慢一个数量级。
在 用户指南 中阅读更多内容。
- 参数:
- labels_trueint 数组,形状 (n_samples,)
将数据聚类成不相交子集,在上述公式中称为 \(U\)。
- labels_predint 数组,形状 (n_samples,)
将数据聚类成不相交子集,在上述公式中称为 \(V\)。
- average_method{'min', 'geometric', 'arithmetic', 'max'},默认='arithmetic'
如何在分母中计算归一化器。
0.20 版本新增。
0.22 版本中已更改:
average_method的默认值从 'max' 更改为 'arithmetic'。
- 返回:
- ami: 浮点数 (上限为 1.0)
当两个分区完全相同时 (即完美匹配),AMI 返回值为 1。随机分区 (独立标记) 的 AMI 平均值约为 0,因此可能为负。该值以调整后的纳特 (基于自然对数) 为单位。
另请参阅
adjusted_rand_score调整兰德指数。
mutual_info_score互信息 (未根据偶然性进行调整)。
References
示例
完美的标签既是同质的又是完整的,因此分数为 1.0
>>> from sklearn.metrics.cluster import adjusted_mutual_info_score >>> adjusted_mutual_info_score([0, 0, 1, 1], [0, 0, 1, 1]) 1.0 >>> adjusted_mutual_info_score([0, 0, 1, 1], [1, 1, 0, 0]) 1.0
如果类成员完全分散在不同的簇中,则分配完全不完整,因此 AMI 为空
>>> adjusted_mutual_info_score([0, 0, 0, 0], [0, 1, 2, 3]) 0.0