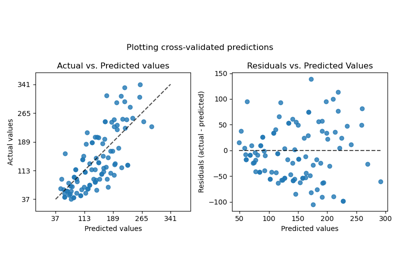
cross_val_predict#
- sklearn.model_selection.cross_val_predict(estimator, X, y=None, *, groups=None, cv=None, n_jobs=None, verbose=0, params=None, pre_dispatch='2*n_jobs', method='predict')[源代码]#
为每个输入数据点生成交叉验证估计。
数据根据 cv 参数进行拆分。每个样本都恰好属于一个测试集,并且其预测是使用在相应训练集上拟合的估计器计算得出的。
将这些预测结果传递给评估指标可能不是衡量泛化性能的有效方法。除非所有测试集大小相等且指标可分解为样本,否则结果可能与
cross_validate和cross_val_score不同。Read more in the User Guide.
- 参数:
- estimatorestimator
用于拟合数据的估计器实例。它必须实现
fit方法以及由method参数指定的方法。- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
要拟合的数据。例如,可以是列表或至少 2d 的数组。
- y{array-like, sparse matrix} of shape (n_samples,) or (n_samples, n_outputs), default=None
在监督学习中尝试预测的目标变量。
- groups形状为 (n_samples,) 的类数组对象,默认=None
在将数据集拆分为训练/测试集时使用的样本组标签。仅与“Group”cv 实例(例如
GroupKFold)结合使用。版本 1.4 中更改: 只有在未通过
sklearn.set_config(enable_metadata_routing=True)启用元数据路由时,才能传递groups。当启用路由时,请通过params参数传递groups以及其他元数据。例如:cross_val_predict(..., params={'groups': groups})。- cvint, cross-validation generator or an iterable, default=None
确定交叉验证拆分策略。cv 的可能输入包括
None,使用默认的 5 折交叉验证,
int,指定
(Stratified)KFold中的折叠数,生成 (train, test) 拆分作为索引数组的可迭代对象。
对于 int/None 输入,如果估计器是分类器且
y是二元或多类别,则使用StratifiedKFold。在所有其他情况下,使用KFold。这些分割器以shuffle=False实例化,因此分割在不同调用中将相同。有关此处可使用的各种交叉验证策略,请参阅 用户指南。
版本 0.22 中已更改:如果为 None,
cv默认值从 3 折更改为 5 折。- n_jobsint, default=None
并行运行的作业数。估计器的训练和预测在交叉验证拆分上并行进行。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。有关详细信息,请参阅 词汇表。- verboseint, default=0
详细程度。
- paramsdict, 默认=None
要传递给底层估计器的
fit方法和 CV 分割器的参数。1.4 版本新增。
- pre_dispatchint or str, default=’2*n_jobs’
控制并行执行期间调度的作业数量。当调度的作业多于 CPU 可处理的数量时,减少此数字有助于避免内存消耗激增。此参数可以为
None,在这种情况下,所有作业会立即创建和生成。对于轻量级且运行快速的作业使用此选项,以避免因按需生成作业而导致的延迟。
一个 int 值,给出生成的总作业的确切数量。
一个 str,给出 n_jobs 函数的表达式,例如 ‘2*n_jobs’。
- method{‘predict’, ‘predict_proba’, ‘predict_log_proba’, ‘decision_function’}, default=’predict’
要由
estimator调用的方法。
- 返回:
- predictionsndarray
这是调用
method的结果。形状当
method为 'predict' 且在特殊情况下method为 'decision_function' 且目标为二元时: (n_samples,)当
method为 {‘predict_proba’, ‘predict_log_proba’, ‘decision_function’} 之一时(除非上述特殊情况): (n_samples, n_classes)如果
estimator是 多输出,则在上述每种形状的末尾添加一个额外的维度 'n_outputs'。
另请参阅
cross_val_score计算每个 CV 拆分的得分。
cross_validate计算每个 CV 拆分的一个或多个得分和时间。
注意事项
如果在训练部分中缺少一个或多个类别,并且
method为每个类别生成列(如 {‘decision_function’, ‘predict_proba’, ‘predict_log_proba’} 中所示),则需要为该类别的所有实例分配一个默认得分。对于predict_proba,此值为 0。为了确保有限输出,在其他情况下,我们用 dtype 的最小有限浮点值近似负无穷大。示例
>>> from sklearn import datasets, linear_model >>> from sklearn.model_selection import cross_val_predict >>> diabetes = datasets.load_diabetes() >>> X = diabetes.data[:150] >>> y = diabetes.target[:150] >>> lasso = linear_model.Lasso() >>> y_pred = cross_val_predict(lasso, X, y, cv=3)
有关使用
cross_val_predict可视化预测错误的详细示例,请参阅 绘制交叉验证预测。