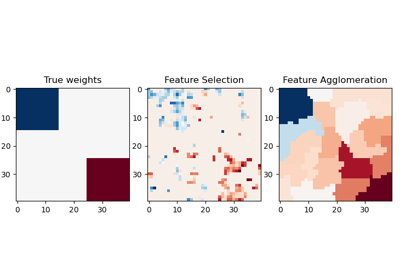
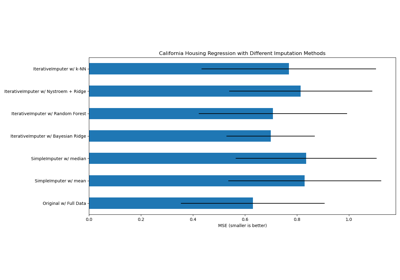
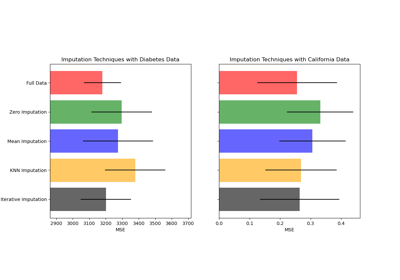
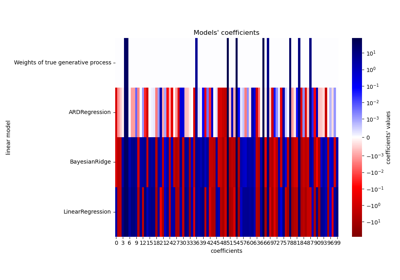
BayesianRidge#
- class sklearn.linear_model.BayesianRidge(*, max_iter=300, tol=0.001, alpha_1=1e-06, alpha_2=1e-06, lambda_1=1e-06, lambda_2=1e-06, alpha_init=None, lambda_init=None, compute_score=False, fit_intercept=True, copy_X=True, verbose=False)[source]#
贝叶斯岭回归。
拟合贝叶斯岭回归模型。有关此实现的详细信息以及正则化参数 lambda(权重精度)和 alpha(噪声精度)的优化,请参阅“注释”部分。
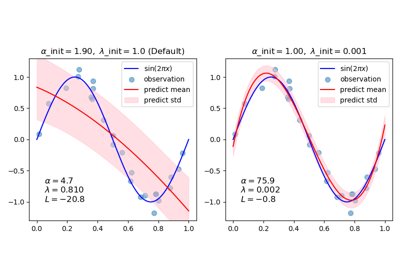
在用户指南中了解更多信息。有关使用不同初始值对来近似正弦曲线的直观可视化,请参阅使用贝叶斯岭回归进行曲线拟合。
- 参数:
- max_iterint, default=300
在独立于任何早期停止标准之前,对完整数据集的最大迭代次数。
版本 1.3 中的更改。
- tolfloat, default=1e-3
如果 w 收敛,则停止算法。
- alpha_1float, default=1e-6
超参数:alpha 参数上 Gamma 分布先验的形状参数。
- alpha_2float, default=1e-6
超参数:alpha 参数上 Gamma 分布先验的逆尺度参数(速率参数)。
- lambda_1float, default=1e-6
超参数:lambda 参数上 Gamma 分布先验的形状参数。
- lambda_2float, default=1e-6
超参数:lambda 参数上 Gamma 分布先验的逆尺度参数(速率参数)。
- alpha_initfloat, default=None
alpha(噪声精度)的初始值。如果未设置,则 alpha_init 为 1/Var(y)。
版本 0.22 新增。
- lambda_initfloat, default=None
lambda(权重精度)的初始值。如果未设置,则 lambda_init 为 1。
版本 0.22 新增。
- compute_scorebool, default=False
如果为 True,则在优化的每次迭代中计算对数边际似然。
- fit_interceptbool, default=True
是否为该模型计算截距。截距不被视为概率参数,因此没有相关的方差。如果设置为 False,则计算中不使用截距(即,数据应已中心化)。
- copy_Xbool, default=True
如果为 True,X 将被复制;否则,它可能会被覆盖。
- verbosebool, default=False
拟合模型时的详细模式。
- 属性:
- coef_array-like of shape (n_features,)
回归模型的系数(分布均值)
- intercept_float
决策函数中的独立项。如果
fit_intercept = False,则设置为0.0。- alpha_float
估计的噪声精度。
- lambda_float
估计的权重精度。
- sigma_array-like of shape (n_features, n_features)
估计的权重方差-协方差矩阵
- scores_array-like of shape (n_iter_+1,)
如果 computed_score 为 True,则优化的每次迭代中对数边际似然(要最大化)的值。数组以 alpha 和 lambda 初始值获得的对数边际似然值开始,并以 alpha 和 lambda 估计值获得的对数边际似然值结束。
- n_iter_int
The actual number of iterations to reach the stopping criterion.
- X_offset_ndarray of shape (n_features,)
如果
fit_intercept=True,则为用于将数据中心化为零均值而减去的偏移量。否则设置为 np.zeros(n_features)。- X_scale_ndarray of shape (n_features,)
设置为 np.ones(n_features)。
- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
另请参阅
ARDRegression贝叶斯 ARD 回归。
注意事项
有几种执行贝叶斯岭回归的策略。此实现基于 (Tipping, 2001) 附录 A 中描述的算法,其中正则化参数的更新是按照 (MacKay, 1992) 中建议的方式进行的。请注意,根据 A New View of Automatic Relevance Determination (Wipf and Nagarajan, 2008),这些更新规则不能保证在优化的两次连续迭代之间边际似然增加。
References
D. J. C. MacKay, Bayesian Interpolation, Computation and Neural Systems, Vol. 4, No. 3, 1992.
M. E. Tipping, Sparse Bayesian Learning and the Relevance Vector Machine, Journal of Machine Learning Research, Vol. 1, 2001.
示例
>>> from sklearn import linear_model >>> clf = linear_model.BayesianRidge() >>> clf.fit([[0,0], [1, 1], [2, 2]], [0, 1, 2]) BayesianRidge() >>> clf.predict([[1, 1]]) array([1.])
- fit(X, y, sample_weight=None)[source]#
拟合模型。
- 参数:
- Xndarray of shape (n_samples, n_features)
训练数据。
- yndarray of shape (n_samples,)
目标值。如有必要,将被转换为 X 的 dtype。
- sample_weightndarray of shape (n_samples,), default=None
每个样本的个体权重。
版本 0.20 中新增: 对 BayesianRidge 的参数 sample_weight 支持。
- 返回:
- selfobject
返回实例本身。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- predict(X, return_std=False)[source]#
使用线性模型进行预测。
除了预测分布的均值之外,还可以返回其标准差。
- 参数:
- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
样本。
- return_stdbool, default=False
是否返回后验预测的标准差。
- 返回:
- y_meanarray-like of shape (n_samples,)
查询点的预测分布均值。
- y_stdarray-like of shape (n_samples,)
查询点的预测分布的标准差。
- score(X, y, sample_weight=None)[source]#
返回测试数据的 决定系数。
决定系数 \(R^2\) 定义为 \((1 - \frac{u}{v})\),其中 \(u\) 是残差平方和
((y_true - y_pred)** 2).sum(),\(v\) 是总平方和((y_true - y_true.mean()) ** 2).sum()。最好的分数是 1.0,它也可以是负数(因为模型可能任意地差)。一个始终预测y期望值而忽略输入特征的常数模型将获得 0.0 的 \(R^2\) 分数。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
测试样本。对于某些估计器,这可能是一个预先计算的核矩阵或一个通用对象列表,形状为
(n_samples, n_samples_fitted),其中n_samples_fitted是用于估计器拟合的样本数。- yshape 为 (n_samples,) 或 (n_samples, n_outputs) 的 array-like
X的真实值。- sample_weightshape 为 (n_samples,) 的 array-like, default=None
样本权重。
- 返回:
- scorefloat
self.predict(X)相对于y的 \(R^2\)。
注意事项
在版本 0.23 中,对 regressor 调用
score时使用的 \(R^2\) 分数使用multioutput='uniform_average',以与r2_score的默认值保持一致。这会影响所有多输出回归器(除了MultiOutputRegressor)的score方法。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') BayesianRidge[source]#
配置是否应请求元数据以传递给
fit方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
fit方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单的估计器以及嵌套对象(如
Pipeline)。后者具有<component>__<parameter>形式的参数,以便可以更新嵌套对象的每个组件。- 参数:
- **paramsdict
估计器参数。
- 返回:
- selfestimator instance
估计器实例。
- set_predict_request(*, return_std: bool | None | str = '$UNCHANGED$') BayesianRidge[source]#
配置是否应请求元数据以传递给
predict方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给predict。如果未提供元数据,则忽略该请求。False:不请求元数据,并且元估计器不会将其传递给predict。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- return_stdstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
predict中return_std参数的元数据路由。
- 返回:
- selfobject
更新后的对象。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') BayesianRidge[source]#
配置是否应请求元数据以传递给
score方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给score。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给score。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
score方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。