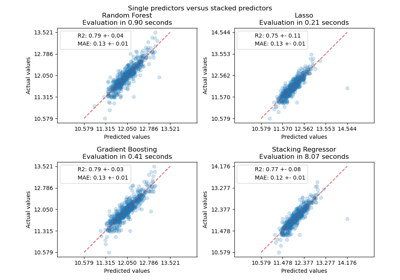
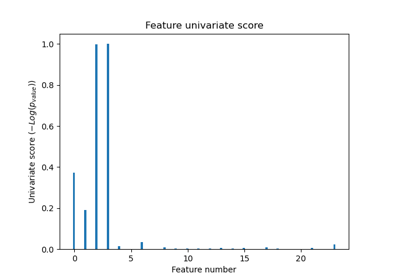
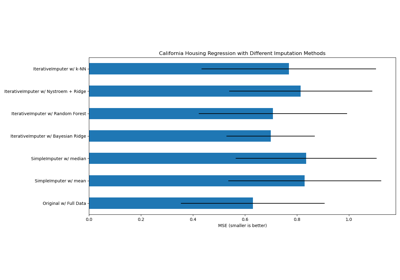
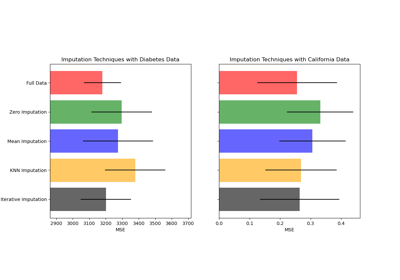
make_pipeline#
- sklearn.pipeline.make_pipeline(*steps, memory=None, transform_input=None, verbose=False)[源代码]#
从给定的估计器构建一个
Pipeline。这是
Pipeline构造函数的简写形式;它不需要,也不允许为估计器命名。相反,它们的名称将自动设置为其类型的全小写形式。- 参数:
- *stepsEstimator 对象列表
链接在一起的 scikit-learn 估计器列表。
- memorystr 或具有 joblib.Memory 接口的对象, 默认为 None
用于缓存管道的已拟合的转换器。最后一个步骤将永远不会被缓存,即使它是一个转换器。默认情况下,不执行任何缓存。如果给出字符串,则为缓存目录的路径。启用缓存会触发在拟合之前对转换器进行克隆。因此,不能直接检查传递给管道的转换器实例。使用属性
named_steps或steps来检查管道内的估计器。当拟合耗时时,缓存转换器是有益的。- transform_input字符串列表,默认=None
这使得一些传递给
fit的输入参数(除了X)可以通过管道中的步骤进行转换,直到需要它们的步骤。需求通过 元数据路由 定义。例如,这可以用于将验证集通过管道进行传递。只有当启用了元数据路由时,才能设置此项,您可以使用
sklearn.set_config(enable_metadata_routing=True)来启用它。版本 1.6 中新增。
- verbosebool, default=False
如果为 True,则在每个步骤完成拟合时,将打印出经过的时间。
- 返回:
- pPipeline
返回一个 scikit-learn
Pipeline对象。
另请参阅
Pipeline用于创建具有最终估计器的转换器管道的类。
示例
>>> from sklearn.naive_bayes import GaussianNB >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.pipeline import make_pipeline >>> make_pipeline(StandardScaler(), GaussianNB(priors=None)) Pipeline(steps=[('standardscaler', StandardScaler()), ('gaussiannb', GaussianNB())])