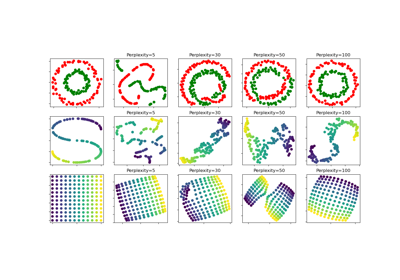
TSNE#
- class sklearn.manifold.TSNE(n_components=2, *, perplexity=30.0, early_exaggeration=12.0, learning_rate='auto', max_iter=1000, n_iter_without_progress=300, min_grad_norm=1e-07, metric='euclidean', metric_params=None, init='pca', verbose=0, random_state=None, method='barnes_hut', angle=0.5, n_jobs=None)[source]#
T 分布随机邻居嵌入。
t-SNE [1] 是一种用于可视化高维数据的工具。它将数据点之间的相似性转换为联合概率,并试图最小化低维嵌入的联合概率与高维数据的联合概率之间的 Kullback-Leibler 散度。t-SNE 具有非凸的成本函数,这意味着不同的初始化可能会得到不同的结果。
如果特征数量非常多,强烈建议使用另一种降维方法(例如,对于密集数据使用 PCA,对于稀疏数据使用 TruncatedSVD)将维度数量减少到合理的范围(例如 50)。这将抑制一些噪声并加快计算样本之间的成对距离。有关更多提示,请参阅 Laurens van der Maaten 的 FAQ [2]。
在用户指南中了解更多信息。
- 参数:
- n_componentsint, default=2
嵌入空间的维度。
- perplexityfloat, default=30.0
困惑度(perplexity)与在其他流形学习算法中使用的最近邻数量有关。较大的数据集通常需要较大的困惑度。考虑选择一个介于 5 和 50 之间的值。不同的值可能会导致截然不同的结果。困惑度必须小于样本数量。
- early_exaggerationfloat, default=12.0
控制原始空间中的自然聚类在嵌入空间中的紧密程度以及它们之间的距离。对于较大的值,嵌入空间中自然聚类之间的距离会更大。同样,此参数的选择不是非常关键。如果在初始优化过程中成本函数增加,则早期夸大因子或学习率可能过高。
- learning_ratefloat or “auto”, default=”auto”
t-SNE 的学习率通常在 [10.0, 1000.0] 范围内。如果学习率过高,数据可能看起来像一个“球”,其中任何点与其最近邻的距离近似相等。如果学习率过低,大多数点可能看起来被压缩在一个密集的云中,只有少数异常值。如果成本函数陷入不良的局部最小值,增加学习率可能会有所帮助。请注意,许多其他 t-SNE 实现(bhtsne、FIt-SNE、openTSNE 等)使用的 learning_rate 定义比我们的要小 4 倍。因此,我们的 learning_rate=200 对应于这些其他实现中的 learning_rate=800。 “auto”选项将 learning_rate 设置为
max(N / early_exaggeration / 4, 50),其中 N 是样本大小,遵循 [4] 和 [5]。版本 1.2 中的更改: 默认值更改为
"auto"。- max_iterint, default=1000
优化的最大迭代次数。应至少为 250。
版本 1.5 中的更改: 参数名称从
n_iter更改为max_iter。- n_iter_without_progressint, default=300
在中止优化之前,没有进展的最大迭代次数,在早期夸大后的 250 次初始迭代之后使用。请注意,进度仅每 50 次迭代检查一次,因此此值会向上取整到 50 的下一个倍数。
版本 0.17 中新增: 参数 n_iter_without_progress 用于控制停止标准。
- min_grad_normfloat, default=1e-7
如果梯度范数低于此阈值,优化将停止。
- metricstr or callable, default=’euclidean’
在计算特征数组中实例之间的距离时使用的度量。如果 metric 是字符串,它必须是 scipy.spatial.distance.pdist 的 metric 参数允许的选项之一,或者是 pairwise.PAIRWISE_DISTANCE_FUNCTIONS 中列出的度量之一。如果 metric 是 "precomputed",则假定 X 是距离矩阵。或者,如果 metric 是可调用函数,它将应用于每对实例(行),并记录结果值。可调用函数应将 X 中的两个数组作为输入,并返回表示它们之间距离的值。默认值为 "euclidean",解释为平方欧几里得距离。
- metric_paramsdict, default=None
度量函数的附加关键字参数。
版本 1.1 中新增。
- init{“random”, “pca”} or ndarray of shape (n_samples, n_components), default=”pca”
嵌入的初始化。PCA 初始化不能用于预计算距离,并且通常比随机初始化更全局稳定。
版本 1.2 中的更改: 默认值更改为
"pca"。- verboseint, default=0
详细程度。
- random_stateint, RandomState instance or None, default=None
确定随机数生成器。传递一个整数可在多次函数调用中获得可重现的结果。请注意,不同的初始化可能会导致成本函数的不同局部最小值。请参阅词汇表。
- method{‘barnes_hut’, ‘exact’}, default=’barnes_hut’
默认情况下,梯度计算算法使用 Barnes-Hut 近似方法,运行时间为 O(NlogN)。method='exact' 将运行较慢但精确的算法,运行时间为 O(N^2)。当最近邻误差需要优于 3% 时,应使用精确算法。然而,精确方法不能扩展到数百万个示例。
版本 0.17 中新增: 通过 Barnes-Hut 进行近似优化 method。
- anglefloat, default=0.5
仅当 method='barnes_hut' 时使用。这是 Barnes-Hut T-SNE 的速度和准确性之间的权衡。“angle”是一个从某一点测量的遥远节点的角大小(在 [3] 中称为 theta)。如果此大小低于“angle”,则将其用作其中包含的所有点的摘要节点。此方法在 0.2 - 0.8 范围内对此参数的变化不是很敏感。小于 0.2 的 angle 会迅速增加计算时间,大于 0.8 的 angle 会迅速增加误差。
- n_jobsint, default=None
用于邻居搜索的并行作业数。当
metric="precomputed"或 (metric="euclidean"且method="exact") 时,此参数无效。None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。有关详细信息,请参阅词汇表。版本 0.22 新增。
- 属性:
- embedding_array-like of shape (n_samples, n_components)
存储嵌入向量。
- kl_divergence_float
优化后的 Kullback-Leibler 散度。
- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
- learning_rate_float
有效的学习率。
1.2 版本新增。
- n_iter_int
运行的迭代次数。
另请参阅
sklearn.decomposition.PCA主成分分析,是一种线性降维方法。
sklearn.decomposition.KernelPCA使用核函数和PCA的非线性降维。
MDS使用多维尺度变换的流形学习。
Isomap基于等距映射(Isometric Mapping)的流形学习。
LocallyLinearEmbedding使用局部线性嵌入的流形学习。
SpectralEmbedding用于非线性降维的谱嵌入。
注意事项
有关结合使用
TSNE和KNeighborsTransformer的示例,请参阅 TSNE 中的近似最近邻。References
- [1] van der Maaten, L.J.P.; Hinton, G.E. Visualizing High-Dimensional Data
Using t-SNE. Journal of Machine Learning Research 9:2579-2605, 2008.
- [2] van der Maaten, L.J.P. t-Distributed Stochastic Neighbor Embedding
- [3] L.J.P. van der Maaten. Accelerating t-SNE using Tree-Based Algorithms.
Journal of Machine Learning Research 15(Oct):3221-3245, 2014. https://lvdmaaten.github.io/publications/papers/JMLR_2014.pdf
- [4] Belkina, A. C., Ciccolella, C. O., Anno, R., Halpert, R., Spidlen, J.,
& Snyder-Cappione, J. E. (2019). Automated optimized parameters for T-distributed stochastic neighbor embedding improve visualization and analysis of large datasets. Nature Communications, 10(1), 1-12.
- [5] Kobak, D., & Berens, P. (2019). The art of using t-SNE for single-cell
transcriptomics. Nature Communications, 10(1), 1-14.
示例
>>> import numpy as np >>> from sklearn.manifold import TSNE >>> X = np.array([[0, 0, 0], [0, 1, 1], [1, 0, 1], [1, 1, 1]]) >>> X_embedded = TSNE(n_components=2, learning_rate='auto', ... init='random', perplexity=3).fit_transform(X) >>> X_embedded.shape (4, 2)
- fit(X, y=None)[source]#
将 X 拟合到嵌入空间。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features) or (n_samples, n_samples)
如果 metric 是 'precomputed',X 必须是一个方阵距离矩阵。否则,它包含每行一个样本。如果 method 是 'exact',X 可以是类型为 'csr'、'csc' 或 'coo' 的稀疏矩阵。如果 method 是 'barnes_hut' 且 metric 是 'precomputed',X 可以是预计算的稀疏图。
- yNone
忽略。
- 返回:
- selfobject
拟合的估计器。
- fit_transform(X, y=None)[source]#
将 X 拟合到嵌入空间并返回转换后的输出。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features) or (n_samples, n_samples)
如果 metric 是 'precomputed',X 必须是一个方阵距离矩阵。否则,它包含每行一个样本。如果 method 是 'exact',X 可以是类型为 'csr'、'csc' 或 'coo' 的稀疏矩阵。如果 method 是 'barnes_hut' 且 metric 是 'precomputed',X 可以是预计算的稀疏图。
- yNone
忽略。
- 返回:
- X_newndarray of shape (n_samples, n_components)
训练数据在低维空间中的嵌入。
- get_feature_names_out(input_features=None)[source]#
获取转换的输出特征名称。
The feature names out will prefixed by the lowercased class name. For example, if the transformer outputs 3 features, then the feature names out are:
["class_name0", "class_name1", "class_name2"].- 参数:
- input_featuresarray-like of str or None, default=None
Only used to validate feature names with the names seen in
fit.
- 返回:
- feature_names_outstr 对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用 API 的示例,请参阅引入 set_output API。
- 参数:
- transform{“default”, “pandas”, “polars”}, default=None
配置
transform和fit_transform的输出。"default": 转换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 转换配置保持不变
1.4 版本新增: 添加了
"polars"选项。
- 返回:
- selfestimator instance
估计器实例。