NeighborhoodComponentsAnalysis#
- class sklearn.neighbors.NeighborhoodComponentsAnalysis(n_components=None, *, init='auto', warm_start=False, max_iter=50, tol=1e-05, callback=None, verbose=0, random_state=None)[source]#
邻域成分分析。
邻域成分分析(Neighborhood Component Analysis,NCA)是一种用于度量学习的机器学习算法。它以有监督的方式学习一个线性变换,以提高变换空间中随机最近邻规则的分类精度。
在用户指南中阅读更多内容。
- 参数:
- n_componentsint, default=None
投影空间的首选维度。如果为 None,则将设置为
n_features。- init{‘auto’, ‘pca’, ‘lda’, ‘identity’, ‘random’} or ndarray of shape (n_features_a, n_features_b), default=’auto’
线性变换的初始化。可能的选项包括
'auto'、'pca'、'lda'、'identity'、'random',以及形状为(n_features_a, n_features_b)的 numpy 数组。'auto'根据
n_components的值,选择最合理的初始化方式。如果n_components <= min(n_features, n_classes - 1),我们使用'lda',因为它使用了标签信息。如果不是这种情况,但n_components < min(n_features, n_samples),我们使用'pca',因为它将数据投影到有意义的方向(方差较高的方向)。否则,我们只使用'identity'。
'lda'传递给
fit的输入中最具判别性的min(n_components, n_classes)个成分将用于初始化变换。(如果n_components > n_classes,其余成分将为零。)(请参阅LinearDiscriminantAnalysis)
'identity'如果
n_components严格小于传递给fit的输入的维度,则单位矩阵将被截断为前n_components行。
'random'初始变换将是一个形状为
(n_components, n_features)的随机数组。每个值从标准正态分布中采样。
- numpy array
n_features_b必须与传递给fit的输入的维度匹配,且 n_features_a 必须小于或等于该维度。如果n_components不是None,则n_features_a必须与它匹配。
- warm_startbool, default=False
如果为
True且之前调用过fit,则上次调用fit的解决方案将用作初始线性变换(n_components和init将被忽略)。- max_iterint, default=50
优化中的最大迭代次数。
- tolfloat, default=1e-5
优化的收敛容差。
- callbackcallable, default=None
如果不是
None,此函数将在优化器每次迭代后调用,参数为当前解决方案(扁平化的变换矩阵)和迭代次数。如果需要检查或存储每次迭代后找到的变换,这可能很有用。- verboseint, default=0
如果为 0,则不打印进度消息。如果为 1,则将进度消息打印到标准输出。如果 > 1,将打印进度消息,并且
scipy.optimize.minimize的disp参数将设置为verbose - 2。- random_stateint or numpy.RandomState, default=None
伪随机数生成器对象或其种子(如果为 int)。如果
init='random',random_state用于初始化随机变换。如果init='pca',random_state作为参数传递给 PCA 以初始化变换。传入 int 可在多次函数调用中实现可重现的结果。请参阅 Glossary。
- 属性:
另请参阅
References
[1]J. Goldberger, G. Hinton, S. Roweis, R. Salakhutdinov. “Neighbourhood Components Analysis”. Advances in Neural Information Processing Systems. 17, 513-520, 2005. https://www.cs.toronto.edu/~rsalakhu/papers/ncanips.pdf
[2]Wikipedia entry on Neighborhood Components Analysis https://en.wikipedia.org/wiki/Neighbourhood_components_analysis
示例
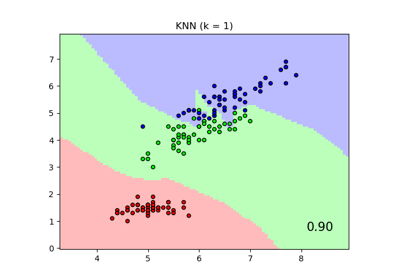
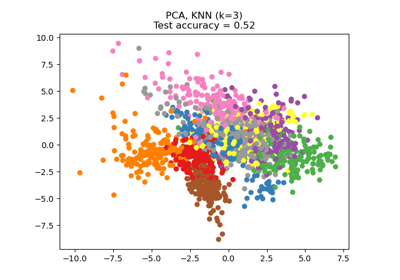
>>> from sklearn.neighbors import NeighborhoodComponentsAnalysis >>> from sklearn.neighbors import KNeighborsClassifier >>> from sklearn.datasets import load_iris >>> from sklearn.model_selection import train_test_split >>> X, y = load_iris(return_X_y=True) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, ... stratify=y, test_size=0.7, random_state=42) >>> nca = NeighborhoodComponentsAnalysis(random_state=42) >>> nca.fit(X_train, y_train) NeighborhoodComponentsAnalysis(...) >>> knn = KNeighborsClassifier(n_neighbors=3) >>> knn.fit(X_train, y_train) KNeighborsClassifier(...) >>> print(knn.score(X_test, y_test)) 0.933333... >>> knn.fit(nca.transform(X_train), y_train) KNeighborsClassifier(...) >>> print(knn.score(nca.transform(X_test), y_test)) 0.961904...
- fit(X, y)[source]#
根据给定的训练数据拟合模型。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
训练样本。
- yarray-like of shape (n_samples,)
相应的训练标签。
- 返回:
- selfobject
拟合的估计器。
- fit_transform(X, y=None, **fit_params)[source]#
拟合数据,然后对其进行转换。
使用可选参数
fit_params将转换器拟合到X和y,并返回X的转换版本。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
输入样本。
- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组对象,默认=None
目标值(对于无监督转换,为 None)。
- **fit_paramsdict
额外的拟合参数。仅当估计器在其
fit方法中接受额外的参数时才传递。
- 返回:
- X_newndarray array of shape (n_samples, n_features_new)
转换后的数组。
- get_feature_names_out(input_features=None)[source]#
获取转换的输出特征名称。
The feature names out will prefixed by the lowercased class name. For example, if the transformer outputs 3 features, then the feature names out are:
["class_name0", "class_name1", "class_name2"].- 参数:
- input_featuresarray-like of str or None, default=None
Only used to validate feature names with the names seen in
fit.
- 返回:
- feature_names_outstr 对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用 API 的示例,请参阅引入 set_output API。
- 参数:
- transform{“default”, “pandas”, “polars”}, default=None
配置
transform和fit_transform的输出。"default": 转换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 转换配置保持不变
1.4 版本新增: 添加了
"polars"选项。
- 返回:
- selfestimator instance
估计器实例。