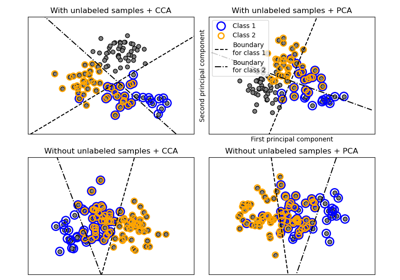
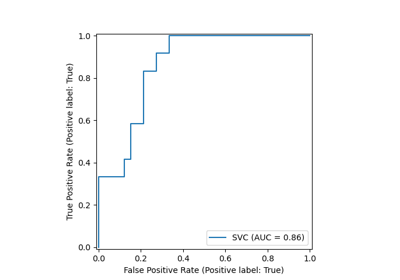
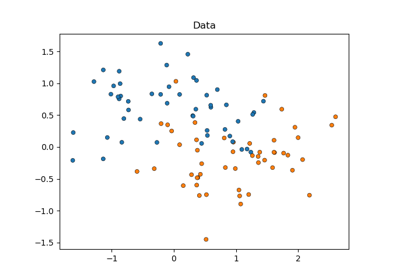
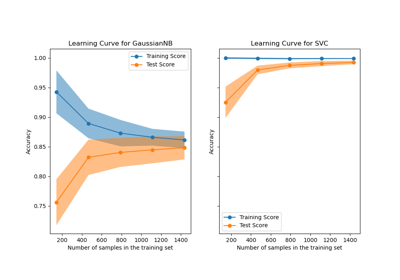
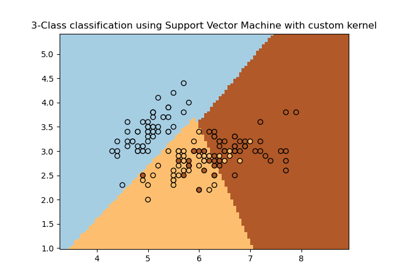
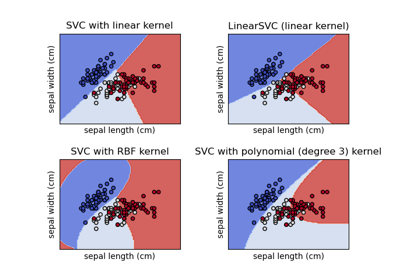
SVC#
- class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)[source]#
C-支持向量分类。
此实现基于 libsvm。拟合时间至少随样本数量呈二次方增长,对于数万个以上的样本可能不切实际。对于大型数据集,请考虑使用
LinearSVC或SGDClassifier,可能在应用Nystroem转换器或其他 核近似 之后。多类别支持按照一对一方案处理。
有关所提供的核函数的精确数学公式以及
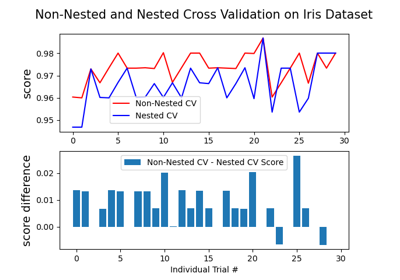
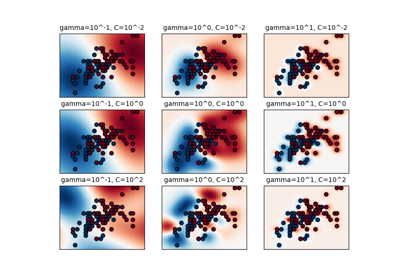
gamma、coef0和degree如何相互影响的详细信息,请参阅叙述文档中的相应部分:核函数。要了解如何调整 SVC 的超参数,请参阅以下示例:嵌套交叉验证与非嵌套交叉验证
阅读更多内容,请参阅 用户指南。
- 参数:
- Cfloat, default=1.0
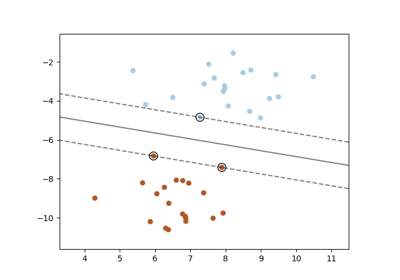
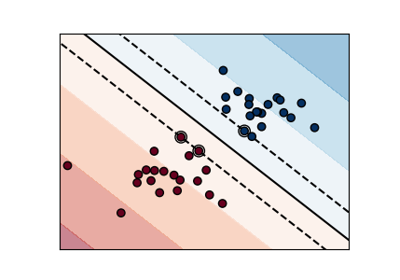
正则化参数。正则化强度与 C 成反比。必须严格为正数。惩罚项为平方 l2 惩罚。有关缩放正则化参数 C 效果的直观可视化,请参阅SVC 正则化参数缩放。
- kernel{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} 或可调用对象,默认值为’rbf’
指定算法中使用的核类型。如果未给出,则使用 'rbf'。如果给定一个可调用对象,它用于从数据矩阵预先计算核矩阵;该矩阵应为形状
(n_samples, n_samples)的数组。有关不同核类型的直观可视化,请参阅使用不同 SVM 核绘制分类边界。- degreeint,默认值为3
多项式核函数(‘poly’)的次数。必须是非负的。其他所有核函数均忽略此参数。
- gamma{‘scale’, ‘auto’} 或 float,默认值为’scale’
‘rbf’、‘poly’ 和 ‘sigmoid’ 的核系数。
如果传递
gamma='scale'(默认值),则使用 1 / (n_features * X.var()) 作为 gamma 的值,如果为 ‘auto’,则使用 1 / n_features
如果为 float,则必须是非负的。
版本 0.22 中已更改:
gamma的默认值从 ‘auto’ 更改为 ‘scale’。- coef0float,默认值为0.0
核函数中的常数项。它仅在 ‘poly’ 和 ‘sigmoid’ 中很重要。
- shrinkingbool,默认值为True
是否使用收缩启发式方法。请参阅 用户指南。
- probabilitybool, default=False
是否启用概率估计。必须在调用
fit之前启用此功能,这将减慢该方法的速度,因为它在内部使用 5 折交叉验证,并且predict_proba可能与predict不一致。在用户指南中阅读更多内容。- tolfloat, default=1e-3
停止准则的容差。
- cache_sizefloat,默认值为200
指定核缓存的大小(以 MB 为单位)。
- class_weightdict or ‘balanced’, default=None
将类别 i 的参数 C 设置为 class_weight[i]*C(对于 SVC)。如果未给定,则所有类别都被假定具有权重一。“balanced”模式使用 y 的值根据输入数据中类别频率的倒数自动调整权重,计算公式为
n_samples / (n_classes * np.bincount(y))。- verbosebool, default=False
启用详细输出。请注意,此设置利用了 libsvm 中一个每个进程的运行时设置,如果启用,在多线程环境中可能无法正常工作。
- max_iterint,默认值为-1
求解器内迭代次数的硬限制,或者 -1 表示无限制。
- decision_function_shape{‘ovo’, ‘ovr’}, default=’ovr’
是返回形状为 (n_samples, n_classes) 的一对多 ('ovr') 决策函数(如所有其他分类器),还是返回 libsvm 原始的一对一 ('ovo') 决策函数,其形状为 (n_samples, n_classes * (n_classes - 1) / 2)。然而,请注意,在内部,一对一 ('ovo') 始终用作训练模型的多类别策略;ovr 矩阵仅由 ovo 矩阵构建。对于二元分类,此参数被忽略。
版本 0.19 中有更改: decision_function_shape 默认为 'ovr'。
版本 0.17 中新增: 推荐使用 decision_function_shape='ovr'。
版本 0.17 中有更改: 弃用 decision_function_shape='ovo' 和 None。
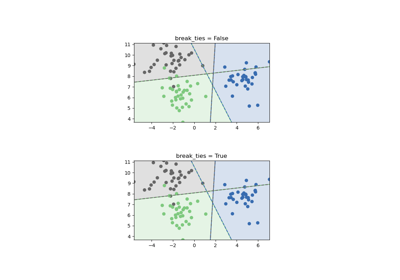
- break_tiesbool, default=False
如果为 True,
decision_function_shape='ovr',且类别数 > 2,则 predict 将根据 decision_function 的置信度值打破平局;否则返回平局类别中的第一个类别。请注意,与简单的预测相比,打破平局会带来相对较高的计算成本。有关其与decision_function_shape='ovr'用法的示例,请参阅SVM 平局打破示例。版本 0.22 新增。
- random_stateint, RandomState instance or None, default=None
控制用于打乱数据以进行概率估计的伪随机数生成。当
probability为 False 时忽略。传入一个整数以在多次函数调用中获得可重现的输出。请参阅术语表。
- 属性:
- class_weight_ndarray of shape (n_classes,)
每个类别的参数 C 的乘数。根据
class_weight参数计算。- classes_ndarray of shape (n_classes,)
类别标签。
coef_ndarray of shape (n_classes * (n_classes - 1) / 2, n_features)当
kernel="linear"时分配给特征的权重。- dual_coef_ndarray of shape (n_classes -1, n_SV)
决策函数中支持向量的对偶系数(参见数学公式),乘以其目标值。对于多类别情况,是所有 1 对 1 分类器的系数。多类别情况下系数的布局有些不简单。有关详细信息,请参阅用户指南的多类别部分。
- fit_status_int
0 表示拟合正确,1 表示否则(将引发警告)
- intercept_ndarray of shape (n_classes * (n_classes - 1) / 2,)
决策函数中的常数。
- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
- n_iter_ndarray of shape (n_classes * (n_classes - 1) // 2,)
优化例程拟合模型运行的迭代次数。此属性的形状取决于优化的模型数量,而模型数量又取决于类别的数量。
版本 1.1 中新增。
- support_ndarray of shape (n_SV)
支持向量的索引。
- support_vectors_ndarray,形状为 (n_SV, n_features)
支持向量。如果核是预先计算的,则为空数组。
n_support_ndarray,形状为 (n_classes,),dtype=int32每个类别的支持向量数量。
probA_ndarray of shape (n_classes * (n_classes - 1) / 2)当
probability=True时,在 Platt 定标中学习到的参数。probB_ndarray of shape (n_classes * (n_classes - 1) / 2)当
probability=True时,在 Platt 定标中学习到的参数。- shape_fit_tuple of int,形状为 (n_dimensions_of_X,)
训练向量
X的数组维度。
另请参阅
References
[1]示例
>>> import numpy as np >>> from sklearn.pipeline import make_pipeline >>> from sklearn.preprocessing import StandardScaler >>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) >>> y = np.array([1, 1, 2, 2]) >>> from sklearn.svm import SVC >>> clf = make_pipeline(StandardScaler(), SVC(gamma='auto')) >>> clf.fit(X, y) Pipeline(steps=[('standardscaler', StandardScaler()), ('svc', SVC(gamma='auto'))])
>>> print(clf.predict([[-0.8, -1]])) [1]
有关 SVC 与其他分类器的比较,请参阅:绘制分类概率。
- decision_function(X)[source]#
评估 X 中样本的决策函数。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
输入样本。
- 返回:
- Xndarray of shape (n_samples, n_classes * (n_classes-1) / 2)
返回模型中每个类别的样本决策函数。如果 decision_function_shape='ovr',则形状为 (n_samples, n_classes)。
注意事项
如果 decision_function_shape='ovo',则函数值与样本 X 到分离超平面的距离成正比。如果需要精确距离,请将函数值除以权重向量 (
coef_) 的范数。有关更多详细信息,另请参阅此问题。如果 decision_function_shape='ovr',则决策函数是 ovo 决策函数的单调变换。
- fit(X, y, sample_weight=None)[source]#
根据给定的训练数据拟合 SVM 模型。
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features) or (n_samples, n_samples)
训练向量,其中
n_samples是样本数量,n_features是特征数量。对于 kernel=”precomputed”,X 的预期形状为 (n_samples, n_samples)。- yarray-like of shape (n_samples,)
目标值(分类中的类别标签,回归中的实数)。
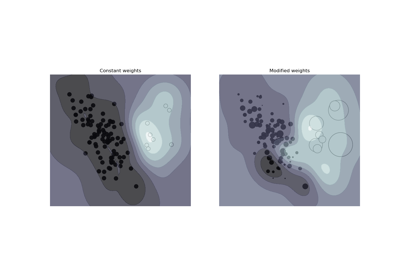
- sample_weightshape 为 (n_samples,) 的 array-like, default=None
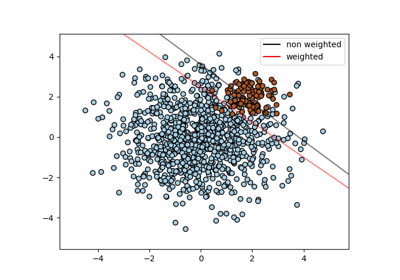
每个样本的权重。为每个样本重新缩放 C。更高的权重会迫使分类器更加重视这些点。
- 返回:
- selfobject
拟合的估计器。
注意事项
如果 X 和 y 不是 C 顺序且连续的 np.float64 数组,并且 X 不是 scipy.sparse.csr_matrix,则 X 和/或 y 可能会被复制。
如果 X 是密集数组,那么其他方法将不支持稀疏矩阵作为输入。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- predict(X)[source]#
对 X 中的样本进行分类。
对于单类别模型,返回 +1 或 -1。
- 参数:
- X{array-like, sparse matrix},形状为 (n_samples, n_features) 或 (n_samples_test, n_samples_train)
对于 kernel=”precomputed”,X 的预期形状为 (n_samples_test, n_samples_train)。
- 返回:
- y_pred形状为 (n_samples,) 的 ndarray
X 中样本的类别标签。
- predict_log_proba(X)[source]#
计算 X 中样本可能结果的对数概率。
模型需要在训练时计算概率信息:使用属性
probability设置为 True 进行拟合。- 参数:
- Xarray-like of shape (n_samples, n_features) or (n_samples_test, n_samples_train)
对于 kernel=”precomputed”,X 的预期形状为 (n_samples_test, n_samples_train)。
- 返回:
- Tndarray of shape (n_samples, n_classes)
返回模型中每个类别的样本对数概率。列对应于按排序顺序排列的类别,如属性 classes_ 中所示。
注意事项
概率模型是使用交叉验证创建的,因此结果可能与通过 predict 获得的结果略有不同。此外,它在非常小的数据集上会产生无意义的结果。
- predict_proba(X)[source]#
Compute probabilities of possible outcomes for samples in X.
模型需要在训练时计算概率信息:使用属性
probability设置为 True 进行拟合。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
对于 kernel=”precomputed”,X 的预期形状为 (n_samples_test, n_samples_train)。
- 返回:
- Tndarray of shape (n_samples, n_classes)
返回模型中每个类别的样本概率。列对应于按排序顺序排列的类别,如属性 classes_ 中所示。
注意事项
概率模型是使用交叉验证创建的,因此结果可能与通过 predict 获得的结果略有不同。此外,它在非常小的数据集上会产生无意义的结果。
- score(X, y, sample_weight=None)[source]#
返回在提供的数据和标签上的 准确率 (accuracy)。
在多标签分类中,这是子集准确率 (subset accuracy),这是一个严格的指标,因为它要求每个样本的每个标签集都被正确预测。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
测试样本。
- yshape 为 (n_samples,) 或 (n_samples, n_outputs) 的 array-like
X的真实标签。- sample_weightshape 为 (n_samples,) 的 array-like, default=None
样本权重。
- 返回:
- scorefloat
self.predict(X)相对于y的平均准确率。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SVC[source]#
配置是否应请求元数据以传递给
fit方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
fit方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单的估计器以及嵌套对象(如
Pipeline)。后者具有<component>__<parameter>形式的参数,以便可以更新嵌套对象的每个组件。- 参数:
- **paramsdict
估计器参数。
- 返回:
- selfestimator instance
估计器实例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SVC[source]#
配置是否应请求元数据以传递给
score方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给score。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给score。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
score方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。