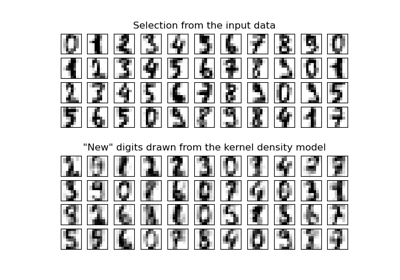
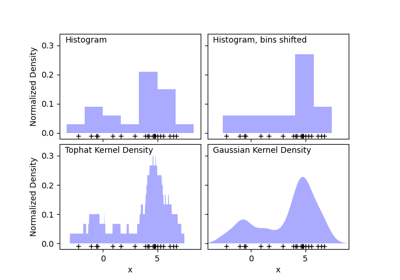
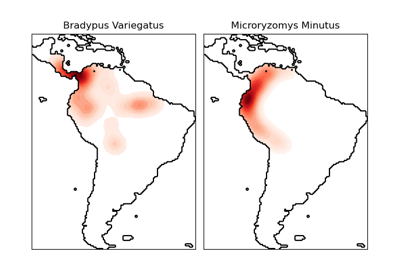
KernelDensity#
- class sklearn.neighbors.KernelDensity(*, bandwidth=1.0, algorithm='auto', kernel='gaussian', metric='euclidean', atol=0, rtol=0, breadth_first=True, leaf_size=40, metric_params=None)[源代码]#
核密度估计。
更多信息请参阅 用户指南。
- 参数:
- bandwidthfloat 或 {“scott”, “silverman”}, default=1.0
核的带宽。如果 bandwidth 是一个浮点数,它定义了核的带宽。如果 bandwidth 是一个字符串,则实现了其中一种估计方法。
- algorithm{‘kd_tree’, ‘ball_tree’, ‘auto’}, default=’auto’
要使用的树算法。
- kernel{‘gaussian’, ‘tophat’, ‘epanechnikov’, ‘exponential’, ‘linear’, ‘cosine’}, default=’gaussian’
要使用的核。
- metricstr, default=’euclidean’
用于距离计算的度量。有关有效的度量值,请参阅 scipy.spatial.distance 的文档以及
distance_metrics中列出的度量。并非所有度量都适用于所有算法:请参阅
BallTree和KDTree的文档。请注意,密度输出的归一化仅对欧几里得距离度量是正确的。- atolfloat,默认值=0
结果所需的绝对容差。较大的容差通常会导致更快的执行。
- rtolfloat, default=0
结果所需的相对容差。较大的容差通常会导致更快的执行。
- breadth_firstbool, default=True
如果为 True(默认值),则使用广度优先的方法来解决问题。否则,使用深度优先的方法。
- leaf_sizeint, default=40
- metric_paramsdict, default=None
- 属性:
另请参阅
sklearn.neighbors.KDTreeK 维树,用于快速广义 N 点问题。
sklearn.neighbors.BallTree球树,用于快速广义 N 点问题。
示例
使用固定带宽计算高斯核密度估计。
>>> from sklearn.neighbors import KernelDensity >>> import numpy as np >>> rng = np.random.RandomState(42) >>> X = rng.random_sample((100, 3)) >>> kde = KernelDensity(kernel='gaussian', bandwidth=0.5).fit(X) >>> log_density = kde.score_samples(X[:3]) >>> log_density array([-1.52955942, -1.51462041, -1.60244657])
- fit(X, y=None, sample_weight=None)[源代码]#
在数据上拟合 Kernel Density 模型。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
n_features维数据点列表。每行对应一个数据点。
- yNone
忽略。此参数仅用于与
Pipeline的兼容性。- sample_weightshape 为 (n_samples,) 的 array-like, default=None
附加到数据 X 的样本权重列表。
0.20 版本新增。
- 返回:
- selfobject
返回实例本身。
- get_metadata_routing()[源代码]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[源代码]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- sample(n_samples=1, random_state=None)[源代码]#
从模型生成随机样本。
目前,仅为高斯核和顶帽核实现此功能。
- 参数:
- n_samplesint, default=1
要生成的样本数量。
- random_stateint, RandomState instance or None, default=None
确定用于生成随机样本的随机数生成。传递一个整数以确保多次函数调用结果的可重现性。请参阅 术语表。
- 返回:
- Xshape 为 (n_samples, n_features) 的 array-like
样本列表。
- score(X, y=None)[源代码]#
计算模型下的总对数似然。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
n_features维数据点列表。每行对应一个数据点。
- yNone
忽略。此参数仅用于与
Pipeline的兼容性。
- 返回:
- logprobfloat
X 中数据的总对数似然。这将归一化为概率密度,因此对于高维数据,该值将很低。
- score_samples(X)[源代码]#
计算模型下每个样本的对数似然。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
要查询的点列表。最后一个维度应与训练数据的维度(n_features)匹配。
- 返回:
- densityndarray of shape (n_samples,)
X 中每个样本的对数似然。这些已归一化为概率密度,因此对于高维数据,值将很低。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KernelDensity[源代码]#
配置是否应请求元数据以传递给
fit方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
fit方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。