QuadraticDiscriminantAnalysis#
- class sklearn.discriminant_analysis.QuadraticDiscriminantAnalysis(*, solver='svd', shrinkage=None, priors=None, reg_param=0.0, store_covariance=False, tol=0.0001, covariance_estimator=None)[source]#
二次判别分析。
通过拟合数据的类条件密度并使用贝叶斯规则生成的具有二次决策边界的分类器。
该模型为每个类拟合一个高斯密度。
版本0.17中新增。
有关
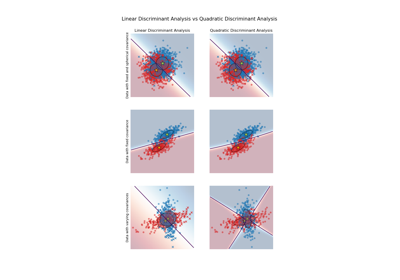
QuadraticDiscriminantAnalysis和LinearDiscriminantAnalysis的比较,请参阅 带协方差椭球的线性和二次判别分析。请在 用户指南 中阅读更多内容。
- 参数:
- solver{‘svd’, ‘eigen’}, default=’svd’
- 要使用的求解器,可能的值为
‘svd’:奇异值分解(默认)。不计算协方差矩阵,因此建议对具有大量特征的数据使用此求解器。
‘eigen’:特征值分解。可以与收缩或自定义协方差估计器结合使用。
- shrinkage‘auto’ or float, default=None
- 收缩参数,可能的值为
None:不收缩(默认)。
‘auto’:使用Ledoit-Wolf引理进行自动收缩。
0 到 1 之间的浮点数:固定的收缩参数。
当某些类别的训练数据点数量相对于特征数量较少时,启用收缩有望通过减轻协方差估计步骤中的过拟合来改善模型。
如果使用了
covariance_estimator,则应将其设置为None。请注意,收缩仅适用于 ‘eigen’ 求解器。- priorsarray-like of shape (n_classes,), default=None
类别先验。默认情况下,类别比例从训练数据中推断得出。
- reg_paramfloat, default=0.0
通过将 S2 转换为
S2 = (1 - reg_param) * S2 + reg_param * np.eye(n_features)来正则化每个类别的协方差估计,其中 S2 对应于给定类别的scaling_属性。- store_covariancebool, default=False
如果为 True,则显式计算类别协方差矩阵并将其存储在
self.covariance_属性中。版本0.17中新增。
- tolfloat, default=1.0e-4
在对每个
Sk(其中Sk表示第 k 类的协方差矩阵)应用一些正则化(参见reg_param)后,协方差矩阵被视为秩亏欠的绝对阈值。此参数不影响预测。它控制当协方差矩阵不是满秩时何时发出警告。版本0.17中新增。
- covariance_estimatorcovariance estimator, default=None
如果不是 None,则使用
covariance_estimator来估计协方差矩阵,而不是依赖经验协方差估计器(具有潜在收缩)。该对象应具有 fit 方法和covariance_属性,如sklearn.covariance中的估计器。如果为 None,则收缩参数驱动估计。如果使用了
shrinkage,则应将其设置为None。请注意,covariance_estimator仅适用于 ‘eigen’ 求解器。
- 属性:
- covariance_list of len n_classes of ndarray of shape (n_features, n_features)
对于每个类,给出使用该类的样本估计的协方差矩阵。估计是无偏的。仅当
store_covariance为 True 时才存在。- means_array-like of shape (n_classes, n_features)
各类的均值。
- priors_array-like of shape (n_classes,)
类别先验(总和为 1)。
- rotations_list of len n_classes of ndarray of shape (n_features, n_k)
对于每个类别 k,形状为 (n_features, n_k) 的数组,其中
n_k = min(n_features, number of elements in class k)。它是高斯分布的旋转,即其主轴。它对应于V,即来自Xk = U S Vt的 SVD 的特征向量矩阵,其中Xk是来自类别 k 的居中样本矩阵。- scalings_list of len n_classes of ndarray of shape (n_k,)
对于每个类,包含高斯分布沿其主轴的缩放比例,即旋转坐标系中的方差。它对应于
S^2 / (n_samples - 1),其中S是来自Xk的 SVD 的奇异值对角矩阵,其中Xk是来自类别 k 的居中样本矩阵。- classes_ndarray of shape (n_classes,)
唯一的类标签。
- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
另请参阅
LinearDiscriminantAnalysis线性判别分析。
示例
>>> from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis >>> import numpy as np >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> y = np.array([1, 1, 1, 2, 2, 2]) >>> clf = QuadraticDiscriminantAnalysis() >>> clf.fit(X, y) QuadraticDiscriminantAnalysis() >>> print(clf.predict([[-0.8, -1]])) [1]
- decision_function(X)[source]#
将决策函数应用于样本数组。
决策函数等于(相差一个常数因子)模型的对数后验,即
log p(y = k | x)。在二元分类设置中,这对应于差异log p(y = 1 | x) - log p(y = 0 | x)。请参阅 LDA 和 QDA 分类器的数学公式。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
样本数组(测试向量)。
- 返回:
- Cndarray of shape (n_samples,) or (n_samples, n_classes)
与每个类相关的决策函数值,按样本划分。在两类情况下,形状为
(n_samples,),给出正类的对数似然比。
- fit(X, y)[source]#
根据给定的训练数据和参数拟合模型。
版本 0.19 中的更改:
store_covariances已作为store_covariance移至主构造函数。版本 0.19 中的更改:
tol已移至主构造函数。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
训练向量,其中
n_samples是样本数,n_features是特征数。- yarray-like of shape (n_samples,)
目标值(整数)。
- 返回:
- selfobject
拟合的估计器。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- predict(X)[source]#
对向量数组
X执行分类。返回每个样本的类别标签。
- 参数:
- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
输入向量,其中
n_samples是样本数,n_features是特征数。
- 返回:
- y_pred形状为 (n_samples,) 的 ndarray
每个样本的类别标签。
- predict_log_proba(X)[source]#
估计对数类别概率。
- 参数:
- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
Input data.
- 返回:
- y_log_proba形状为 (n_samples, n_classes) 的 ndarray
估计的对数概率。
- predict_proba(X)[source]#
估计类别概率。
- 参数:
- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
Input data.
- 返回:
- y_proba形状为 (n_samples, n_classes) 的 ndarray
样本对于模型中每个类别的概率估计,类别按
self.classes_中的顺序排列。
- score(X, y, sample_weight=None)[source]#
返回在提供的数据和标签上的 准确率 (accuracy)。
在多标签分类中,这是子集准确率 (subset accuracy),这是一个严格的指标,因为它要求每个样本的每个标签集都被正确预测。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
测试样本。
- yshape 为 (n_samples,) 或 (n_samples, n_outputs) 的 array-like
X的真实标签。- sample_weightshape 为 (n_samples,) 的 array-like, default=None
样本权重。
- 返回:
- scorefloat
self.predict(X)相对于y的平均准确率。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单的估计器以及嵌套对象(如
Pipeline)。后者具有<component>__<parameter>形式的参数,以便可以更新嵌套对象的每个组件。- 参数:
- **paramsdict
估计器参数。
- 返回:
- selfestimator instance
估计器实例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') QuadraticDiscriminantAnalysis[source]#
配置是否应请求元数据以传递给
score方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给score。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给score。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
score方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。