KBinsDiscretizer#
- class sklearn.preprocessing.KBinsDiscretizer(n_bins=5, *, encode='onehot', strategy='quantile', quantile_method='warn', dtype=None, subsample=200000, random_state=None)[source]#
将连续数据分成区间。
更多信息请参阅 用户指南。
0.20 版本新增。
- 参数:
- n_binsint 或 array-like,形状为 (n_features,),默认为 5
要生成的箱的数量。如果
n_bins < 2,则引发 ValueError。- encode{‘onehot’, ‘onehot-dense’, ‘ordinal’},默认值为 ‘onehot’
用于编码转换结果的方法。
‘onehot’:使用独热编码对转换后的结果进行编码,并返回稀疏矩阵。被忽略的特征将始终堆叠在右侧。
‘onehot-dense’:使用独热编码对转换后的结果进行编码,并返回密集数组。被忽略的特征将始终堆叠在右侧。
‘ordinal’:将箱标识符编码为整数值。
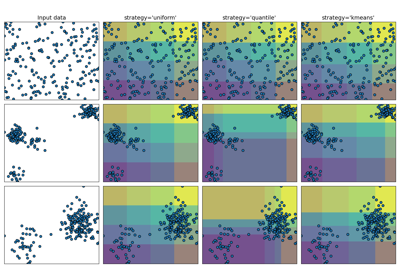
- strategy{‘uniform’, ‘quantile’, ‘kmeans’},默认值为 ‘quantile’
用于定义 bin 宽度的策略。
‘uniform’:每个特征中的所有箱具有相同的宽度。
‘quantile’:每个特征中的所有箱具有相同数量的点。
‘kmeans’:每个箱中的值具有相同的 1D k-means 聚类中心。
关于不同策略的示例,请参阅:演示 KBinsDiscretizer 的不同策略。
- quantile_method{“inverted_cdf”, “averaged_inverted_cdf”,
“closest_observation”, “interpolated_inverted_cdf”, “hazen”, “weibull”, “linear”, “median_unbiased”, “normal_unbiased”},默认值为 “linear” 当使用 strategy=”quantile” 时,传递给 np.percentile 计算的方法。只有
averaged_inverted_cdf和inverted_cdf支持在使用sample_weight != None且不激活子采样时使用。在版本 1.7 中新增。
- dtype{np.float32, np.float64},默认值为 None
输出的期望数据类型。如果为 None,则输出数据类型与输入数据类型一致。仅支持 np.float32 和 np.float64。
0.24 版本新增。
- subsampleint 或 None,默认值为 200_000
用于拟合模型以提高计算效率的最大样本数。
subsample=None表示在计算确定分箱阈值的分位数时使用所有训练样本。由于分位数计算依赖于对X的每一列进行排序,而排序具有n log(n)的时间复杂度,因此建议在样本量非常大的数据集上使用子采样。版本 1.3 中已更改:当
strategy="quantile"时,subsample的默认值从None更改为200_000。版本 1.5 中已更改:当
strategy="uniform"或strategy="kmeans"时,subsample的默认值从None更改为200_000。- random_stateint, RandomState instance or None, default=None
确定子采样的随机数生成。传入一个整数以获得跨多个函数调用的可重复结果。有关更多详细信息,请参阅
subsample参数。请参阅 术语表。版本 1.1 中新增。
- 属性:
- bin_edges_ndarray,形状为 (n_features,) 的 ndarray 数组
每个箱的边缘。包含形状各异的数组
(n_bins_, )。被忽略的特征将具有空数组。- n_bins_ndarray,形状为 (n_features,),dtype=np.int64
每个特征的箱数。宽度过小(即 <= 1e-8)的箱将被移除并发出警告。
- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
另请参阅
Binarizer基于参数
threshold将值划分为0或1的类。
注意事项
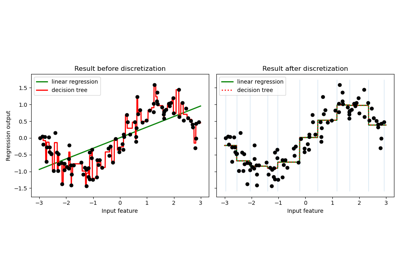
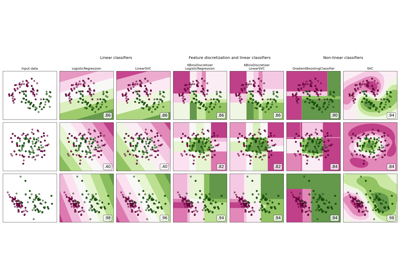
关于在不同数据集上进行离散化的可视化,请参阅 特征离散化。关于离散化对线性模型的影响,请参阅:使用 KBinsDiscretizer 对连续特征进行离散化。
在特征
i的分箱边缘中,第一个和最后一个值仅用于inverse_transform。在转换过程中,分箱边缘被扩展到np.concatenate([-np.inf, bin_edges_[i][1:-1], np.inf])
如果您只想预处理部分特征,可以将
KBinsDiscretizer与ColumnTransformer结合使用。KBinsDiscretizer可能会产生常数特征(例如,当encode = 'onehot'且某些箱中没有任何数据时)。这些特征可以使用特征选择算法(例如VarianceThreshold)移除。示例
>>> from sklearn.preprocessing import KBinsDiscretizer >>> X = [[-2, 1, -4, -1], ... [-1, 2, -3, -0.5], ... [ 0, 3, -2, 0.5], ... [ 1, 4, -1, 2]] >>> est = KBinsDiscretizer( ... n_bins=3, encode='ordinal', strategy='uniform' ... ) >>> est.fit(X) KBinsDiscretizer(...) >>> Xt = est.transform(X) >>> Xt array([[ 0., 0., 0., 0.], [ 1., 1., 1., 0.], [ 2., 2., 2., 1.], [ 2., 2., 2., 2.]])
有时将数据转换回原始特征空间可能很有用。
inverse_transform函数将分箱后的数据转换回原始特征空间。每个值将等于两个分箱边缘的平均值。>>> est.bin_edges_[0] array([-2., -1., 0., 1.]) >>> est.inverse_transform(Xt) array([[-1.5, 1.5, -3.5, -0.5], [-0.5, 2.5, -2.5, -0.5], [ 0.5, 3.5, -1.5, 0.5], [ 0.5, 3.5, -1.5, 1.5]])
尽管此预处理步骤可以是一种优化,但请注意,
inverse_transform返回的数组的内部类型将是np.float64或np.float32,由dtype输入参数指定。这可能会极大地增加数组的内存使用量。请参阅 矢量量化示例,其中KBinsDiscretizer用于将图像分箱聚类,并将图像大小增加了 8 倍。- fit(X, y=None, sample_weight=None)[source]#
拟合估计量。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
要离散化的数据。
- yNone
忽略。此参数仅用于与
Pipeline的兼容性。- sample_weightndarray,形状为 (n_samples,)
包含要与每个样本关联的权重值。
在版本 1.3 中新增。
版本 1.7 中已更改:添加了对 strategy=”uniform” 的支持。
- 返回:
- selfobject
返回实例本身。
- fit_transform(X, y=None, **fit_params)[source]#
拟合数据,然后对其进行转换。
使用可选参数
fit_params将转换器拟合到X和y,并返回X的转换版本。- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
输入样本。
- y形状为 (n_samples,) 或 (n_samples, n_outputs) 的类数组对象,默认=None
目标值(对于无监督转换,为 None)。
- **fit_paramsdict
额外的拟合参数。仅当估计器在其
fit方法中接受额外的参数时才传递。
- 返回:
- X_newndarray array of shape (n_samples, n_features_new)
转换后的数组。
- get_feature_names_out(input_features=None)[source]#
获取输出特征名称。
- 参数:
- input_featuresarray-like of str or None, default=None
输入特征。
如果
input_features为None,则使用feature_names_in_作为输入特征名称。如果feature_names_in_未定义,则生成以下输入特征名称:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features是 array-like,则如果定义了feature_names_in_,input_features必须与feature_names_in_匹配。
- 返回:
- feature_names_outstr 对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- inverse_transform(X)[source]#
将离散化后的数据转换回原始特征空间。
请注意,由于离散化的舍入,此函数无法重新生成原始数据。
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
分箱空间中的转换数据。
- 返回:
- X_originalndarray,dtype={np.float32, np.float64}
原始特征空间中的数据。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KBinsDiscretizer[source]#
配置是否应请求元数据以传递给
fit方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
fit方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用 API 的示例,请参阅引入 set_output API。
- 参数:
- transform{“default”, “pandas”, “polars”}, default=None
配置
transform和fit_transform的输出。"default": 转换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 转换配置保持不变
1.4 版本新增: 添加了
"polars"选项。
- 返回:
- selfestimator instance
估计器实例。