l1_min_c#
- sklearn.svm.l1_min_c(X, y, *, loss='squared_hinge', fit_intercept=True, intercept_scaling=1.0)[源代码]#
返回
C的最低界限。计算
C的下界,使得当C在(l1_min_C, infinity)范围内时,模型保证非空。这适用于 L1 正则化的分类器,例如sklearn.svm.LinearSVC(设置 penalty='l1')和sklearn.linear_model.LogisticRegression(设置l1_ratio=1)。如果
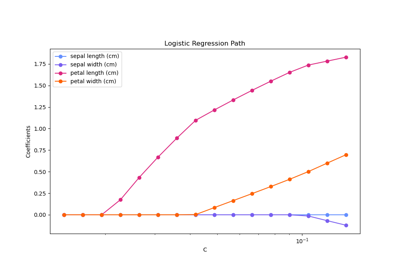
fit()方法中的class_weight参数未设置,则此值有效。有关如何使用此功能的示例,请参阅 L1 逻辑回归的正则化路径。
- 参数:
- Xshape 为 (n_samples, n_features) 的 {array-like, sparse matrix}
训练向量,其中
n_samples是样本数,n_features是特征数。- yarray-like of shape (n_samples,)
相对于 X 的目标向量。
- loss{‘squared_hinge’, ‘log’}, 默认值为 ‘squared_hinge’
指定损失函数。对于 ‘squared_hinge’,它是平方合页损失(也称为 L2 损失)。对于 ‘log’,它是逻辑回归模型的损失。
- fit_interceptbool, default=True
指定是否由模型拟合截距。它必须与 fit() 方法的参数匹配。
- intercept_scalingfloat, 默认值为 1.0
当 fit_intercept 为 True 时,实例向量 x 变为 [x, intercept_scaling],即一个常数值等于 intercept_scaling 的“合成”特征被附加到实例向量。它必须与 fit() 方法的参数匹配。
- 返回:
- l1_min_cfloat
C 的最小值。
示例
>>> from sklearn.svm import l1_min_c >>> from sklearn.datasets import make_classification >>> X, y = make_classification(n_samples=100, n_features=20, random_state=42) >>> print(f"{l1_min_c(X, y, loss='squared_hinge', fit_intercept=True):.4f}") 0.0044