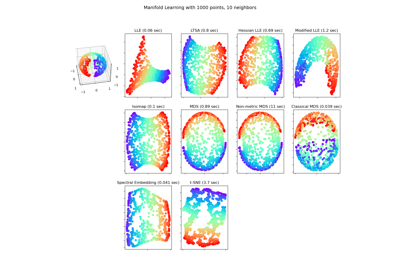
LocallyLinearEmbedding#
- class sklearn.manifold.LocallyLinearEmbedding(*, n_neighbors=5, n_components=2, reg=0.001, eigen_solver='auto', tol=1e-06, max_iter=100, method='standard', hessian_tol=0.0001, modified_tol=1e-12, neighbors_algorithm='auto', random_state=None, n_jobs=None)[source]#
局部线性嵌入。
Read more in the User Guide.
- 参数:
- n_neighborsint, default=5
Number of neighbors to consider for each point.
- n_componentsint, default=2
流形的坐标数量。
- regfloat, default=1e-3
Regularization constant, multiplies the trace of the local covariance matrix of the distances.
- eigen_solver{‘auto’, ‘arpack’, ‘dense’}, default=’auto’
The solver used to compute the eigenvectors. The available options are
'auto': algorithm will attempt to choose the best method for input data.'arpack': use arnoldi iteration in shift-invert mode. For this method, M may be a dense matrix, sparse matrix, or general linear operator.'dense': use standard dense matrix operations for the eigenvalue decomposition. For this method, M must be an array or matrix type. This method should be avoided for large problems.
警告
ARPACK can be unstable for some problems. It is best to try several random seeds in order to check results.
- tolfloat, default=1e-6
Tolerance for ‘arpack’ method Not used if eigen_solver==’dense’.
- max_iterint, default=100
Maximum number of iterations for the arpack solver. Not used if eigen_solver==’dense’.
- method{‘standard’, ‘hessian’, ‘modified’, ‘ltsa’}, default=’standard’
standard: use the standard locally linear embedding algorithm. see reference [1]hessian: use the Hessian eigenmap method. This method requiresn_neighbors > n_components * (1 + (n_components + 1) / 2. see reference [2]modified: use the modified locally linear embedding algorithm. see reference [3]ltsa: use local tangent space alignment algorithm. see reference [4]
- hessian_tolfloat, default=1e-4
Tolerance for Hessian eigenmapping method. Only used if
method == 'hessian'.- modified_tolfloat, default=1e-12
Tolerance for modified LLE method. Only used if
method == 'modified'.- neighbors_algorithm{‘auto’, ‘brute’, ‘kd_tree’, ‘ball_tree’}, default=’auto’
Algorithm to use for nearest neighbors search, passed to
NearestNeighborsinstance.- random_stateint, RandomState instance, default=None
Determines the random number generator when
eigen_solver== ‘arpack’. Pass an int for reproducible results across multiple function calls. See Glossary.- n_jobsint or None, default=None
The number of parallel jobs to run.
Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors. See Glossary for more details.
- 属性:
- embedding_array-like, shape [n_samples, n_components]
Stores the embedding vectors
- reconstruction_error_float
Reconstruction error associated with
embedding_- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
- nbrs_NearestNeighbors object
Stores nearest neighbors instance, including BallTree or KDtree if applicable.
另请参阅
SpectralEmbedding用于非线性降维的谱嵌入。
TSNEDistributed Stochastic Neighbor Embedding.
References
[1]Roweis, S. & Saul, L. Nonlinear dimensionality reduction by locally linear embedding. Science 290:2323 (2000).
[2]Donoho, D. & Grimes, C. Hessian eigenmaps: Locally linear embedding techniques for high-dimensional data. Proc Natl Acad Sci U S A. 100:5591 (2003).
[4]Zhang, Z. & Zha, H. Principal manifolds and nonlinear dimensionality reduction via tangent space alignment. Journal of Shanghai Univ. 8:406 (2004)
示例
>>> from sklearn.datasets import load_digits >>> from sklearn.manifold import LocallyLinearEmbedding >>> X, _ = load_digits(return_X_y=True) >>> X.shape (1797, 64) >>> embedding = LocallyLinearEmbedding(n_components=2) >>> X_transformed = embedding.fit_transform(X[:100]) >>> X_transformed.shape (100, 2)
- fit(X, y=None)[source]#
Compute the embedding vectors for data X.
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
Training set.
- y被忽略
Not used, present here for API consistency by convention.
- 返回:
- selfobject
Fitted
LocallyLinearEmbeddingclass instance.
- fit_transform(X, y=None)[source]#
Compute the embedding vectors for data X and transform X.
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
Training set.
- y被忽略
Not used, present here for API consistency by convention.
- 返回:
- X_newarray-like, shape (n_samples, n_components)
返回实例本身。
- get_feature_names_out(input_features=None)[source]#
获取转换的输出特征名称。
The feature names out will prefixed by the lowercased class name. For example, if the transformer outputs 3 features, then the feature names out are:
["class_name0", "class_name1", "class_name2"].- 参数:
- input_featuresarray-like of str or None, default=None
Only used to validate feature names with the names seen in
fit.
- 返回:
- feature_names_outstr 对象的 ndarray
转换后的特征名称。
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- set_output(*, transform=None)[source]#
设置输出容器。
有关如何使用 API 的示例,请参阅引入 set_output API。
- 参数:
- transform{“default”, “pandas”, “polars”}, default=None
配置
transform和fit_transform的输出。"default": 转换器的默认输出格式"pandas": DataFrame 输出"polars": Polars 输出None: 转换配置保持不变
1.4 版本新增: 添加了
"polars"选项。
- 返回:
- selfestimator instance
估计器实例。
- set_params(**params)[source]#
设置此估计器的参数。
此方法适用于简单的估计器以及嵌套对象(如
Pipeline)。后者具有<component>__<parameter>形式的参数,以便可以更新嵌套对象的每个组件。- 参数:
- **paramsdict
估计器参数。
- 返回:
- selfestimator instance
估计器实例。
- transform(X)[source]#
Transform new points into embedding space.
- 参数:
- Xshape 为 (n_samples, n_features) 的 array-like
Training set.
- 返回:
- X_newndarray of shape (n_samples, n_components)
返回实例本身。
注意事项
Because of scaling performed by this method, it is discouraged to use it together with methods that are not scale-invariant (like SVMs).