DBSCAN#
- class sklearn.cluster.DBSCAN(eps=0.5, *, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)[source]#
从向量数组或距离矩阵执行 DBSCAN 聚类。
DBSCAN - Density-Based Spatial Clustering of Applications with Noise. Finds core samples of high density and expands clusters from them. This algorithm is particularly good for data which contains clusters of similar density and can find clusters of arbitrary shape.
Unlike K-means, DBSCAN does not require specifying the number of clusters in advance and can identify outliers as noise points.
This implementation has a worst case memory complexity of \(O({n}^2)\), which can occur when the
epsparam is large andmin_samplesis low, while the original DBSCAN only uses linear memory. For further details, see the Notes below.Read more in the User Guide.
- 参数:
- epsfloat, default=0.5
The maximum distance between two samples for one to be considered as in the neighborhood of the other. This is not a maximum bound on the distances of points within a cluster. This is the most important DBSCAN parameter to choose appropriately for your data set and distance function. Smaller values generally lead to more clusters.
- min_samplesint, default=5
The number of samples (or total weight) in a neighborhood for a point to be considered as a core point. This includes the point itself. If
min_samplesis set to a higher value, DBSCAN will find denser clusters, whereas if it is set to a lower value, the found clusters will be more sparse.- metricstr, or callable, default=’euclidean’
The metric to use when calculating distance between instances in a feature array. If metric is a string or callable, it must be one of the options allowed by
sklearn.metrics.pairwise_distancesfor its metric parameter. If metric is “precomputed”, X is assumed to be a distance matrix and must be square. X may be a sparse graph, in which case only “nonzero” elements may be considered neighbors for DBSCAN.Added in version 0.17: metric precomputed to accept precomputed sparse matrix.
- metric_paramsdict, default=None
度量函数的附加关键字参数。
Added in version 0.19.
- algorithm{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’
The algorithm to be used by the NearestNeighbors module to compute pointwise distances and find nearest neighbors. ‘auto’ will attempt to decide the most appropriate algorithm based on the values passed to
fitmethod. SeeNearestNeighborsdocumentation for details.- leaf_sizeint, default=30
Leaf size passed to BallTree or cKDTree. This can affect the speed of the construction and query, as well as the memory required to store the tree. The optimal value depends on the nature of the problem.
- pfloat, default=None
The power of the Minkowski metric to be used to calculate distance between points. If None, then
p=2(equivalent to the Euclidean distance). When p=1, this is equivalent to Manhattan distance.- n_jobsint, default=None
The number of parallel jobs to run.
Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors. See Glossary for more details.
- 属性:
- core_sample_indices_ndarray of shape (n_core_samples,)
Indices of core samples.
- components_ndarray of shape (n_core_samples, n_features)
Copy of each core sample found by training.
- labels_ndarray of shape (n_samples,)
Cluster labels for each point in the dataset given to fit(). Noisy samples are given the label -1. Non-negative integers indicate cluster membership.
- n_features_in_int
在 拟合 期间看到的特征数。
0.24 版本新增。
- feature_names_in_shape 为 (
n_features_in_,) 的 ndarray 在 fit 期间看到的特征名称。仅当
X具有全部为字符串的特征名称时才定义。1.0 版本新增。
另请参阅
OPTICSA similar clustering at multiple values of eps. Our implementation is optimized for memory usage.
注意事项
This implementation bulk-computes all neighborhood queries, which increases the memory complexity to O(n.d) where d is the average number of neighbors, while original DBSCAN had memory complexity O(n). It may attract a higher memory complexity when querying these nearest neighborhoods, depending on the
algorithm.One way to avoid the query complexity is to pre-compute sparse neighborhoods in chunks using
NearestNeighbors.radius_neighbors_graphwithmode='distance', then usingmetric='precomputed'here.Another way to reduce memory and computation time is to remove (near-)duplicate points and use
sample_weightinstead.OPTICSprovides a similar clustering with lower memory usage.References
Ester, M., H. P. Kriegel, J. Sander, and X. Xu, “A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise”. In: Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, AAAI Press, pp. 226-231. 1996
Schubert, E., Sander, J., Ester, M., Kriegel, H. P., & Xu, X. (2017). “DBSCAN revisited, revisited: why and how you should (still) use DBSCAN.” ACM Transactions on Database Systems (TODS), 42(3), 19.
示例
>>> from sklearn.cluster import DBSCAN >>> import numpy as np >>> X = np.array([[1, 2], [2, 2], [2, 3], ... [8, 7], [8, 8], [25, 80]]) >>> clustering = DBSCAN(eps=3, min_samples=2).fit(X) >>> clustering.labels_ array([ 0, 0, 0, 1, 1, -1]) >>> clustering DBSCAN(eps=3, min_samples=2)
For an example, see Demo of DBSCAN clustering algorithm.
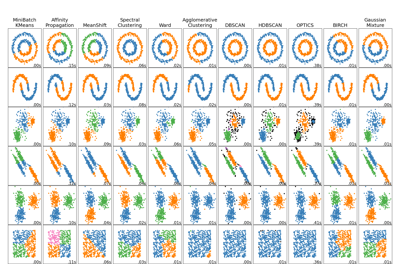
For a comparison of DBSCAN with other clustering algorithms, see Comparing different clustering algorithms on toy datasets
- fit(X, y=None, sample_weight=None)[source]#
Perform DBSCAN clustering from features, or distance matrix.
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features), or (n_samples, n_samples)
Training instances to cluster, or distances between instances if
metric='precomputed'. If a sparse matrix is provided, it will be converted into a sparsecsr_matrix.- y被忽略
Not used, present here for API consistency by convention.
- sample_weightshape 为 (n_samples,) 的 array-like, default=None
Weight of each sample, such that a sample with a weight of at least
min_samplesis by itself a core sample; a sample with a negative weight may inhibit its eps-neighbor from being core. Note that weights are absolute, and default to 1.
- 返回:
- selfobject
Returns a fitted instance of self.
- fit_predict(X, y=None, sample_weight=None)[source]#
Compute clusters from a data or distance matrix and predict labels.
This method fits the model and returns the cluster labels in a single step. It is equivalent to calling fit(X).labels_.
- 参数:
- X{array-like, sparse matrix} of shape (n_samples, n_features), or (n_samples, n_samples)
Training instances to cluster, or distances between instances if
metric='precomputed'. If a sparse matrix is provided, it will be converted into a sparsecsr_matrix.- y被忽略
Not used, present here for API consistency by convention.
- sample_weightshape 为 (n_samples,) 的 array-like, default=None
Weight of each sample, such that a sample with a weight of at least
min_samplesis by itself a core sample; a sample with a negative weight may inhibit its eps-neighbor from being core. Note that weights are absolute, and default to 1.
- 返回:
- labelsndarray of shape (n_samples,)
Cluster labels. Noisy samples are given the label -1. Non-negative integers indicate cluster membership.
- get_metadata_routing()[source]#
获取此对象的元数据路由。
请查阅 用户指南,了解路由机制如何工作。
- 返回:
- routingMetadataRequest
封装路由信息的
MetadataRequest。
- get_params(deep=True)[source]#
获取此估计器的参数。
- 参数:
- deepbool, default=True
如果为 True,将返回此估计器以及包含的子对象(如果它们是估计器)的参数。
- 返回:
- paramsdict
参数名称映射到其值。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') DBSCAN[source]#
配置是否应请求元数据以传递给
fit方法。请注意,此方法仅在以下情况下相关:此估计器用作 元估计器 中的子估计器,并且通过
enable_metadata_routing=True启用了元数据路由(请参阅sklearn.set_config)。请查看 用户指南 以了解路由机制的工作原理。每个参数的选项如下:
True:请求元数据,如果提供则传递给fit。如果未提供元数据,则忽略该请求。False:不请求元数据,元估计器不会将其传递给fit。None:不请求元数据,如果用户提供元数据,元估计器将引发错误。str:应将元数据以给定别名而不是原始名称传递给元估计器。
默认值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留现有请求。这允许您更改某些参数的请求而不更改其他参数。在版本 1.3 中新增。
- 参数:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
fit方法中sample_weight参数的元数据路由。
- 返回:
- selfobject
更新后的对象。