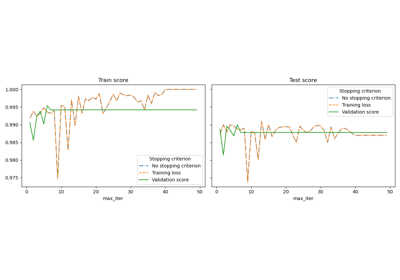
注意
转到末尾以下载完整示例代码或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
梯度提升中的早停#
梯度提升是一种集成技术,它结合多个弱学习器(通常是决策树)来创建强大而鲁棒的预测模型。它以迭代的方式进行,每个新阶段(树)都会纠正前一个阶段的错误。
早停是梯度提升中的一种技术,它允许我们找到构建一个能很好地泛化到未见数据并避免过拟合的模型所需的最佳迭代次数。其概念很简单:我们预留一部分数据集作为验证集(使用 validation_fraction 指定),以在训练期间评估模型的性能。随着模型通过额外的阶段(树)迭代构建,其在验证集上的性能会随着步数的增加而被监控。
当模型在验证集上的性能在连续一定数量的阶段(由 n_iter_no_change 指定)内趋于平稳或恶化(在由 tol 指定的偏差范围内)时,早停就会生效。这表明模型已经达到了一个点,进一步的迭代可能会导致过拟合,是时候停止训练了。
应用早停时,最终模型中的估计器(树)数量可以通过 n_estimators_ 属性访问。总的来说,早停是梯度提升中平衡模型性能和效率的宝贵工具。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
数据准备#
首先,我们加载并准备加州房价数据集用于训练和评估。它对数据集进行子集划分,并将其拆分为训练集和验证集。
import time
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
data = fetch_california_housing()
X, y = data.data[:600], data.target[:600]
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
模型训练和比较#
训练两个 GradientBoostingRegressor 模型:一个带有早停,另一个不带早停。目的是比较它们的性能。它还计算了训练时间以及两个模型使用的 n_estimators_。
params = dict(n_estimators=1000, max_depth=5, learning_rate=0.1, random_state=42)
gbm_full = GradientBoostingRegressor(**params)
gbm_early_stopping = GradientBoostingRegressor(
**params,
validation_fraction=0.1,
n_iter_no_change=10,
)
start_time = time.time()
gbm_full.fit(X_train, y_train)
training_time_full = time.time() - start_time
n_estimators_full = gbm_full.n_estimators_
start_time = time.time()
gbm_early_stopping.fit(X_train, y_train)
training_time_early_stopping = time.time() - start_time
estimators_early_stopping = gbm_early_stopping.n_estimators_
误差计算#
代码计算了上一节中训练的模型的训练集和验证集上的 mean_squared_error。它计算了每次提升迭代的误差。目的是评估模型的性能和收敛性。
train_errors_without = []
val_errors_without = []
train_errors_with = []
val_errors_with = []
for i, (train_pred, val_pred) in enumerate(
zip(
gbm_full.staged_predict(X_train),
gbm_full.staged_predict(X_val),
)
):
train_errors_without.append(mean_squared_error(y_train, train_pred))
val_errors_without.append(mean_squared_error(y_val, val_pred))
for i, (train_pred, val_pred) in enumerate(
zip(
gbm_early_stopping.staged_predict(X_train),
gbm_early_stopping.staged_predict(X_val),
)
):
train_errors_with.append(mean_squared_error(y_train, train_pred))
val_errors_with.append(mean_squared_error(y_val, val_pred))
可视化比较#
它包括三个子图
绘制两个模型在提升迭代过程中的训练误差。
绘制两个模型在提升迭代过程中的验证误差。
创建一个条形图,比较带有早停和不带有早停的模型的训练时间以及使用的估计器数量。
fig, axes = plt.subplots(ncols=3, figsize=(12, 4))
axes[0].plot(train_errors_without, label="gbm_full")
axes[0].plot(train_errors_with, label="gbm_early_stopping")
axes[0].set_xlabel("Boosting Iterations")
axes[0].set_ylabel("MSE (Training)")
axes[0].set_yscale("log")
axes[0].legend()
axes[0].set_title("Training Error")
axes[1].plot(val_errors_without, label="gbm_full")
axes[1].plot(val_errors_with, label="gbm_early_stopping")
axes[1].set_xlabel("Boosting Iterations")
axes[1].set_ylabel("MSE (Validation)")
axes[1].set_yscale("log")
axes[1].legend()
axes[1].set_title("Validation Error")
training_times = [training_time_full, training_time_early_stopping]
labels = ["gbm_full", "gbm_early_stopping"]
bars = axes[2].bar(labels, training_times)
axes[2].set_ylabel("Training Time (s)")
for bar, n_estimators in zip(bars, [n_estimators_full, estimators_early_stopping]):
height = bar.get_height()
axes[2].text(
bar.get_x() + bar.get_width() / 2,
height + 0.001,
f"Estimators: {n_estimators}",
ha="center",
va="bottom",
)
plt.tight_layout()
plt.show()
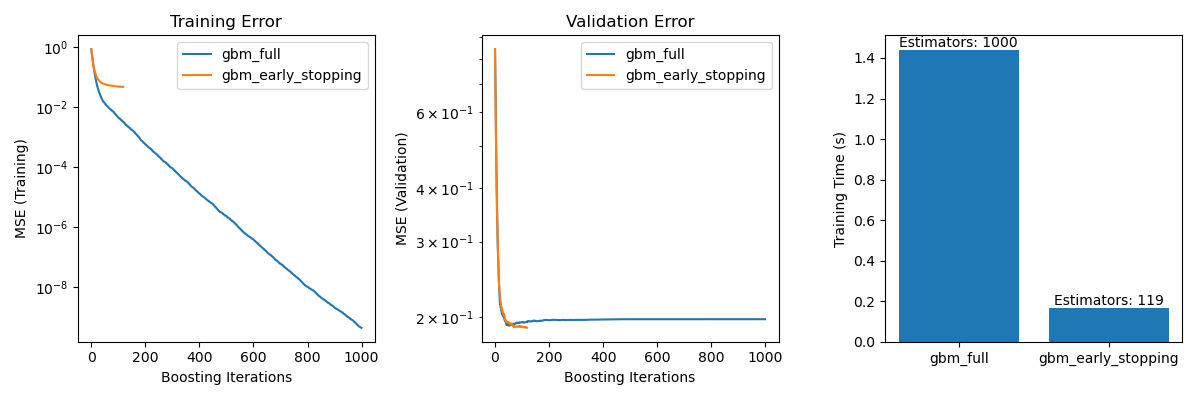
gbm_full 和 gbm_early_stopping 之间的训练误差差异源于 gbm_early_stopping 将 validation_fraction 的训练数据预留为内部验证集。早停是根据这个内部验证分数决定的。
总结#
在我们的示例中,使用加州房价数据集上的 GradientBoostingRegressor 模型,我们展示了早停的实际好处
防止过拟合: 我们展示了验证误差如何在某个点之后趋于稳定或开始增加,这表明模型对未见数据泛化得更好。这是通过在过拟合发生之前停止训练过程来实现的。
提高训练效率: 我们比较了带有早停和不带有早停的模型的训练时间。带有早停的模型在实现可比准确性的同时,需要的估计器数量明显减少,从而加快了训练速度。
脚本总运行时间: (0 minutes 2.422 seconds)
相关示例