注意
转到末尾 下载完整的示例代码或通过 JupyterLite 或 Binder 在浏览器中运行此示例。
岭系数作为 L2 正则化的函数#
过度拟合的模型会过度学习训练数据,不仅捕获了底层模式,还捕获了数据中的噪声。然而,当应用于未见过的数据时,所学的关联可能并不成立。当我们将训练好的预测应用于测试数据时,如果其统计性能与训练数据相比显着下降,我们通常会发现这种情况。
克服过度拟合的一种方法是正则化,这可以通过在线性模型中惩罚大权重(系数)来实现,迫使模型缩小所有系数。正则化减少了模型对从训练样本中获得的特定信息的依赖。
本例说明了 Ridge 回归中的 L2 正则化如何通过向损失中添加一个惩罚项来影响模型的性能,该惩罚项随着系数 \(\beta\) 的增加而增加。
正则化损失函数如下所示:\(\mathcal{L}(X, y, \beta) = \| y - X \beta \|^{2}_{2} + \alpha \| \beta \|^{2}_{2}\)
其中 \(X\) 是输入数据,\(y\) 是目标变量,\(\beta\) 是与特征相关的系数向量,\(\alpha\) 是正则化强度。
正则化损失函数旨在平衡准确预测训练集和防止过度拟合之间的权衡。
在此正则化损失中,左侧(例如 \(\|y - X\beta\|^{2}_{2}\))测量实际目标变量 \(y\) 与预测值之间的平方差。单独最小化此项可能导致过度拟合,因为模型可能变得过于复杂,对训练数据中的噪声过于敏感。
为了解决过度拟合问题,岭回归在损失函数中添加了一个约束,称为惩罚项(\(\alpha \| \beta\|^{2}_{2}\))。此惩罚项是模型系数平方和乘以正则化强度 \(\alpha\)。通过引入此约束,岭回归不鼓励任何单个系数 \(\beta_{i}\) 取过大的值,并鼓励系数更小且分布更均匀。较高的 \(\alpha\) 值会迫使系数趋向于零。然而,过高的 \(\alpha\) 可能导致模型欠拟合,无法捕获数据中的重要模式。
因此,正则化损失函数结合了预测准确性项和惩罚项。通过调整正则化强度,从业者可以微调对权重施加的约束程度,训练出能够很好地推广到未见数据的模型,同时避免过度拟合。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
本例的目的#
为了展示岭正则化如何工作,我们将创建一个无噪声数据集。然后,我们将在一系列正则化强度 (\(\alpha\)) 上训练正则化模型,并绘制训练系数以及这些系数与原始值之间的均方误差如何作为正则化强度的函数而变化。
创建无噪声数据集#
我们制作一个包含 100 个样本和 10 个特征的玩具数据集,适用于检测回归。在这 10 个特征中,有 8 个具有信息量并有助于回归,而其余 2 个特征对目标变量没有任何影响(它们的真实系数为 0)。请注意,在本例中数据是无噪声的,因此我们可以期望我们的回归模型能够精确恢复真实的系数 w。
from sklearn.datasets import make_regression
X, y, w = make_regression(
n_samples=100, n_features=10, n_informative=8, coef=True, random_state=1
)
# Obtain the true coefficients
print(f"The true coefficient of this regression problem are:\n{w}")
The true coefficient of this regression problem are:
[38.32634568 88.49665188 0. 29.75747153 0. 19.08699432
25.44381023 38.69892343 49.28808734 71.75949622]
训练岭回归器#
我们使用 Ridge,这是一个带有 L2 正则化的线性模型。我们训练多个模型,每个模型都有一个不同的模型参数 alpha 值,该参数是一个正常量,乘以惩罚项,控制正则化强度。对于每个训练好的模型,我们计算真实系数 w 与模型 clf 找到的系数之间的误差。我们将识别出的系数和计算出的误差存储在列表中,方便我们绘制它们。
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
clf = Ridge()
# Generate values for `alpha` that are evenly distributed on a logarithmic scale
alphas = np.logspace(-3, 4, 200)
coefs = []
errors_coefs = []
# Train the model with different regularisation strengths
for a in alphas:
clf.set_params(alpha=a).fit(X, y)
coefs.append(clf.coef_)
errors_coefs.append(mean_squared_error(clf.coef_, w))
绘制训练系数和均方误差#
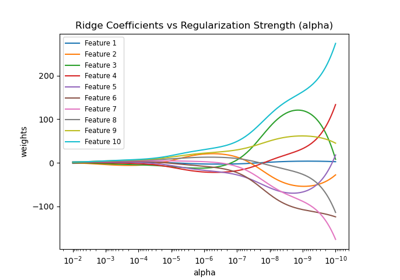
我们现在将 10 个不同的正则化系数作为正则化参数 alpha 的函数进行绘制,其中每种颜色代表一个不同的系数。
在右侧,我们绘制了估计器系数的误差如何作为正则化强度的函数而变化。
import matplotlib.pyplot as plt
import pandas as pd
alphas = pd.Index(alphas, name="alpha")
coefs = pd.DataFrame(coefs, index=alphas, columns=[f"Feature {i}" for i in range(10)])
errors = pd.Series(errors_coefs, index=alphas, name="Mean squared error")
fig, axs = plt.subplots(1, 2, figsize=(20, 6))
coefs.plot(
ax=axs[0],
logx=True,
title="Ridge coefficients as a function of the regularization strength",
)
axs[0].set_ylabel("Ridge coefficient values")
errors.plot(
ax=axs[1],
logx=True,
title="Coefficient error as a function of the regularization strength",
)
_ = axs[1].set_ylabel("Mean squared error")
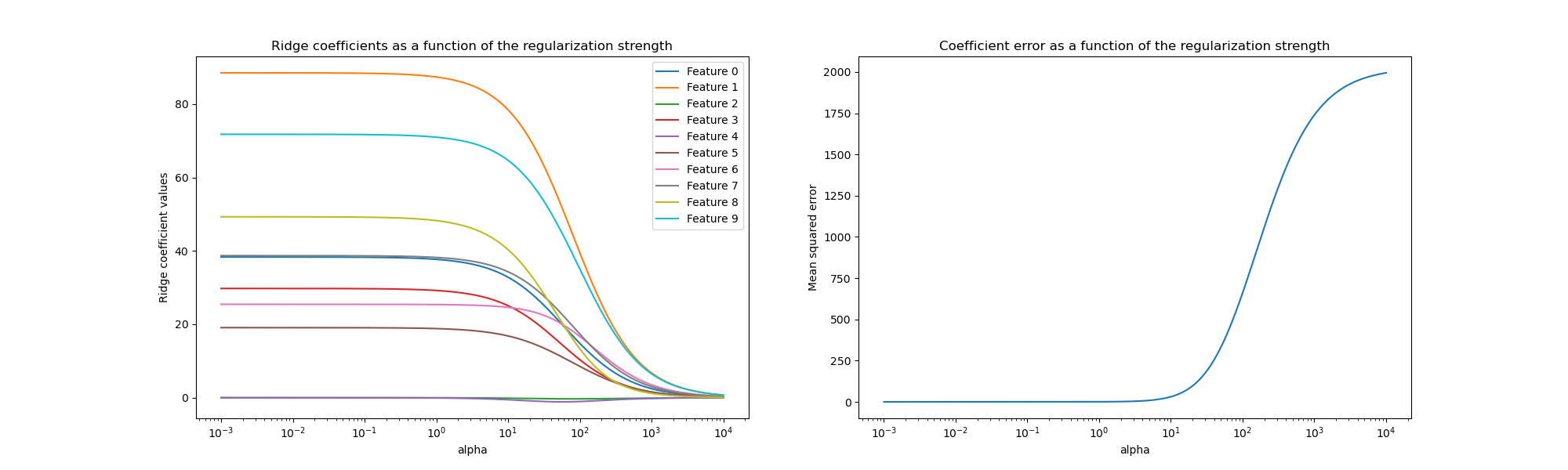
解释图表#
左侧图表显示了正则化强度 (alpha) 如何影响岭回归系数。较小的 alpha 值(弱正则化)允许系数与用于生成数据集的真实系数 (w) 非常相似。这是因为我们的人工数据集没有添加额外的噪声。随着 alpha 的增加,系数会向零收缩,逐渐减少以前更重要的特征的影响。
右侧图表显示了模型找到的系数与真实系数 (w) 之间的均方误差 (MSE)。它提供了一个衡量标准,用于衡量我们的岭模型与真实生成模型相比的精确程度。低误差意味着它找到的系数更接近真实生成模型的系数。在这种情况下,由于我们的玩具数据集是无噪声的,我们可以看到正则化最少的模型检索到的系数最接近真实系数 (w)(误差接近 0)。
当 alpha 很小时,模型会捕获训练数据的复杂细节,无论这些细节是由噪声还是实际信息引起的。随着 alpha 的增加,最高的系数收缩得更快,使得它们对应的特征在训练过程中影响较小。这可以增强模型推广到未见数据的能力(如果存在大量噪声需要捕获),但如果正则化变得太强而超过数据所包含的噪声量(如本例所示),则也存在性能下降的风险。
在数据通常包含噪声的现实场景中,选择合适的 alpha 值对于在过度拟合和欠拟合模型之间取得平衡至关重要。
在这里,我们看到 Ridge 添加了惩罚项给系数以对抗过度拟合。发生的另一个问题与训练数据集中存在异常值有关。异常值是与G其他观测值显着不同的数据点。具体而言,这些异常值会影响我们前面显示的损失函数的左侧项。其他一些线性模型被设计成对异常值具有鲁棒性,例如 HuberRegressor。您可以在 HuberRegressor vs Ridge on dataset with strong outliers 示例中了解更多信息。
脚本总运行时间: (0 minutes 0.571 seconds)
相关示例