跳至主要内容
返回顶部
Ctrl
+
K
安装
用户指南
API
示例
社区
更多
入门
发行历史
术语表
开发
常见问题
支持
相关项目
路线图
治理
关于我们
GitHub
选择版本
安装
用户指南
API
示例
社区
入门
发行历史
术语表
开发
常见问题
支持
相关项目
路线图
治理
关于我们
GitHub
选择版本
章节导航
发行亮点
scikit-learn 1.6 发行亮点
scikit-learn 1.5 发行亮点
scikit-learn 1.4 发行亮点
scikit-learn 1.3 发行亮点
scikit-learn 1.2 发行亮点
scikit-learn 1.1 发行亮点
scikit-learn 1.0 发行亮点
scikit-learn 0.24 发行亮点
scikit-learn 0.23 发行亮点
scikit-learn 0.22 发行亮点
双聚类
谱双聚类算法演示
谱共聚类算法演示
使用谱共聚类算法对文档进行双聚类
校准
分类器校准比较
概率校准曲线
三类分类的概率校准
分类器的概率校准
分类
分类器比较
带有协方差椭球的线性判别分析和二次判别分析
用于分类的正态、Ledoit-Wolf 和 OAS 线性判别分析
绘制分类概率
识别手写数字
聚类
手写数字数据上的 K 均值聚类演示
硬币图像上的结构化 Ward 层次聚类演示
均值漂移聚类算法演示
聚类性能评估中的偶然性调整
带结构和不带结构的凝聚聚类
使用不同度量的凝聚聚类
K-Means++ 初始化示例
二分 K 均值和正则 K 均值性能比较
比较 BIRCH 和 MiniBatchKMeans
比较玩具数据集上的不同聚类算法
比较玩具数据集上的不同层次聚类方法
比较 K 均值和 MiniBatchKMeans 聚类算法
DBSCAN 聚类算法演示
HDBSCAN 聚类算法演示
OPTICS 聚类算法演示
亲和传播聚类算法演示
K 均值假设的演示
K 均值初始化影响的经验评估
特征聚集
特征聚集与单变量选择
层次聚类:结构化与非结构化 Ward
归纳聚类
人脸部件字典的在线学习
绘制层次聚类树状图
将希腊硬币图片分割成区域
使用轮廓分析选择 KMeans 聚类的簇数
用于图像分割的谱聚类
数字的二维嵌入上的各种凝聚聚类
矢量量化示例
协方差估计
Ledoit-Wolf 与 OAS 估计
稳健协方差估计和马氏距离的相关性
稳健与经验协方差估计
收缩协方差估计:LedoitWolf 与 OAS 和最大似然
稀疏逆协方差估计
交叉分解
比较交叉分解方法
主成分回归与偏最小二乘回归
数据集示例
绘制随机生成的多分标签数据集
决策树
决策树回归
绘制在鸢尾花数据集上训练的决策树的决策面
使用成本复杂度剪枝后剪枝决策树
理解决策树结构
分解
使用 FastICA 进行盲源分离
鸢尾花数据集的 LDA 和 PCA 2D 投影比较
人脸数据集分解
因子分析(带旋转)以可视化模式
二维点云上的 FastICA
使用字典学习进行图像去噪
增量 PCA
核 PCA
使用概率 PCA 和因子分析 (FA) 进行模型选择
鸢尾花数据集上的主成分分析 (PCA)
使用预计算字典进行稀疏编码
开发估计器
__sklearn_is_fitted__
作为开发者 API
集成方法
梯度提升中的分类特征支持
使用堆叠组合预测器
比较随机森林和直方图梯度提升模型
比较随机森林和多输出元估计器
使用 AdaBoost 的决策树回归
梯度提升中的提前停止
树林的特征重要性
使用树集成进行特征变换
直方图梯度提升树中的特征
梯度提升包外估计
梯度提升回归
梯度提升正则化
使用完全随机树进行哈希特征变换
IsolationForest 示例
单调约束
多类 AdaBoosted 决策树
随机森林的包外误差
绘制 VotingClassifier 计算的类概率
绘制单个和投票回归预测
绘制 VotingClassifier 的决策边界
绘制在鸢尾花数据集上训练的树集成的决策面
梯度提升回归的预测区间
单个估计器与 Bagging:偏差-方差分解
两类 AdaBoost
基于真实世界数据集的示例
压缩感知:使用 L1 先验 (Lasso) 进行断层扫描重建
使用特征脸和 SVM 的人脸识别示例
使用核 PCA 进行图像去噪
时间序列预测的滞后特征
模型复杂度影响
文本文档的外部核心分类
真实数据集上的异常值检测
预测延迟
物种分布建模
与时间相关的特征工程
使用非负矩阵分解和潜在狄利克雷分配进行主题提取
可视化股票市场结构
维基百科主特征向量
特征选择
F 检验和互信息的比较
基于模型和顺序的特征选择
管道 ANOVA SVM
递归特征消除
带交叉验证的递归特征消除
单变量特征选择
冻结估计器
使用
FrozenEstimator
的示例
高斯混合模型
变分贝叶斯高斯混合的浓度先验类型分析
高斯混合的密度估计
GMM 初始化方法
GMM 协方差
高斯混合模型椭球
高斯混合模型选择
高斯混合模型正弦曲线
用于机器学习的高斯过程
高斯过程回归 (GPR) 估计数据噪声水平的能力
核岭回归和高斯过程回归的比较
使用高斯过程回归 (GPR) 预测莫纳洛阿数据集上的 CO2 水平
高斯过程回归:基本入门示例
鸢尾花数据集上的高斯过程分类 (GPC)
离散数据结构上的高斯过程
XOR 数据集上高斯过程分类 (GPC) 的图示
不同核的先验和后验高斯过程的图示
高斯过程分类 (GPC) 的等概率线
使用高斯过程分类 (GPC) 进行概率预测
广义线性模型
比较线性贝叶斯回归器
比较各种在线求解器
使用贝叶斯岭回归进行曲线拟合
多项式和一对多逻辑回归的决策边界
随机梯度下降的提前停止
使用预计算的Gram矩阵和加权样本拟合弹性网络
在具有强异常值的数据集上比较HuberRegressor和Ridge
使用多任务Lasso进行联合特征选择
逻辑回归中的L1惩罚和稀疏性
基于L1的稀疏信号模型
通过信息准则进行Lasso模型选择
Lasso模型选择:AIC-BIC/交叉验证
在稠密和稀疏数据上使用Lasso
Lasso、Lasso-LARS和弹性网络路径
逻辑函数
使用多项式逻辑回归+L1进行MNIST分类
在20newgroups上进行多类别稀疏逻辑回归
非负最小二乘法
使用随机梯度下降的一类SVM与一类SVM的比较
普通最小二乘法示例
普通最小二乘法和岭回归方差
正交匹配追踪
绘制岭系数作为正则化的函数
在iris数据集上绘制多类别SGD
泊松回归和非正态损失
多项式和样条插值
分位数回归
L1逻辑回归的正则化路径
岭系数作为L2正则化的函数
稳健线性估计器拟合
使用RANSAC进行稳健线性模型估计
SGD:最大间隔分离超平面
SGD:惩罚项
SGD:加权样本
SGD:凸损失函数
Theil-Sen回归
对保险索赔进行Tweedie回归
检验
线性模型系数解释中的常见陷阱
机器学习推断因果效应的失败
偏依赖和个体条件期望图
置换重要性与随机森林特征重要性(MDI)的比较
具有多重共线性或相关特征的置换重要性
核近似
使用多项式核近似进行可扩展学习
流形学习
流形学习方法的比较
在断裂球体上的流形学习方法
手写数字上的流形学习:局部线性嵌入、Isomap……
多维缩放
瑞士卷和瑞士洞减少
t-SNE:不同困惑度值对形状的影响
其他
使用偏依赖进行高级绘图
比较用于玩具数据集异常值检测的异常检测算法
核岭回归和SVR的比较
显示管道
显示估计器和复杂的管道
异常检测估计器的评估
RBF核的显式特征映射近似
使用多输出估计器进行人脸补全
介绍
set_output
API
等度回归
元数据路由
多标签分类
使用可视化API绘制ROC曲线
使用随机投影嵌入的Johnson-Lindenstrauss界限
使用显示对象进行可视化
缺失值填补
在构建估计器之前填补缺失值
使用迭代填补的变体填补缺失值
模型选择
平衡模型复杂度和交叉验证得分
类似然比用于衡量分类性能
比较用于超参数估计的随机搜索和网格搜索
网格搜索和连续减半的比较
混淆矩阵
使用交叉验证的网格搜索的自定义重拟合策略
演示cross_val_score和GridSearchCV上的多指标评估
检测误差权衡(DET)曲线
模型正则化对训练和测试误差的影响
多类别接收者操作特征(ROC)
嵌套与非嵌套交叉验证
绘制交叉验证预测
绘制学习曲线并检查模型的可扩展性
事后调整决策函数的截止点
为成本敏感学习调整决策阈值
精确率-召回率
使用交叉验证的接收者操作特征(ROC)
文本特征提取和评估的示例管道
使用网格搜索对模型进行统计比较
连续减半迭代
使用置换检验分类得分的显著性
欠拟合与过拟合
可视化scikit-learn中的交叉验证行为
多类别方法
多类别训练元估计器的概述
多输出方法
使用分类器链进行多标签分类
最近邻
TSNE中的近似最近邻
缓存最近邻
比较使用和不使用邻域成分分析的最近邻
使用邻域成分分析进行降维
物种分布的核密度估计
核密度估计
最近质心分类
最近邻分类
最近邻回归
邻域成分分析图示
使用局部异常因子(LOF)进行新颖性检测
使用局部异常因子(LOF)进行异常值检测
简单的1D核密度估计
神经网络
比较MLPClassifier的随机学习策略
用于数字分类的受限玻尔兹曼机特征
改变多层感知器中的正则化
在MNIST上可视化MLP权重
管道和组合估计器
具有异构数据源的列转换器
具有混合类型的列转换器
连接多个特征提取方法
转换回归模型中的目标变量的影响
管道:连接PCA和逻辑回归
使用Pipeline和GridSearchCV选择降维
预处理
比较不同缩放器对异常值数据的的影响
比较目标编码器和其他编码器
演示KBinsDiscretizer的不同策略
特征离散化
特征缩放的重要性
将数据映射到正态分布
目标编码器的内部交叉拟合
使用KBinsDiscretizer离散化连续特征
半监督分类
在Iris数据集上比较半监督分类器与SVM的决策边界
改变自训练阈值的影响
标签传播数字主动学习
标签传播数字:演示性能
标签传播学习复杂结构
文本数据集上的半监督分类
支持向量机
使用非线性核(RBF)的一类SVM
使用不同的SVM核绘制分类边界
在iris数据集上绘制不同的SVM分类器
在LinearSVC中绘制支持向量
RBF SVM参数
SVM边距示例
SVM平局示例
带自定义核的SVM
SVM-Anova:具有单变量特征选择的SVM
SVM:最大间隔分离超平面
SVM:不平衡类别的分离超平面
SVM:加权样本
缩放SVC的正则化参数
使用线性和非线性核的支持向量回归(SVR)
教程练习
糖尿病数据集交叉验证练习
数字分类练习
支持向量机 (SVM) 练习
文本文档处理
使用稀疏特征进行文本文档分类
使用k-means聚类文本文档
FeatureHasher和DictVectorizer比较
示例
教程练习
教程练习
#
教程练习题
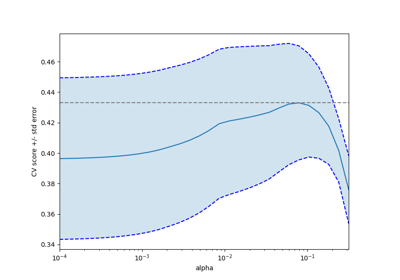
糖尿病数据集交叉验证练习
糖尿病数据集交叉验证练习
数字分类练习
数字分类练习
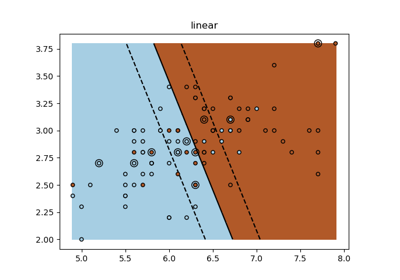
支持向量机 (SVM) 练习
支持向量机 (SVM) 练习