使用并行树林的像素重要性#
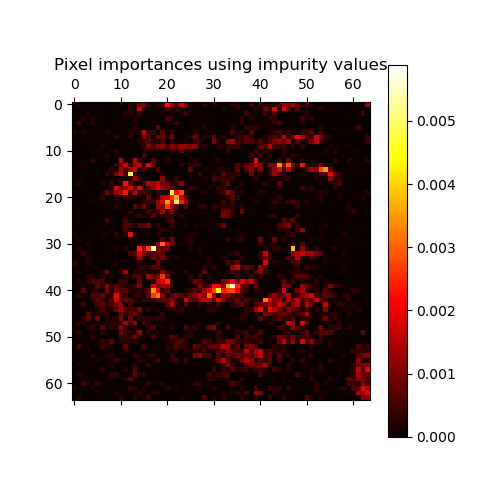
此示例展示了如何使用树林来评估人脸数据集图像分类任务中像素的重要性(基于杂质)。像素越热,它就越重要。
下面的代码还说明了如何在多个作业中并行构建和计算预测。
加载数据和模型拟合#
首先,我们加载 olivetti 人脸数据集,并将数据集限制为仅包含前五个类别。然后,我们在数据集上训练一个随机森林,并评估基于杂质的特征重要性。这种方法的一个缺点是它不能在单独的测试集上进行评估。对于此示例,我们感兴趣的是表示从完整数据集中学习到的信息。此外,我们将设置用于任务的核心数。
from sklearn.datasets import fetch_olivetti_faces
我们选择用于执行森林模型并行拟合的核心数。-1 表示使用所有可用的核心。
n_jobs = -1
加载人脸数据集
data = fetch_olivetti_faces()
X, y = data.data, data.target
将数据集限制为 5 个类别。
mask = y < 5
X = X[mask]
y = y[mask]
将拟合随机森林分类器以计算特征重要性。
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=750, n_jobs=n_jobs, random_state=42)
forest.fit(X, y)
基于平均杂质减少 (MDI) 的特征重要性#
特征重要性由拟合属性 feature_importances_ 提供,它们计算为每棵树内杂质减少累积的均值和标准差。
警告
对于**高基数**特征(许多唯一值),基于杂质的特征重要性可能会产生误导。请参阅排列特征重要性作为替代方案。
import time
import matplotlib.pyplot as plt
start_time = time.time()
img_shape = data.images[0].shape
importances = forest.feature_importances_
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
imp_reshaped = importances.reshape(img_shape)
plt.matshow(imp_reshaped, cmap=plt.cm.hot)
plt.title("Pixel importances using impurity values")
plt.colorbar()
plt.show()
Elapsed time to compute the importances: 0.150 seconds
你还能认出一张脸吗?
MDI 的局限性对于此数据集来说不是问题,因为
所有特征都是(有序的)数字,因此不会受到基数偏差的影响
我们只对表示在训练集上获得的森林知识感兴趣。
如果不满足这两个条件,建议改用 permutation_importance。
**脚本总运行时间:**(0 分 1.600 秒)
相关示例